تحليل شامل لرواتب موظفي سان فرانسيسكو: من تنظيف البيانات إلى استخراج الرؤى
تفاصيل العمل
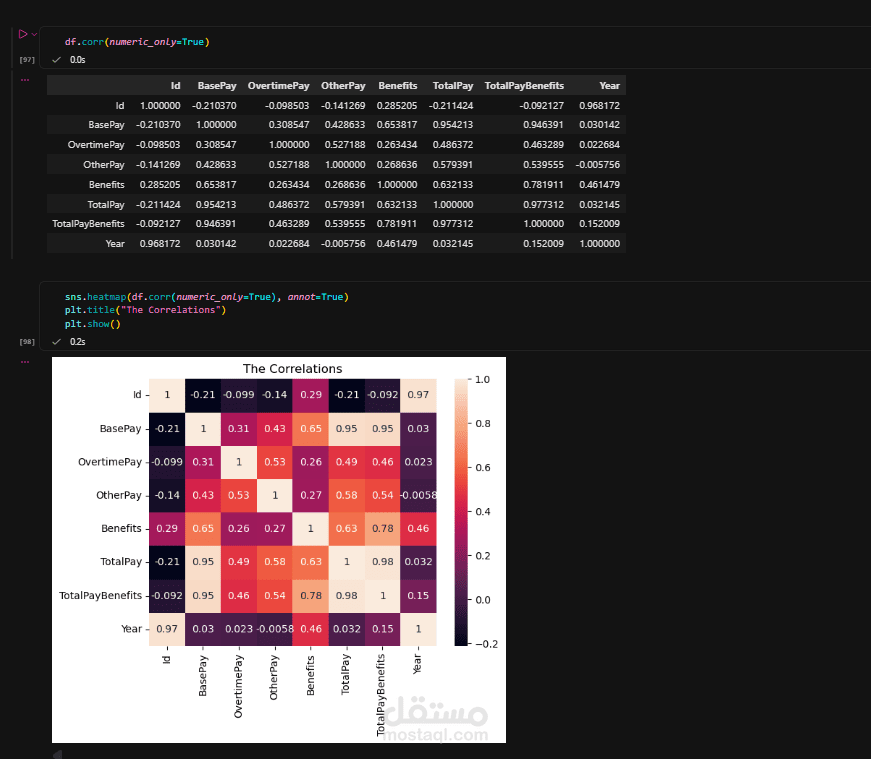
يهدف هذا المشروع إلى تحليل مجموعة بيانات ضخمة تحتوي على رواتب ومزايا آلاف الموظفين في مدينة سان فرانسيسكو على مدار عدة سنوات. ركزت في هذا المشروع على تنظيف البيانات بدقة ومن ثم استخراج رؤى قيّمة حول توزيع الرواتب وأعلى الوظائف أجراً.
الميزات والتقنيات المستخدمة:
معالجة البيانات الأولية (Data Wrangling): تم التعامل مع مشاكل حقيقية في البيانات مثل القيم النصية الخاطئة ('ERROR', 'Not Provided') وتحويلها إلى قيم رقمية قابلة للتحليل باستخدام مكتبة Pandas.
التعامل مع القيم المفقودة: تم استخدام تقنيات متقدمة لملء القيم المفقودة في الأعمدة المالية مثل BasePay و Benefits عن طريق حساب المتوسط لكل مجموعة وظيفية (Groupby & Transform)، وهي طريقة تحافظ على دقة البيانات بشكل أفضل من المتوسط العام.
استخراج الرؤى (Insights): تم استخراج رؤى قيّمة مثل:
تحديد أعلى 10 مسميات وظيفية من حيث إجمالي الراتب (Total Pay & Benefits).
تحليل اتجاه متوسط الرواتب عبر السنوات المختلفة.
التصور البياني: تم إنشاء رسوم بيانية مثل المدرج التكراري (Histogram) لتوزيع الرواتب، والرسوم البيانية الخطية (Line plots) لتوضيح اتجاهات الرواتب عبر الزمن، والأعمدة البيانية (Bar plots) لأعلى الوظائف أجراً.