Data_Wrangling_Project
تفاصيل العمل
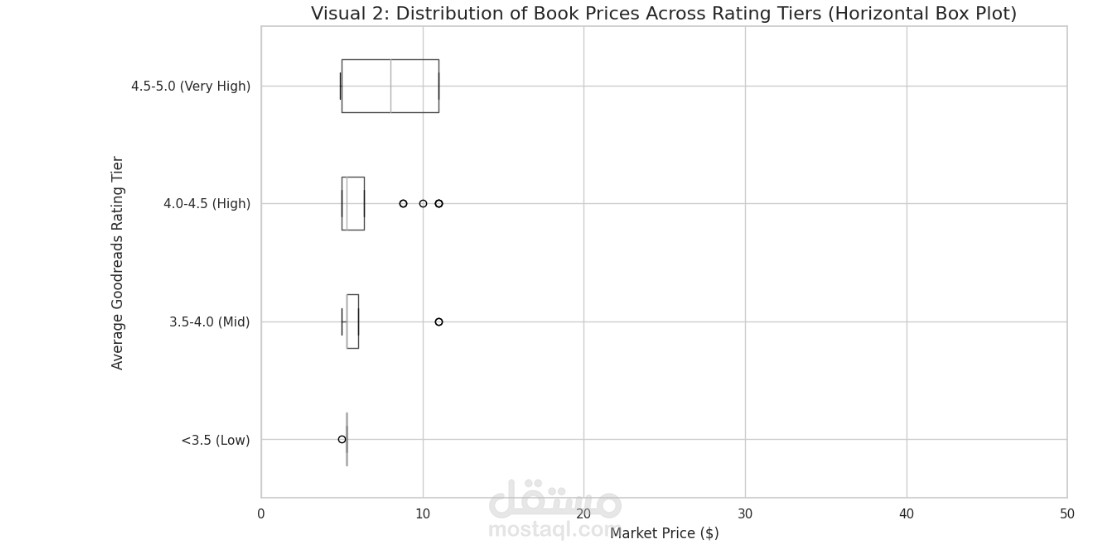
I worked on a real-world data wrangling project that involved collecting, cleaning, merging, and analyzing two book-related datasets: a Goodreads dataset with reader ratings and a bookstore dataset with book prices. Using Python and Pandas, I assessed data quality issues, cleaned invalid and missing values, standardized column names, and combined both datasets to explore the relationship between book ratings and market prices over publication years. The project also included creating visualizations to present findings and documenting all cleaning and analysis decisions clearly.