Data Cleaning
تفاصيل العمل
1. طبيعة المشكلة (The Challenge)
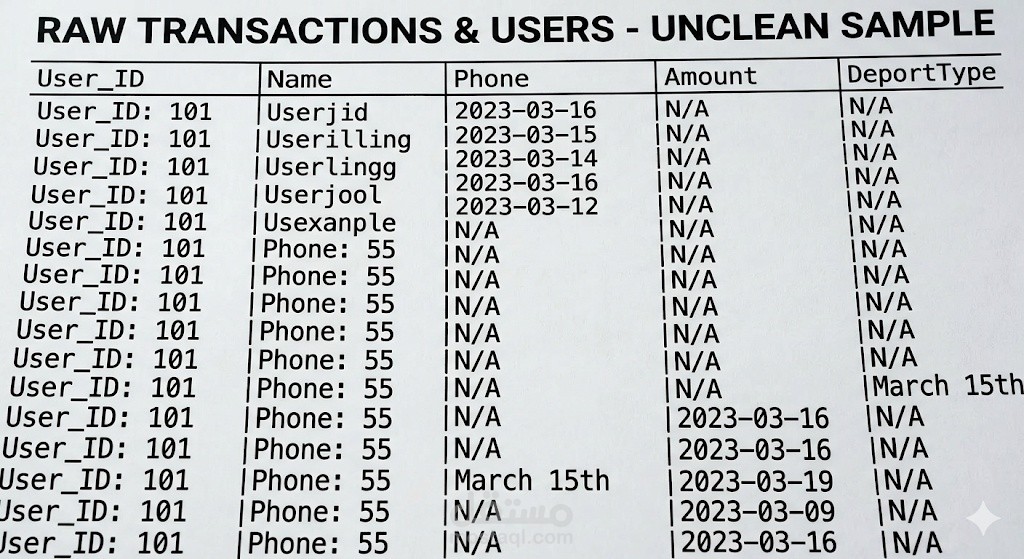
البيانات الأصلية في الصورة تُسمى "بيانات غير مهيكلة أو ملوثة" (Dirty Data)، وتظهر فيها المشاكل التالية:
تداخل الأعمدة (Column Misalignment): التواريخ موجودة في خانة الهاتف (Phone) وأحياناً في خانة المبلغ (Amount).
بيانات غير ضرورية (Noise): تكرار كلمة User_ID: داخل الخلايا بدلاً من وجود الرقم فقط.
تنسيقات غير موحدة: التاريخ مكتوب مرة بصيغة (2023-03-16) ومرة أخرى بصيغة نصية (March 15th).
قيم مفقودة: وجود كلمة N/A بكثرة نتيجة زحف البيانات لليمين أو اليسار.
2. ماذا يفعل الكود؟ (The Solution)
يقوم الكود بتحويل هذا "الفوضى" إلى جدول منظم وقابل للتحليل من خلال 4 مراحل أساسية:
التجريد (Extraction): استخراج الأرقام فقط من خانة المعرف (ID) والتخلص من النصوص الزائدة.
المحاذاة الأفقية (Horizontal Alignment): الكود ذكي بما يكفي ليبحث عن التاريخ في كل الأعمدة (Phone, Amount, DeportType) ويجمعه في عمود واحد صحيح، لأن التاريخ "هرب" من مكانه الأصلي.
التوحيد القياسي (Standardization): تحويل النصوص مثل "March 15th" إلى صيغة تاريخ رقمية يفهمها الكمبيوتر (2023-03-15).
التصفية (Filtering): تمييز الأسماء الحقيقية عن النصوص التوضيحية (مثل "Phone: 55") ووضع كل معلومة في مكانها الصحيح.
3. الفائدة النهائية (The Value)
بعد تشغيل هذا الكود، تتحول البيانات من مجرد "نص مصور" غير مفيد إلى قاعدة بيانات جاهزة لـ:
التحليل الإحصائي: معرفة عدد العمليات لكل مستخدم.
التمثيل البياني: رسم مخططات زمنية للتعاملات بناءً على التواريخ التي تم إصلاحها.
التخزين: إدخال البيانات في نظام (SQL) أو برنامج (Excel) بشكل احترافي.
4. الأدوات المستخدمة
Pandas: المكتبة الأقوى في لغة بايثون لتحليل وتعديل الجداول.
Regex (Regular Expressions): لغة برمجية مصغرة تستخدم لتمشيط النصوص واستخراج أنماط معينة (مثل استخراج الأرقام من وسط الكلام).