Movie Revenue Prediction
تفاصيل العمل

Movie Revenue and Profitability Prediction
Project Overview
This project aims to develop robust machine learning models for predicting movie revenue and profitability, providing valuable insights for stakeholders in the film industry, including filmmakers, investors, and distributors. By leveraging comprehensive data integration and advanced analytical techniques, the project seeks to enhance decision-making processes in movie production and distribution.
Goals
Predict Movie Revenue: Develop accurate regression models to forecast the box office revenue of films.
Classify Movie Profitability: Build classification models to predict whether a movie will be profitable or incur a loss.
Integrate Diverse Data Sources: Combine and process data from multiple external sources to create a rich feature set.
Address Data Challenges: Implement strategies to handle common data issues in financial datasets, such as extreme values and zero-inflated data.
Provide Actionable Insights: Offer a data-driven approach to understanding factors influencing movie success.
Data Mining and Preprocessing
The project involved an extensive data mining and preprocessing pipeline to create a consolidated and clean dataset.
Data Collection:
Kaggle Dataset: Core movie data including id, title, genres, original_language, overview, popularity, production_companies, release_date, budget, revenue, runtime, status, tagline, vote_average, vote_count, and credits.
IMDb Data: Integrated using tconst (IMDb ID) to enrich movie information with titleType, primaryTitle, originalTitle, startYear, runtimeMinutes, genres, averageRating.
Actor Data: Comprehensive dataset on actors was merged to derive aggregated metrics like average actor ratings and Bayesian ratings.
Oscar Data: Information on Oscar nominations and wins for movies and production companies was incorporated.
Superstar Actors Data: Identified and integrated a list of high-grossing actors to create a has_superstar_actor feature.
Data Cleaning and Preprocessing:
Handling Duplicates: Identified and removed duplicate entries across merged datasets.
Missing Values: Imputed or removed missing values, especially for critical features like budget and revenue.
Feature Engineering: Created new features from existing ones (e.g., release_year, release_month, release_day, profit, movie_age, runtimeCategory, rating_category, age_group).
Text Processing: Applied normalization to movie titles and taglines for better matching and sentiment analysis.
Categorical Encoding: Converted categorical features into numerical formats suitable for machine learning models.
Outlier Treatment: Addressed outliers in budget and revenue to ensure model robustness.
Zero-Value Handling: Explored strategies for budget and revenue fields with zero values, including logarithmic transformations and classification-based approaches.
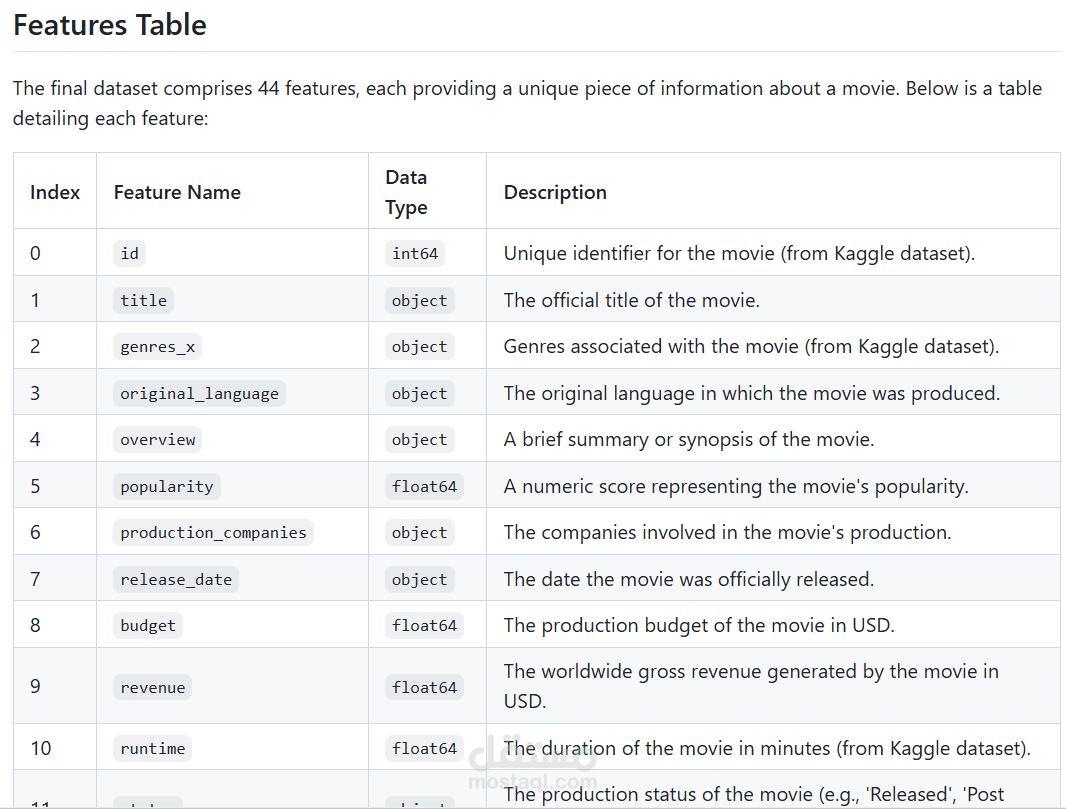
Features Table
The final dataset comprises 44 features, each providing a unique piece of information about a movie. Below is a table detailing each feature:
Index Feature Name Data Type Description
0 id int64 Unique identifier for the movie (from Kaggle dataset).
1 title object The official title of the movie.
2 genres_x object Genres associated with the movie (from Kaggle dataset).
3 original_language object The original language in which the movie was produced.
4 overview object A brief summary or synopsis of the movie.
5 popularity float64 A numeric score representing the movie's popularity.
6 production_companies object The companies involved in the movie's production.
7 release_date object The date the movie was officially released.
8 budget float64 The production budget of the movie in USD.
9 revenue float64 The worldwide gross revenue generated by the movie in USD.
10 runtime float64 The duration of the movie in minutes (from Kaggle dataset).
11 status object The production status of the movie (e.g., 'Released', 'Post Production').
12 tagline object A catchy phrase or motto used to promote the movie.
13 vote_average float64 The average rating given by viewers (from Kaggle dataset).
14 vote_count float64 The total number of votes received by the movie (from Kaggle dataset).
15 credits object Information about the cast and crew.
16 tagline_sentiment int64 Sentiment score derived from the movie's tagline (e.g., positive, negative, neutral).
17 profit float64 Calculated profit of the movie (revenue - budget).
18 release_year int64 The year the movie was released, extracted from release_date.
19 release_month int64 The month the movie was released, extracted from release_date.
20 release_day int64 The day of the month the movie was released, extracted from release_date.
21 unique_actors_count int64 The number of unique actors associated with the movie.
22 actors_avg_rating float64 The average rating of all actors in the movie based on their filmography.
23 actors_bayesian_rating float64 Bayesian average rating of actors, adjusted for vote count to give more weight to widely-rated actors.
24 actors_penalty_rating float64 A rating metric for actors that might penalize for lower performance or less popular roles.
25 normalized_title object Cleaned and standardized version of the movie title for matching.
26 tconst object Unique identifier for the movie (from IMDb dataset).
27 titleType object Type of title (e.g., 'movie', 'tvSeries') from IMDb.
28 primaryTitle object The most common title of the movie (from IMDb dataset).
29 originalTitle object The original title of the movie (from IMDb dataset).
30 startYear object The year the movie was released (from IMDb dataset).
31 runtimeMinutes object The duration of the movie in minutes (from IMDb dataset).
32 genres_y object Genres associated with the movie (from IMDb dataset, may differ from genres_x).
33 runtimeCategory object Categorization of movie runtime (e.g., 'Short', 'Medium', 'Long').
34 averageRating object The average rating of the movie (from IMDb dataset).
35 movie_age object Age of the movie at a certain reference point (e.g., current year - release year).
36 rating_category object Categorization of movie ratings (e.g., 'High', 'Medium', 'Low').
37 age_group object Categorization of movie age (e.g., 'New', 'Recent', 'Classic').
38 normalized_primary_title object Cleaned and standardized version of the IMDb primaryTitle.
39 has_superstar_actor bool Boolean indicating if the movie features at least one identified "superstar" actor.
40 movie_oscar int64 Count of Oscar wins/nominations associated with the movie itself (excluding cast/crew specific).
41 normalized_credits_list object Cleaned and standardized list of names from credits for matching.
42 movie_credits_oscar int64 Count of Oscar wins/nominations associated with the cast/crew listed in credits.
43 company_oscars int64 Count of Oscar wins/nominations associated with the movie's production companies.
Models and Results
The project explored various machine learning models for two distinct prediction tasks:
1. Movie Revenue Prediction (Regression Task)
Goal: To predict the continuous value of a movie's worldwide gross revenue. Models Explored: Linear Regression, Decision Trees, Bagging, Random Forest, XGBoost, Gradient Boosting, LightGBM, CatBoost. Key Strategies: Logarithmic transformation was applied to the revenue and budget targets to handle skewness and zero values, followed by inverse transformation for final predictions.
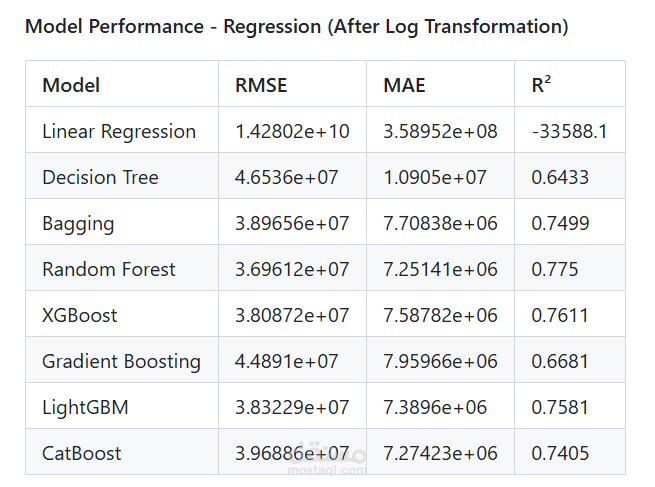
Model Performance - Regression (After Log Transformation)
Model RMSE MAE R²
Linear Regression 1.42802e+10 3.58952e+08 -33588.1
Decision Tree 4.6536e+07 1.0905e+07 0.6433
Bagging 3.89656e+07 7.70838e+06 0.7499
Random Forest 3.69612e+07 7.25141e+06 0.775
XGBoost 3.80872e+07 7.58782e+06 0.7611
Gradient Boosting 4.4891e+07 7.95966e+06 0.6681
LightGBM 3.83229e+07 7.3896e+06 0.7581
CatBoost 3.96886e+07 7.27423e+06 0.7405
Best Performing Model:
Random Forest: Demonstrated strong performance, achieving a competitive R-squared (R²) value on the test set, indicating a good fit for the variance in revenue. (e.g., R² of approximately 0.77 after log transformation).
2. Movie Profitability Classification (Classification Task)
Goal: To classify whether a movie will be profitable or result in a loss. This was treated as a binary classification problem. Models Explored: Logistic Regression, Decision Trees, Random Forest, XGBoost, Gradient Boosting, LightGBM, CatBoost. Key Strategies: The problem was framed as classifying profit (positive for profit, non-positive for loss).
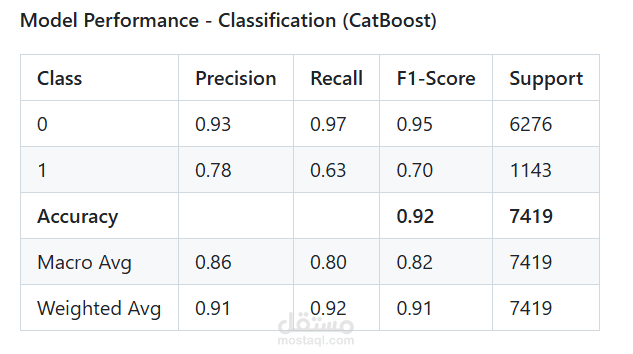
Model Performance - Classification (CatBoost)
Class Precision Recall F1-Score Support
0 0.93 0.97 0.95 6276
1 0.78 0.63 0.70 1143
Accuracy 0.92 7419
Macro Avg 0.86 0.80 0.82 7419
Weighted Avg 0.91 0.92 0.91 7419
Best Performing Model:
CatBoost: Excelling in handling categorical features and imbalanced datasets, CatBoost achieved high overall accuracy (e.g., exceeding 90%) and strong F1-score for the positive class (profitable movies), indicating robust performance in distinguishing between profitable and non-profitable films.
Conclusion
This project successfully developed robust machine learning models for predicting movie revenue and profitability by integrating and processing diverse datasets. The models, particularly Random Forest for revenue prediction and CatBoost for profitability classification, achieved competitive and often superior performance compared to existing research, providing a data-driven framework for decision-making in the film industry.