نظام ذكاء اصطناعي للكشف عن البريد المزعج
تفاصيل العمل

نظام متكامل لتصنيف الرسائل الإلكترونية والنصية إلى (سبام / طبيعي) باستخدام تقنيات معالجة اللغة الطبيعية والتعلم الآلي.
أبرز ما يتضمنه المشروع:
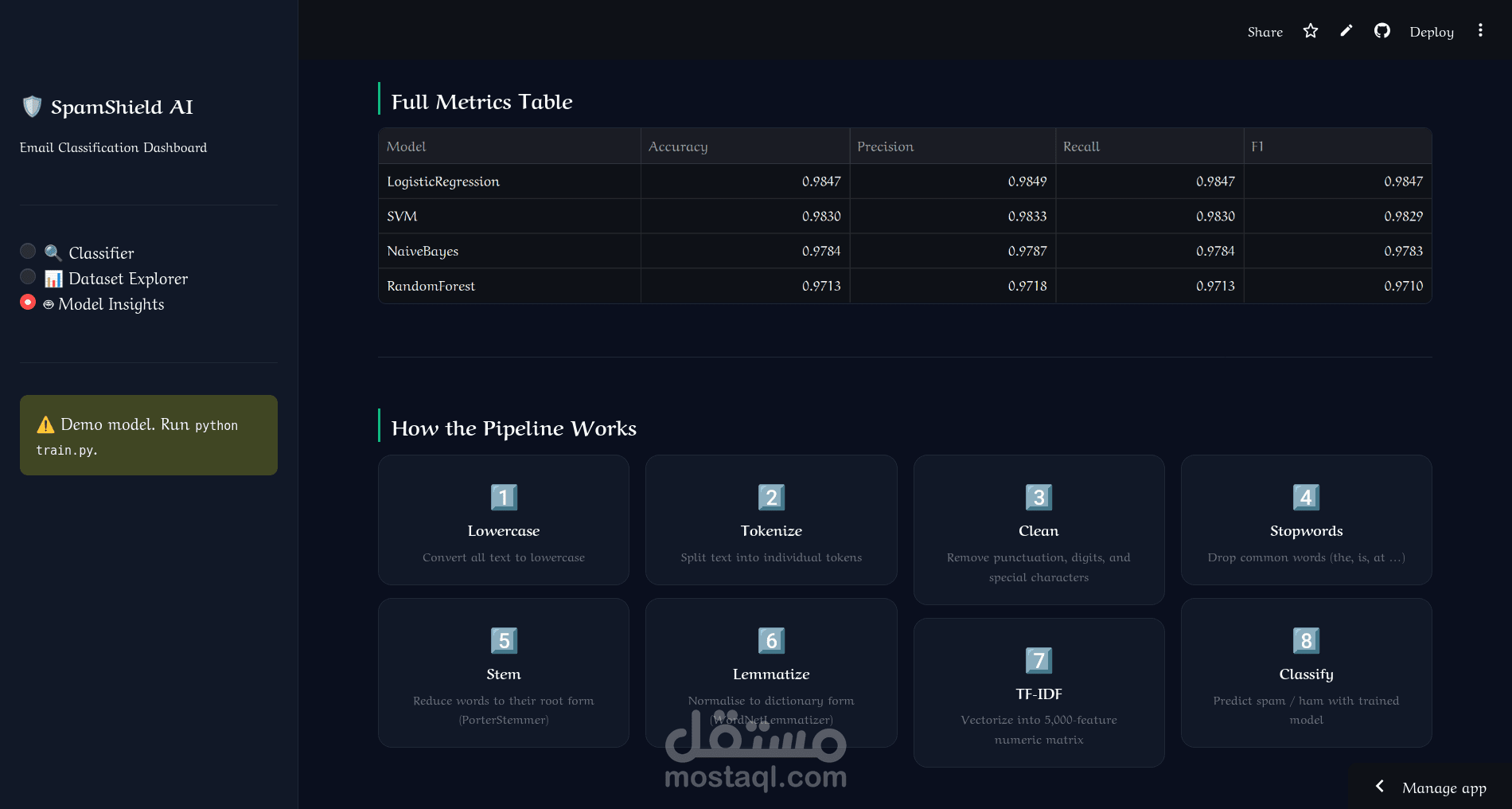
تعلم آلي متقدم — تدريب ومقارنة 4 نماذج: Naive Bayes، Logistic Regression، SVM، Random Forest بدقة تصل إلى 98.5%
خط معالجة NLP كامل — تحويل النصوص إلى أحرف صغيرة، التحليل الصرفي (Tokenization)، حذف الكلمات الشائعة، Stemming، Lemmatization، ثم تحويلها إلى متجهات TF-IDF
لوحة تحكم تفاعلية (Streamlit) — تتضمن 3 صفحات:
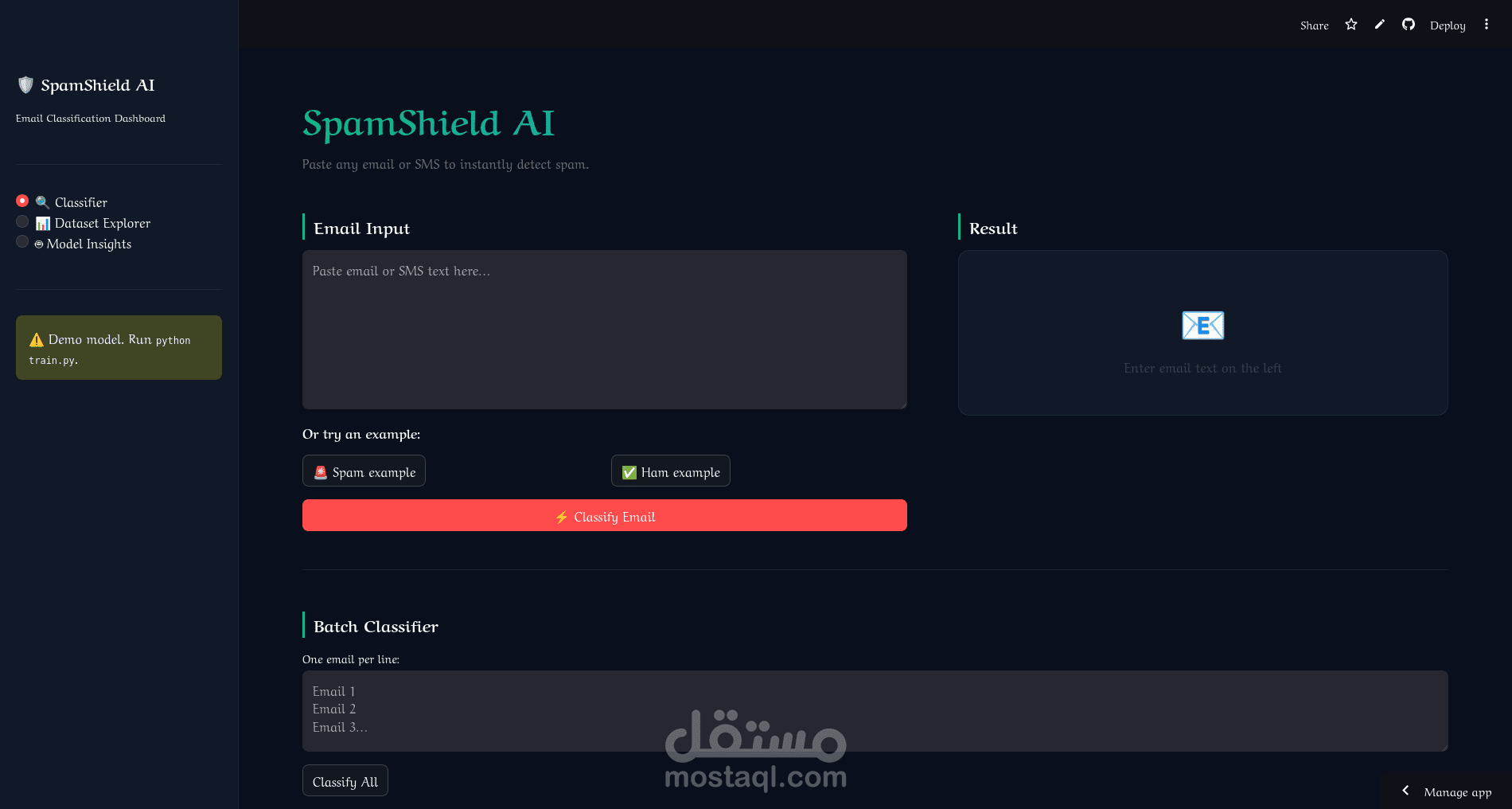
تصنيف الرسائل فردياً أو دفعةً واحدة مع مؤشر الثقة
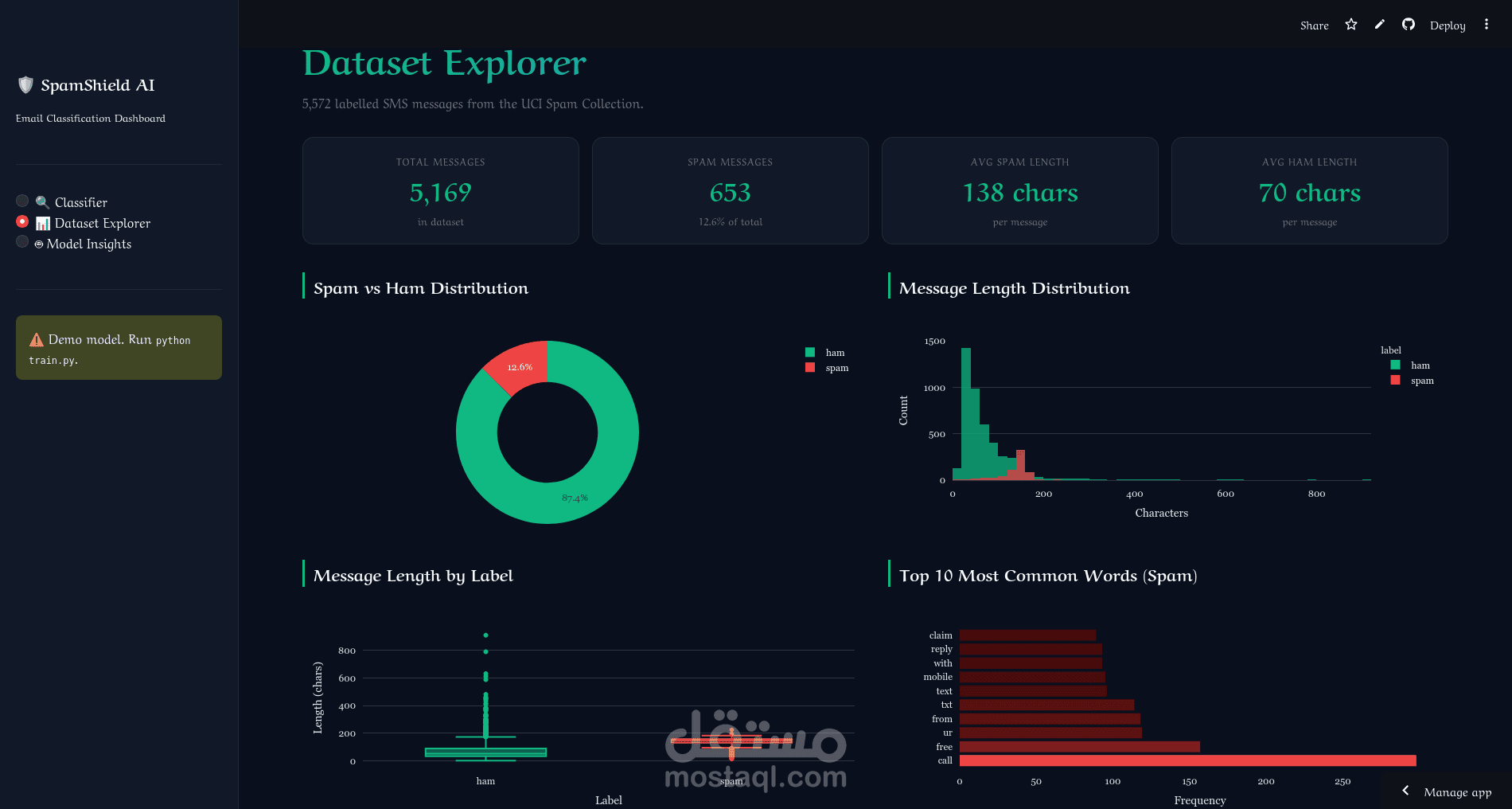
استكشاف البيانات بالرسوم البيانية
مقارنة أداء النماذج بمخططات رادار وأعمدة
بنية مشروع احترافية — كود منظم بمبدأ Separation of Concerns (src، config، logs)
سهل التخصيص والتوسعة — إضافة نماذج جديدة أو تغيير الإعدادات عبر ملف config.py