Information Retrieval System
تفاصيل العمل
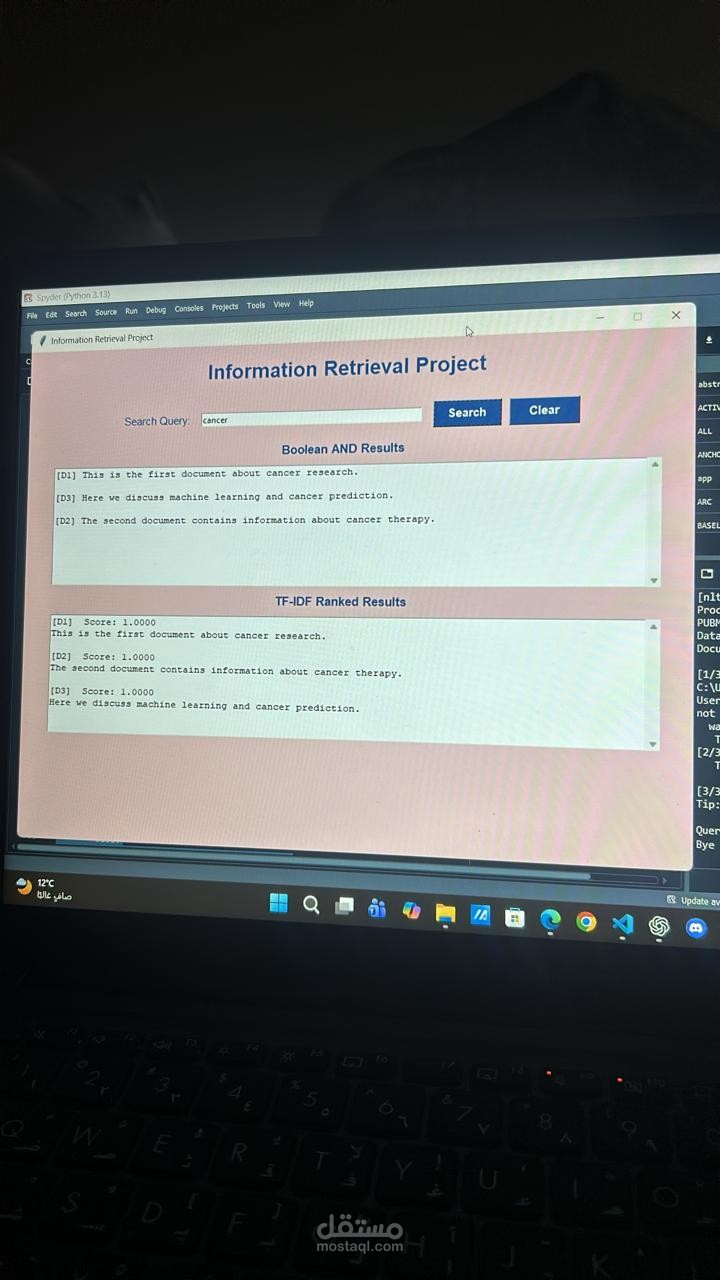
This project is an Information Retrieval System designed to efficiently search and retrieve relevant information from a large collection of documents.
The system allows users to enter a search query, then processes the text data and returns the most relevant documents based on similarity and keyword matching. The goal of the system is to help users quickly find useful information from large datasets.
Key Features:
Text preprocessing (tokenization, stop-word removal, normalization)
Keyword-based search functionality
Document ranking based on relevance
Fast retrieval of relevant documents
User-friendly search interface
Technologies Used:
Python
Natural Language Processing (NLP) techniques
TF-IDF for text representation
Cosine Similarity for ranking results
Libraries such as NumPy and Pandas
Outcome:
The system successfully retrieves and ranks documents according to the user's query, improving the efficiency of searching within large text datasets.