نظام ذكاء اصطناعي متكامل للتنبؤ بتكاليف التأمين الطبي السنوية بناءً على بيانات المريض.
تفاصيل العمل

مشروع متكامل من البداية للنهاية لبناء نموذج ذكاء اصطناعي يتنبأ
بتكاليف التأمين الطبي السنوية بناءً على بيانات المريض.
البنية التقنية للمشروع:
المشروع مبني بهيكل احترافي قابل للتطوير يشمل:
معالجة البيانات، تدريب النماذج، التقييم، الحفظ، والتنبؤ — كل
خطوة في ملف مستقل ضمن حزمة src/ منظمة.
النماذج والدقة:
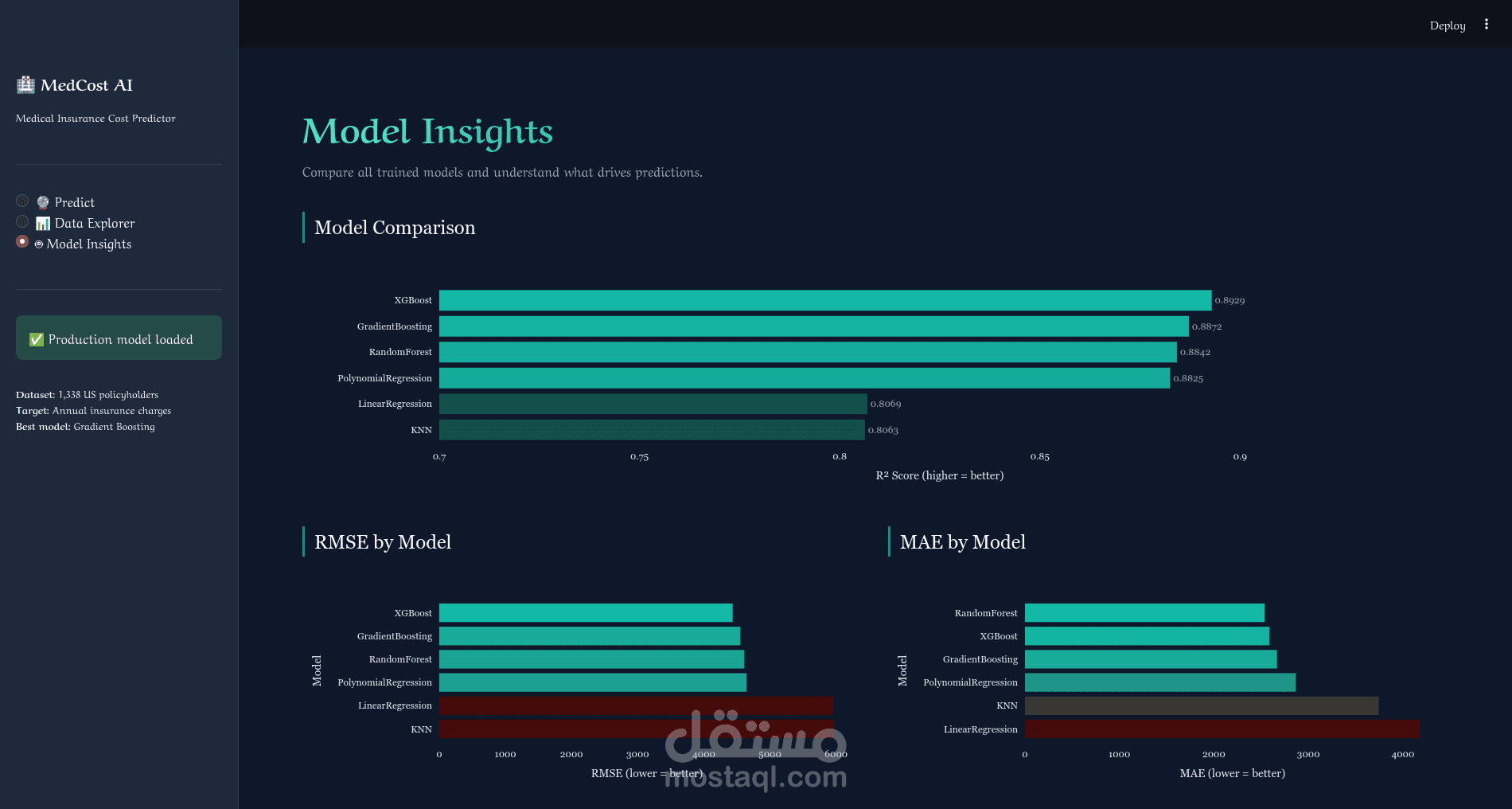
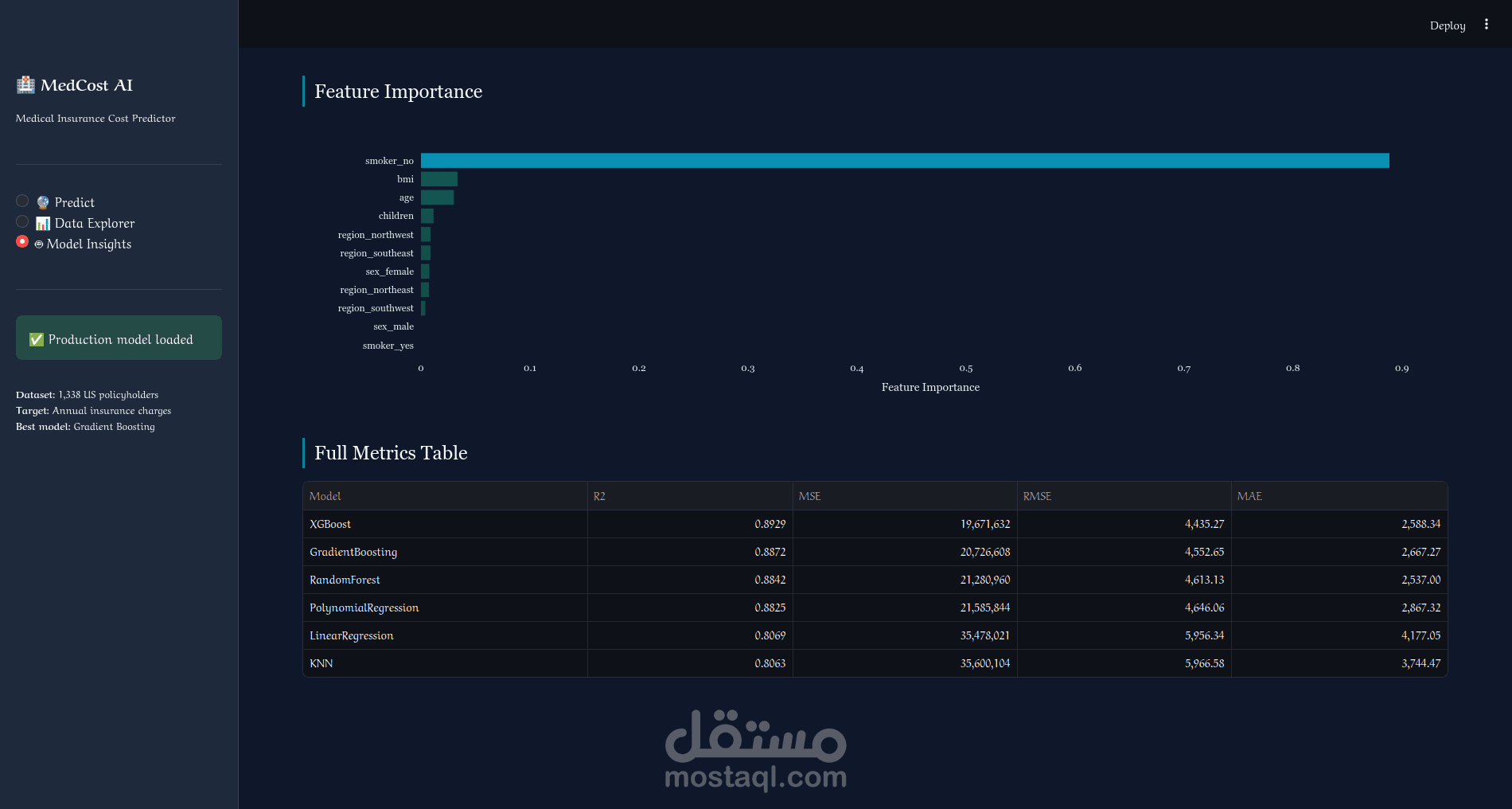
تم تدريب ومقارنة 6 نماذج تعلم آلي مختلفة:
- Gradient Boosting ← أفضل نموذج بدقة R² = 87.89%
- XGBoost ← R² = 85.54%
- Random Forest ← R² = 86.06%
- Polynomial Regression
- KNN
- Linear Regression
مع قياس MSE و RMSE و MAE لكل نموذج وحفظ أفضلها تلقائياً.
لوحة التحكم التفاعلية (Streamlit):
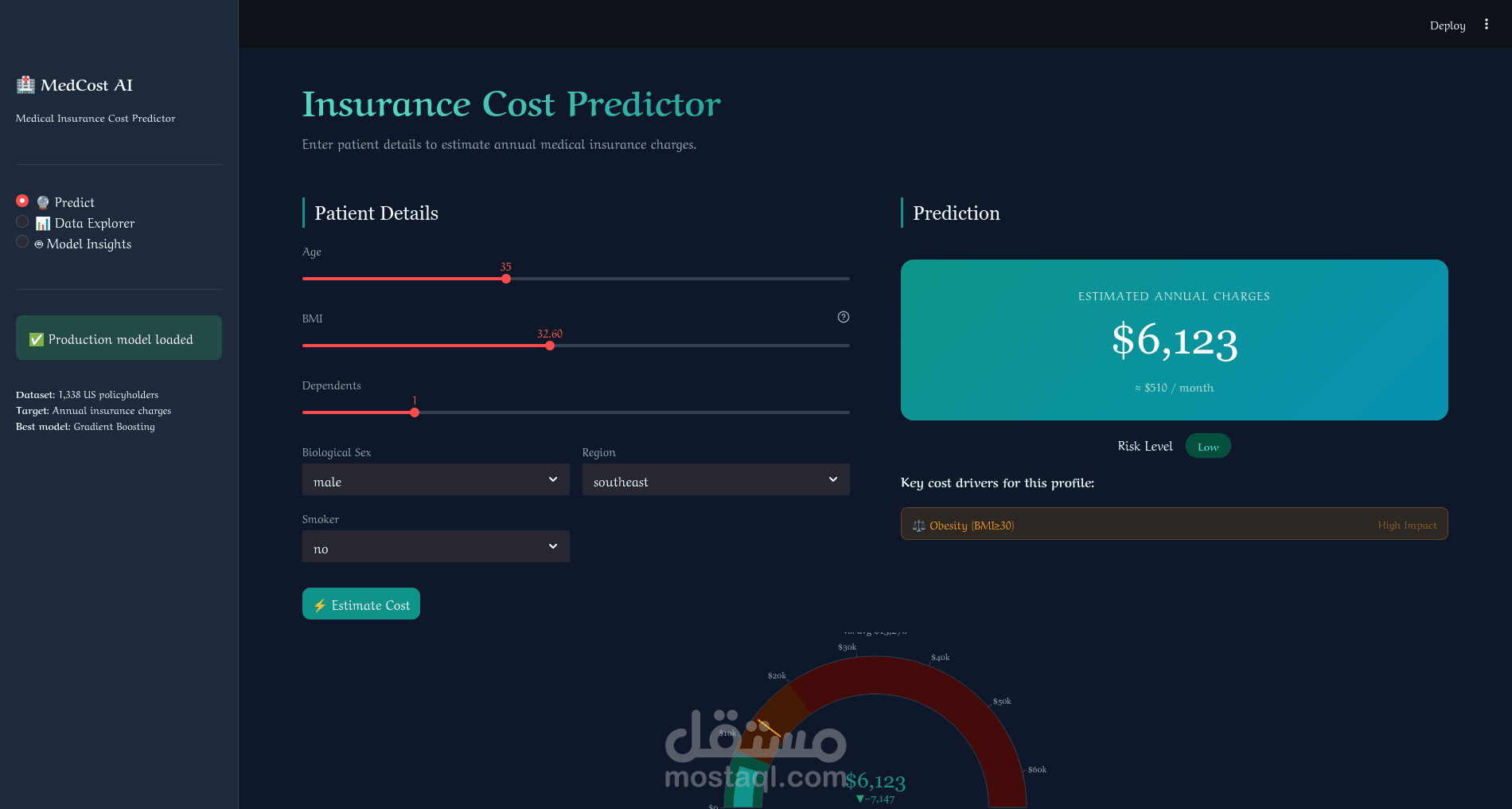
- صفحة التنبؤ: يُدخل المستخدم بياناته ويحصل فوراً على التكلفة المتوقعة مع مستوى الخطر (منخفض / متوسط / مرتفع) ومقياس مقارنة بالمتوسط العام
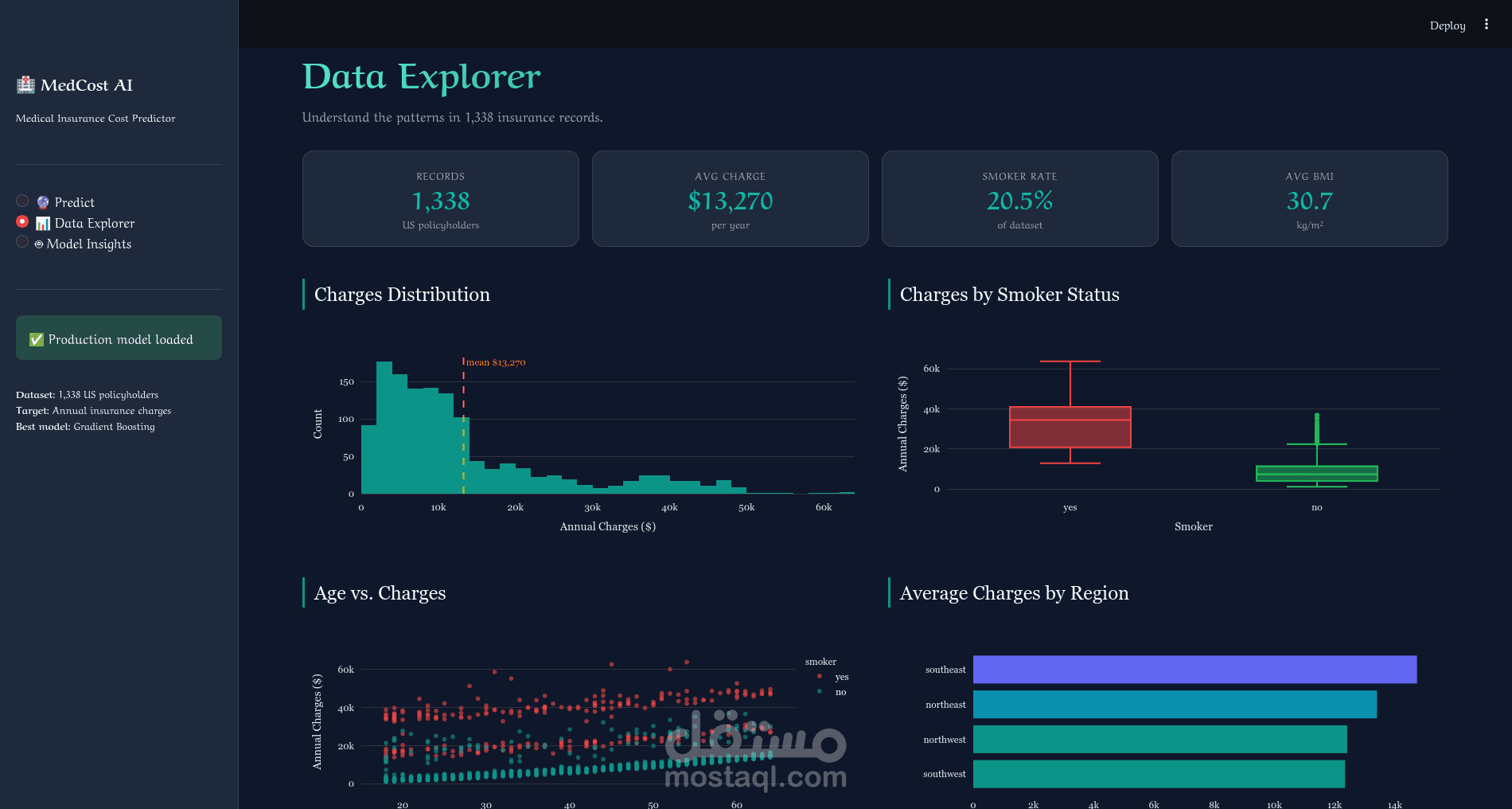
- صفحة استكشاف البيانات: رسوم بيانية تفاعلية توضح توزيع التكاليف وتأثير التدخين والعمر ومؤشر كتلة الجسم
- صفحة تقييم النماذج: مقارنة شاملة بين جميع النماذج بالأرقام والرسوم البيانية
المهارات التقنية المستخدمة:
تعلم الآلة — علم البيانات
Python — Scikit-learn — XGBoost — Pandas — NumPy
Streamlit — Plotly
جودة الكود:
- 7 اختبارات آلية تعمل مع كل تحديث على GitHub
- نظام logging لتتبع كل خطوة في Pipeline
- ملف config مركزي لإدارة جميع الإعدادات
- CLI tool للتنبؤ من سطر الأوامر