NYC Taxi Trips ETL Pipeline باستخدام PySpark و SQL Server و Power BI
تفاصيل العمل
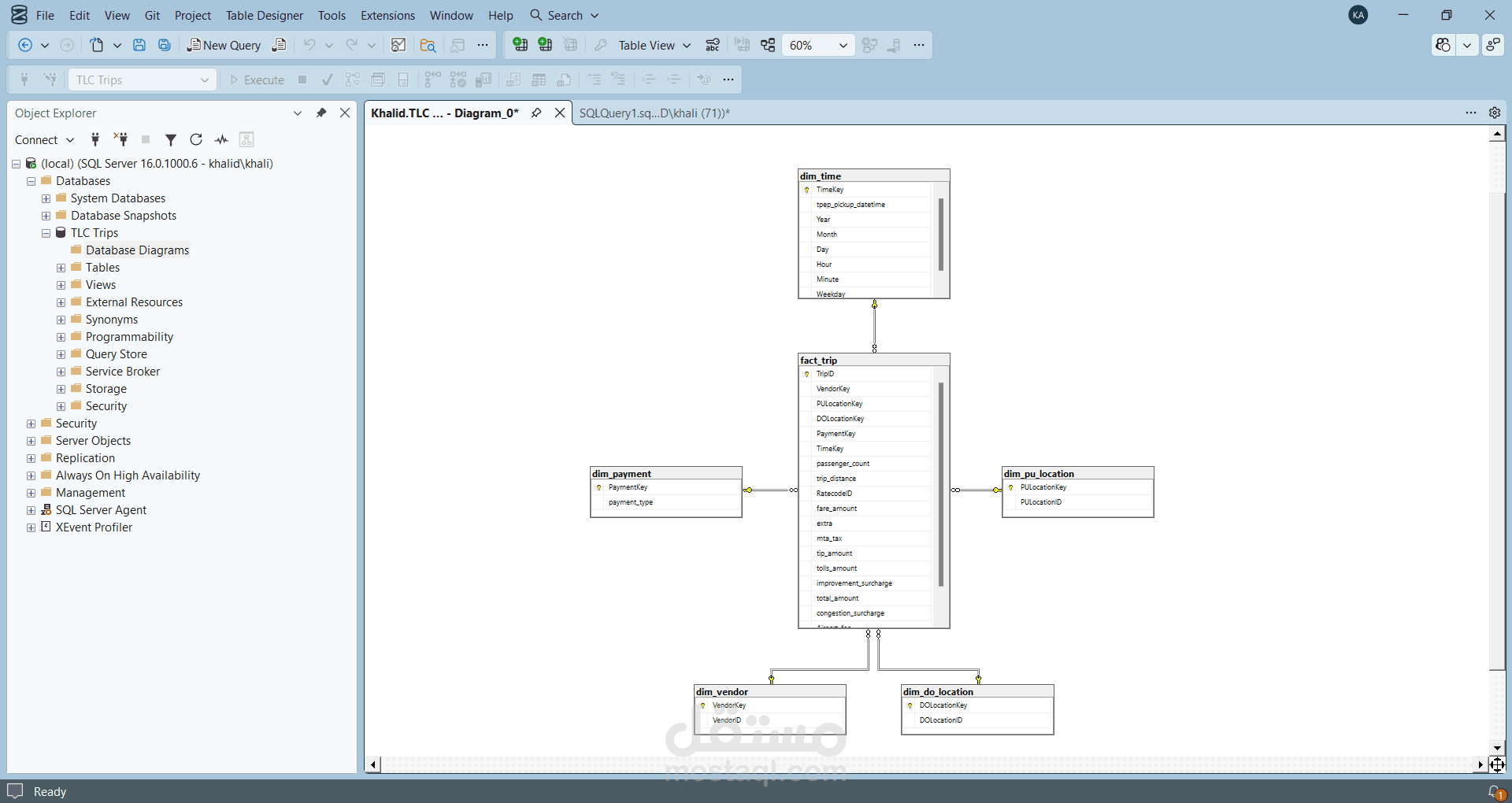
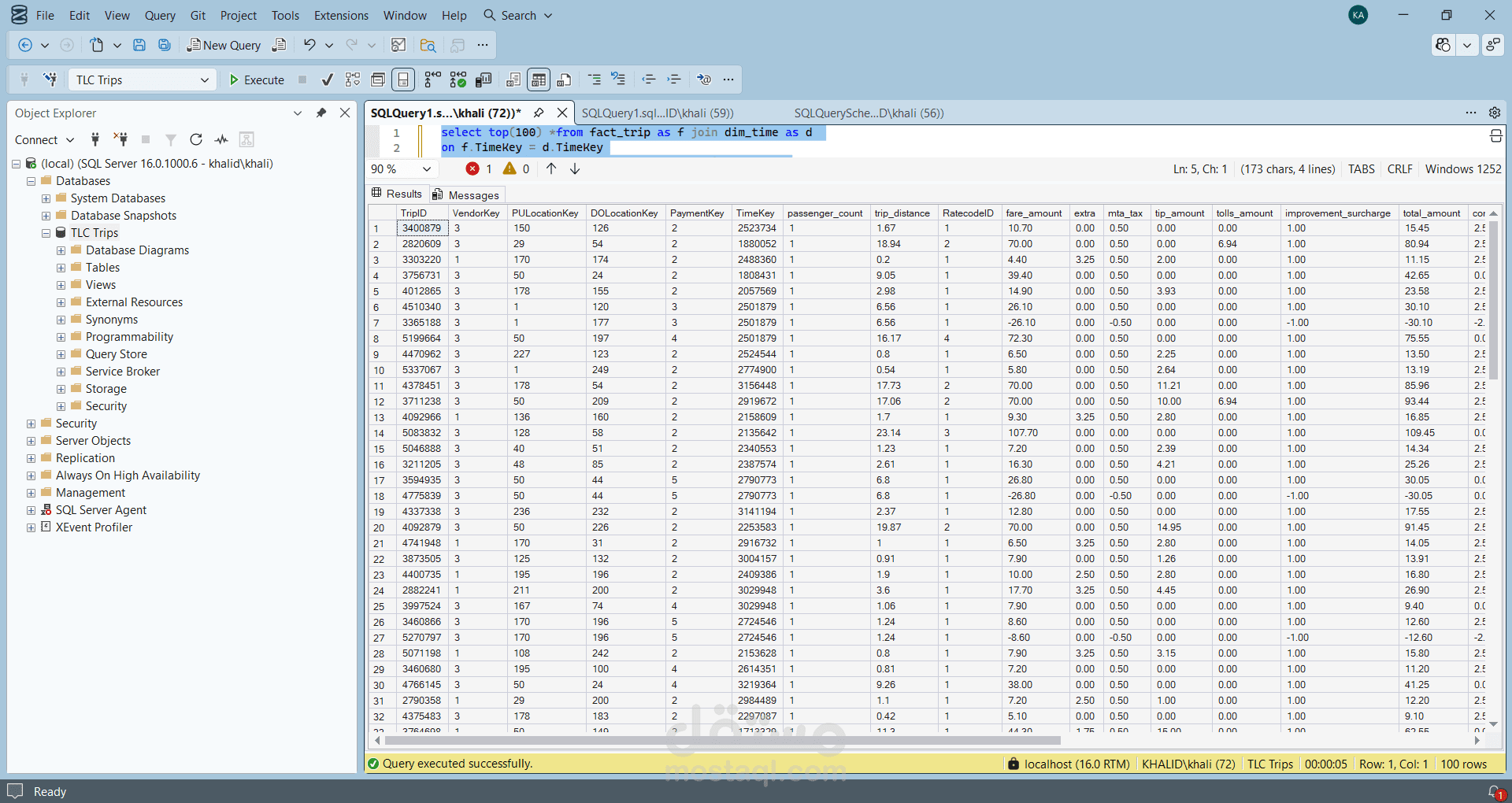
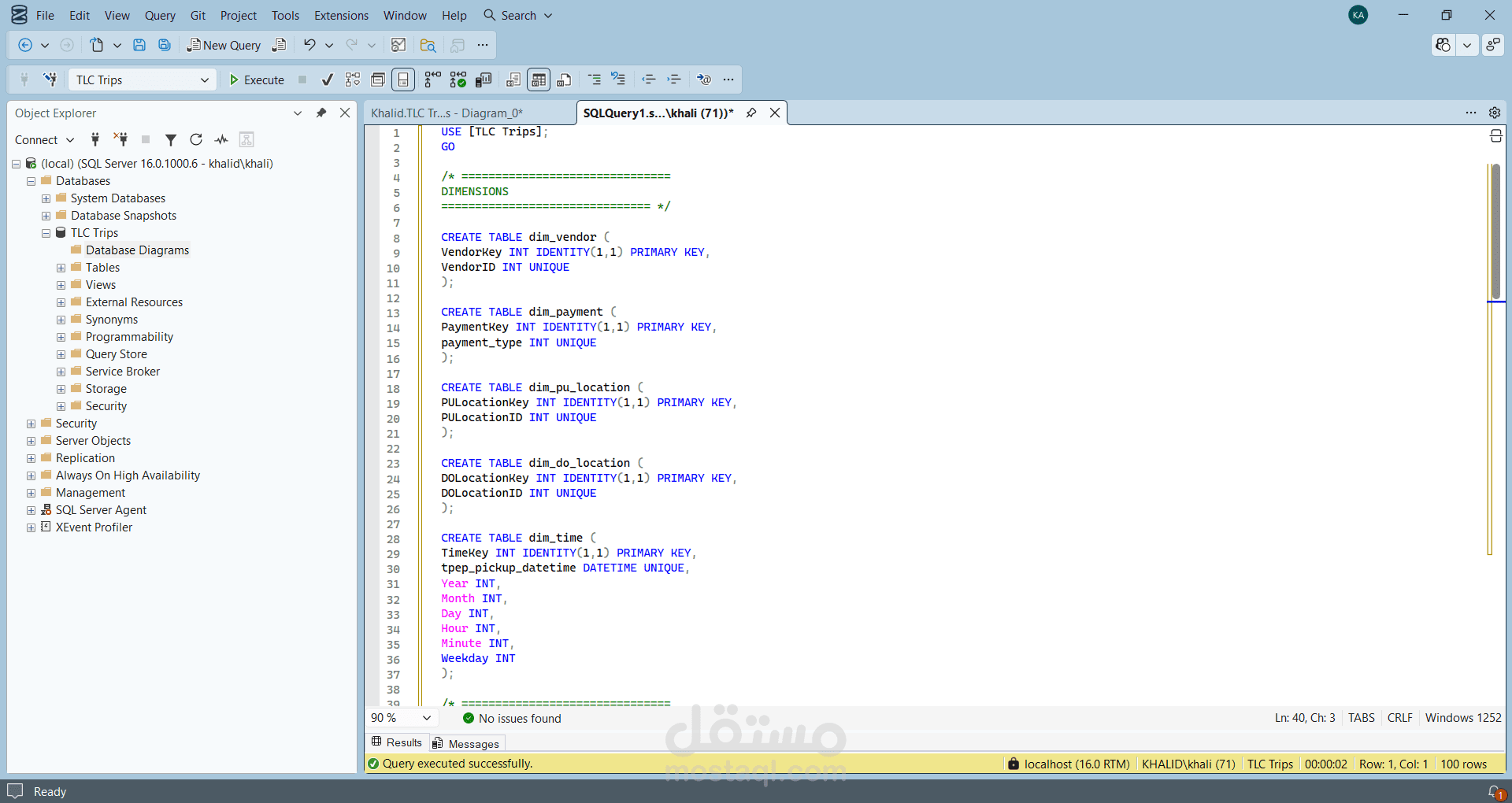
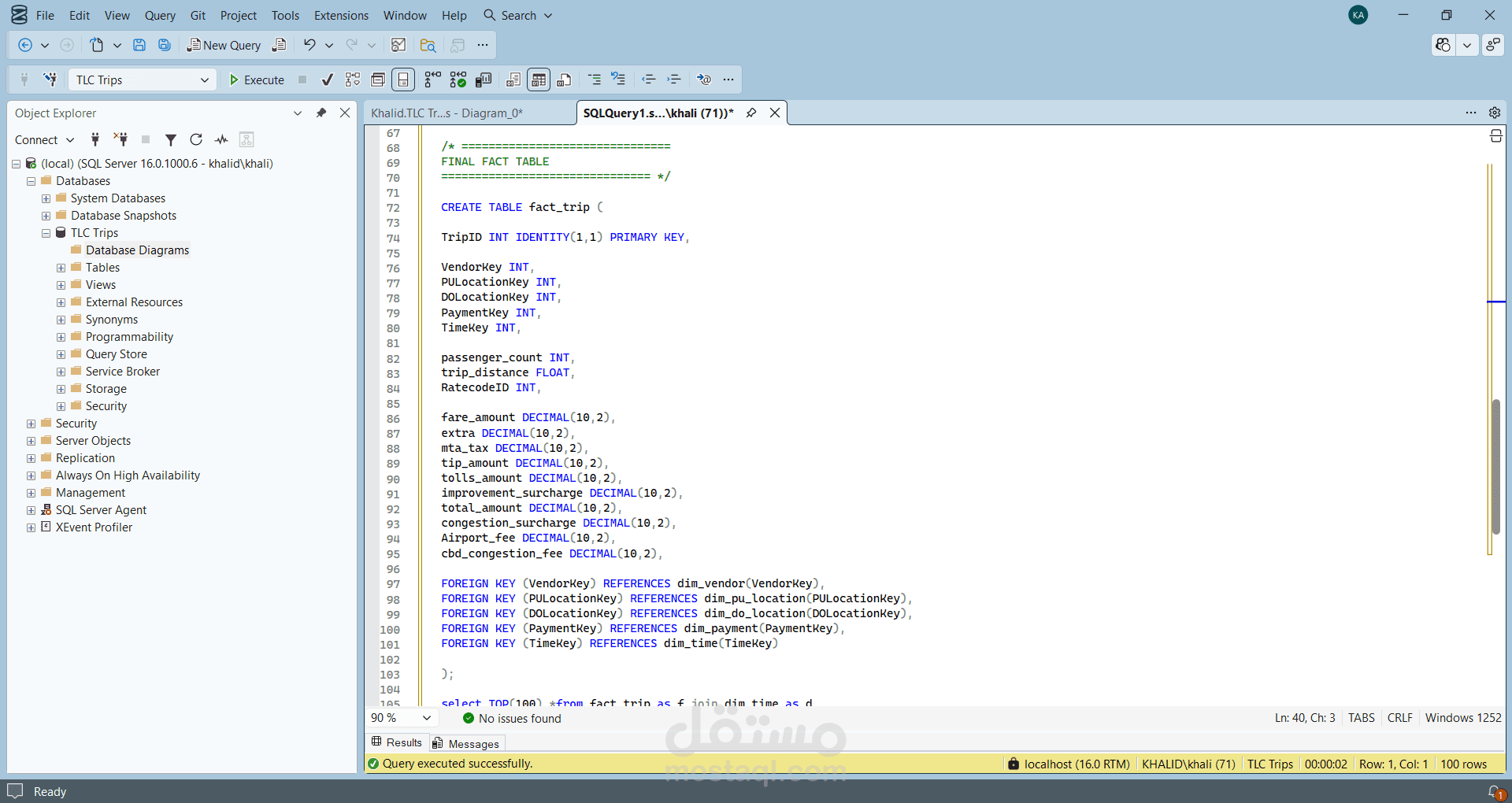
قمت بتطوير مشروع Data Engineering متكامل لبناء خط معالجة بيانات (ETL Pipeline) لمعالجة بيانات رحلات التاكسي في مدينة نيويورك لعام 2025 والتي تتجاوز 36 مليون سجل.
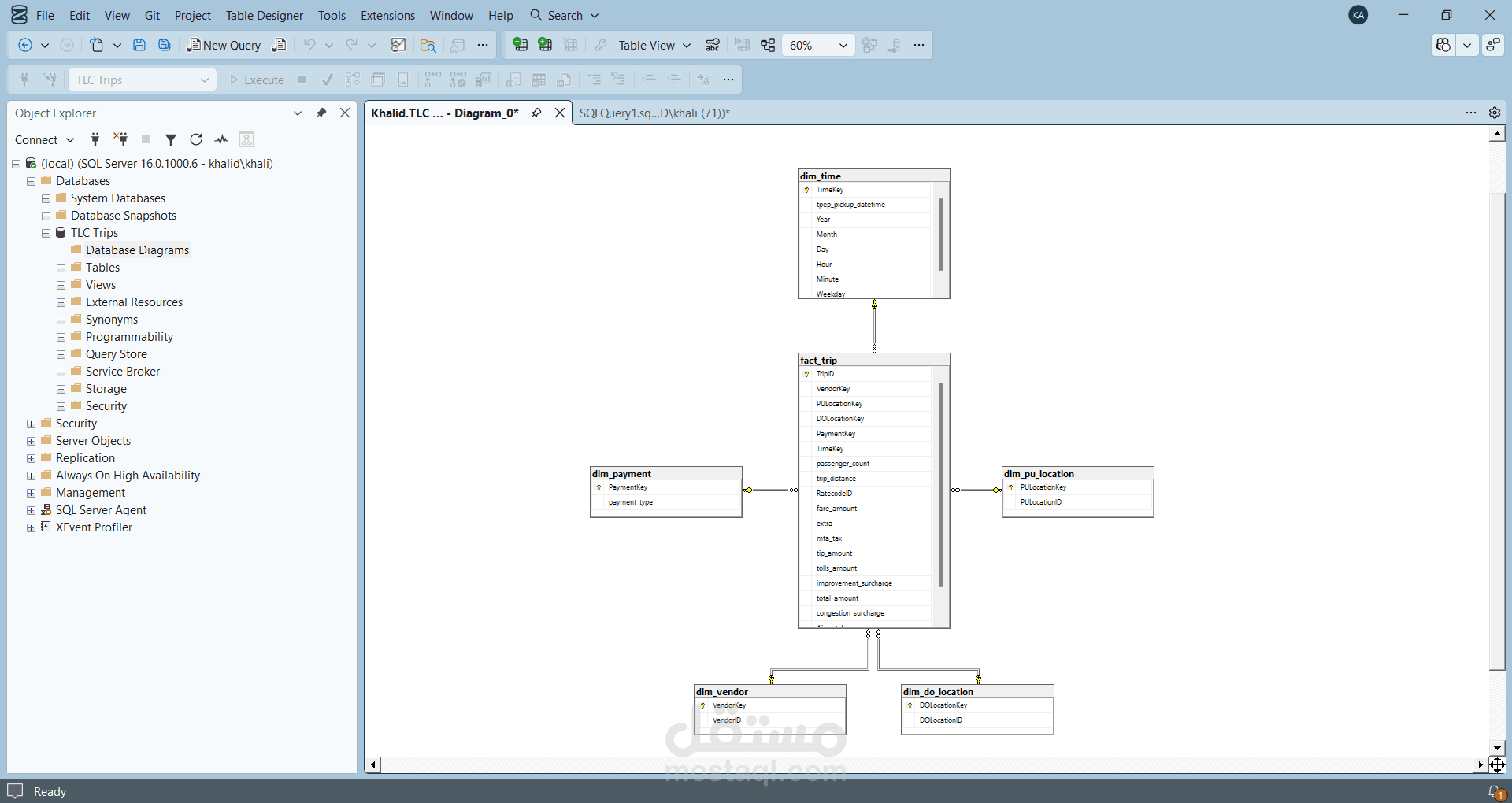
يعتمد المشروع على استخدام PySpark لمعالجة البيانات بشكل موزع وقابل للتوسع، ثم تحميل البيانات بعد تنظيفها وتحويلها إلى Data Warehouse مبني على Star Schema باستخدام SQL Server، وأخيرًا إنشاء لوحات معلومات تفاعلية باستخدام Power BI لاستخراج رؤى تحليلية تساعد في اتخاذ القرار.
? أهم ما تم تنفيذه
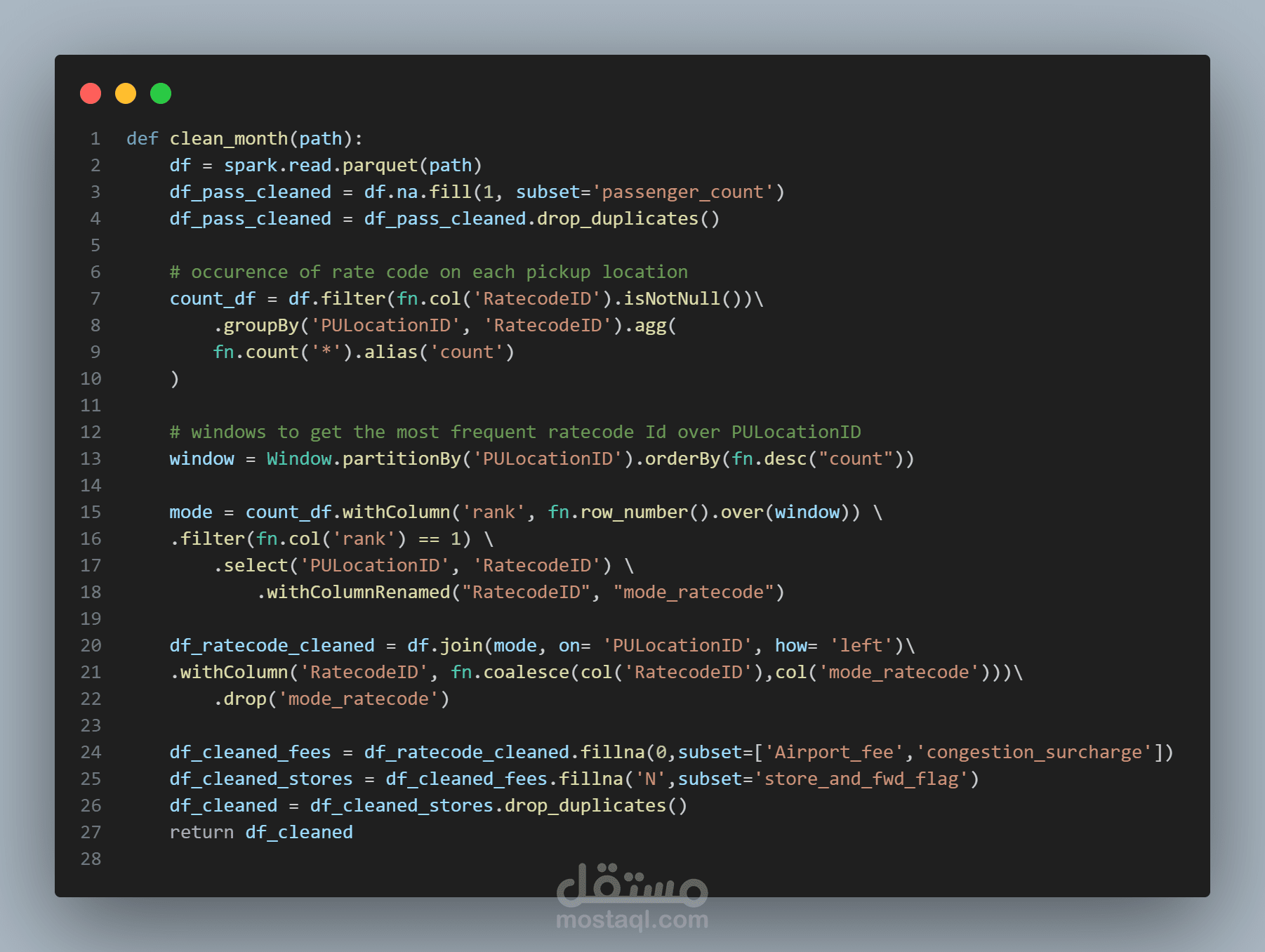
- قراءة ملفات Parquet الشهرية ومعالجة البيانات الضخمة باستخدام PySpark
- تنظيف البيانات ومعالجة القيم المفقودة وإزالة التكرارات
- تصميم Star Schema يحتوي على Fact Table و Dimension Tables
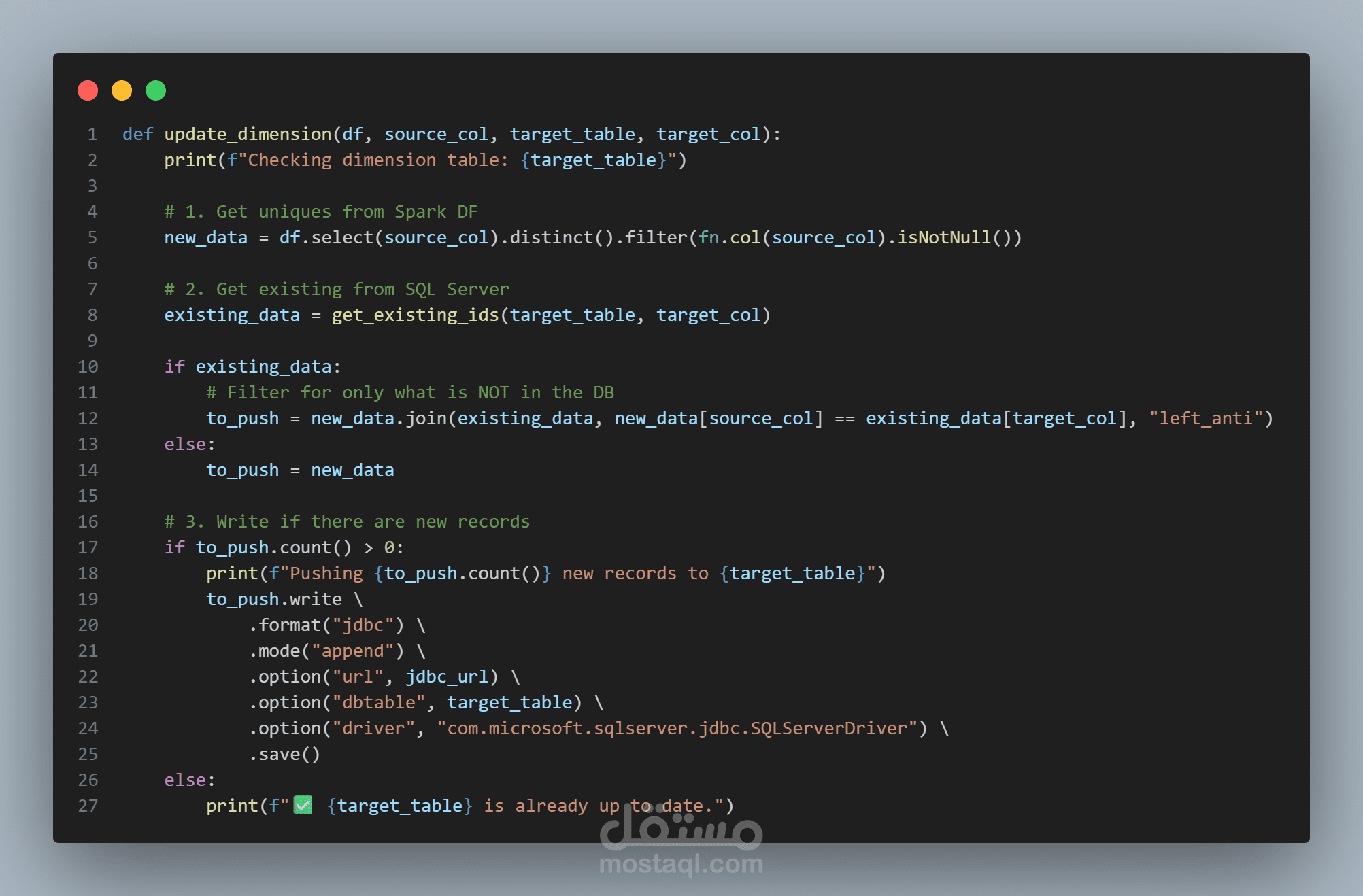
- تنفيذ Upserts للحفاظ على سلامة العلاقات المرجعية
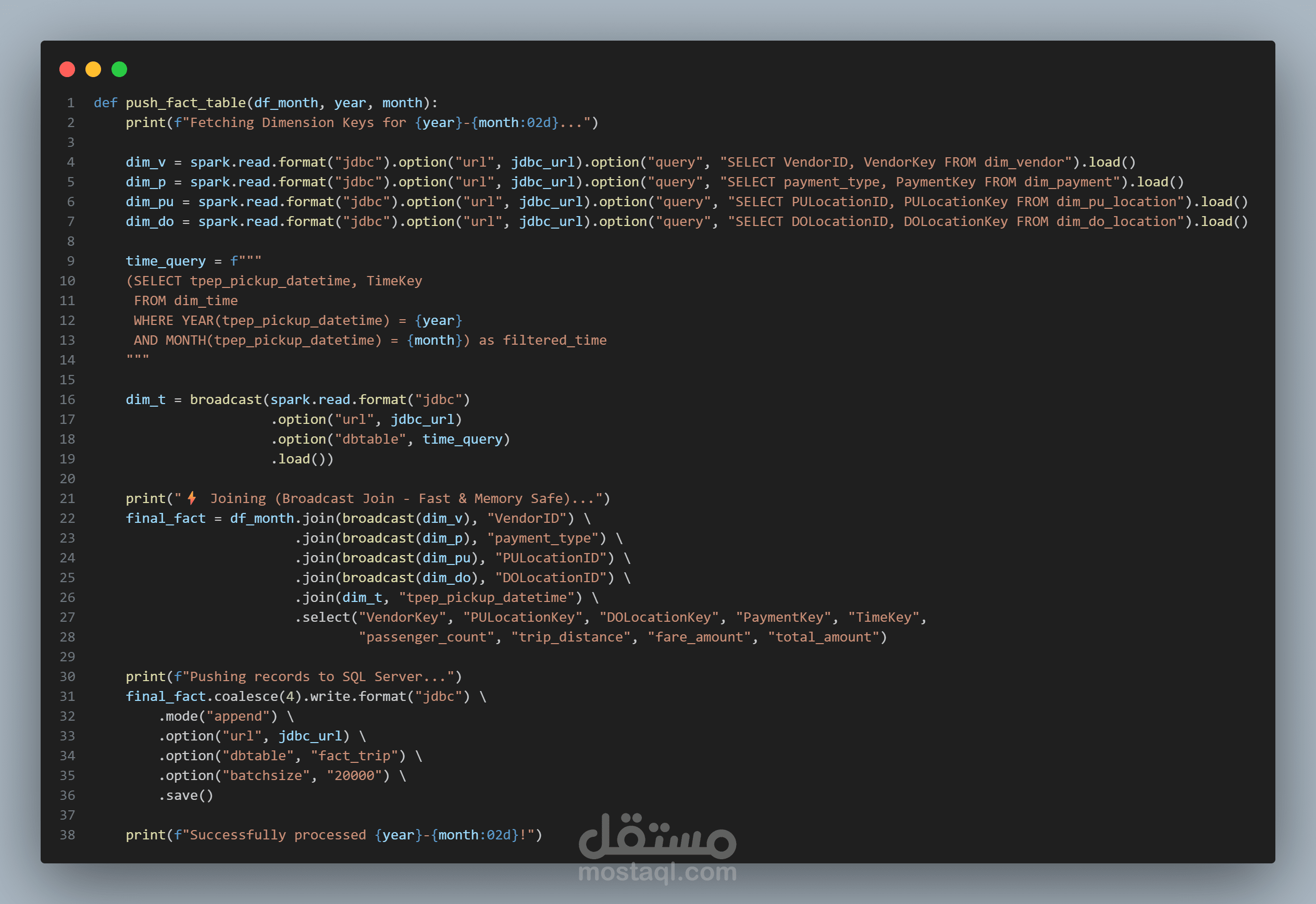
- استخدام Broadcast Joins لتحسين الأداء
- تحميل البيانات إلى SQL Server باستخدام JDBC
- إنشاء Dashboards احترافية لتحليل الإيرادات، المسارات، وأنواع الدفع
? نتائج المشروع
- معالجة وتحميل أكثر من 36M+ سجل داخل Data Warehouse
- تحسين سرعة الاستعلام والتحليل
- استخراج Insights مهمة حول الإيرادات وسلوك العملاء