تجهيز البيانات باستخدام Standardization وNormalization لتحسين أداء النماذج
تفاصيل العمل
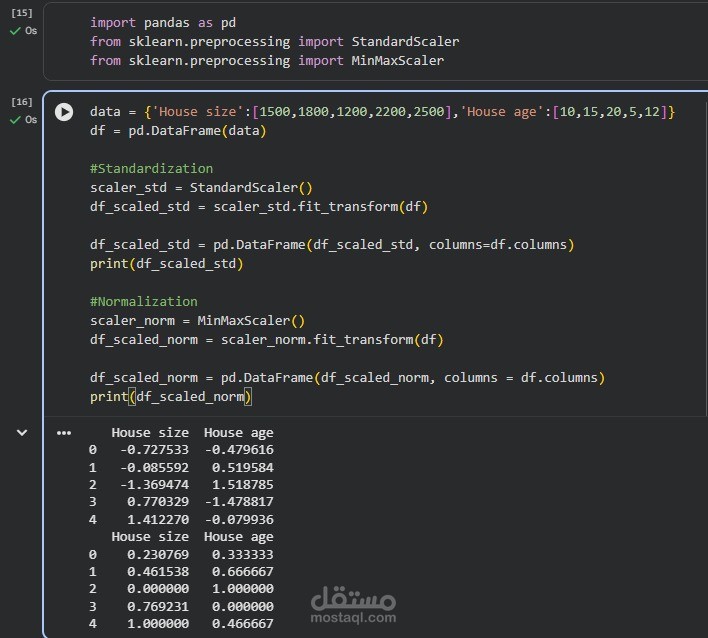
في هذا المشروع قمت بتنفيذ مرحلة مهمة من مراحل معالجة البيانات (Data Preprocessing) وهي Standardization وNormalization بهدف تحسين جودة البيانات ورفع كفاءة نماذج تعلم الآلة.
بدأت بتحليل البيانات للتأكد من اختلاف المقاييس بين الخصائص (Features)، ثم قمت بتطبيق:
Standardization (Z-score Scaling): حيث تم تحويل البيانات بحيث يكون المتوسط = 0 والانحراف المعياري = 1، مما يساعد النماذج التي تعتمد على المسافات مثل Logistic Regression وSVM على الأداء بشكل أفضل.
Normalization (Min-Max Scaling): حيث تم تحويل القيم إلى نطاق محدد (عادة من 0 إلى 1)، مما يسهل مقارنة القيم المختلفة ويمنع تأثير القيم الكبيرة على النموذج.
قمت بمقارنة النتائج قبل وبعد عملية التحجيم باستخدام الرسوم البيانية لفهم تأثير كل تقنية على توزيع البيانات.
هذا العمل ساعد في تحسين استقرار النموذج وتسريع عملية التدريب، بالإضافة إلى تقليل تأثير القيم المتطرفة (Outliers) وتحقيق نتائج أكثر دقة.