Body Performance Data Analysis and Classification Using Machine Learning
تفاصيل العمل
هذا المشروع يهدف إلى تحليل بيانات الأداء البدني للأفراد باستخدام تقنيات تحليل البيانات وتعلم الآلة. يعتمد المشروع على مجموعة بيانات تحتوي على معلومات ديموغرافية وقياسات جسدية ونتائج اختبارات لياقة بدنية، بهدف فهم العلاقة بين هذه العوامل وتصنيف مستوى الأداء البدني للأفراد.
يتكون المشروع من ثلاث مراحل رئيسية:
تحليل البيانات الاستكشافي
تدريب نماذج تعلم الآلة
تقييم أداء النماذج ومقارنتها
بيانات المشروع (Dataset)
يعتمد المشروع على Body Performance Dataset التي تحتوي على:
13,393 سجل
12 متغير
كل سجل يمثل شخصًا خضع لاختبار لياقة بدنية.
أهم المتغيرات في البيانات
البيانات تشمل:
البيانات الديموغرافية
العمر
الجنس
قياسات الجسم
الطول
الوزن
نسبة الدهون في الجسم
قياسات صحية
ضغط الدم الانقباضي
ضغط الدم الانبساطي
اختبارات الأداء البدني
قوة القبضة (Grip Strength)
اختبار المرونة (Sit and Bend Forward)
عدد تمارين البطن (Sit-ups)
اختبار القفز العريض (Broad Jump)
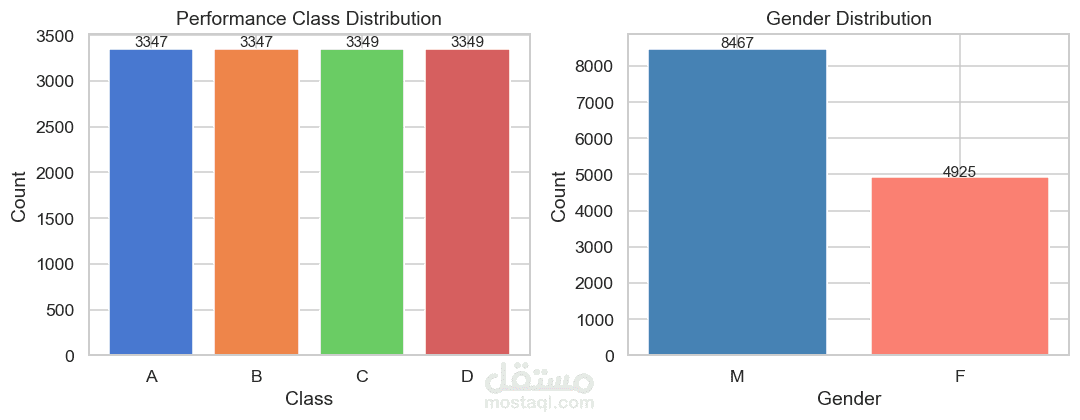
متغير الهدف (Target Variable)
المتغير class يمثل مستوى الأداء البدني ويتم تصنيفه إلى:
A أداء ممتاز
B أداء جيد
C أداء متوسط
D أداء ضعيف
المرحلة الأولى: تحليل البيانات (EDA)
في هذه المرحلة تم إجراء تحليل استكشافي للبيانات لفهم طبيعتها واكتشاف الأنماط داخلها.
تشمل هذه المرحلة:
1. فحص البيانات
تم فحص هيكل البيانات وعدد الصفوف والأعمدة وأنواع البيانات لكل متغير.
2. تحليل القيم المفقودة
تم التحقق من وجود أي قيم مفقودة داخل البيانات.
3. اكتشاف التكرار
تم البحث عن السجلات المكررة وإزالتها لضمان جودة البيانات.
4. الإحصاءات الوصفية
تم حساب:
المتوسط
الانحراف المعياري
القيم الدنيا والعليا
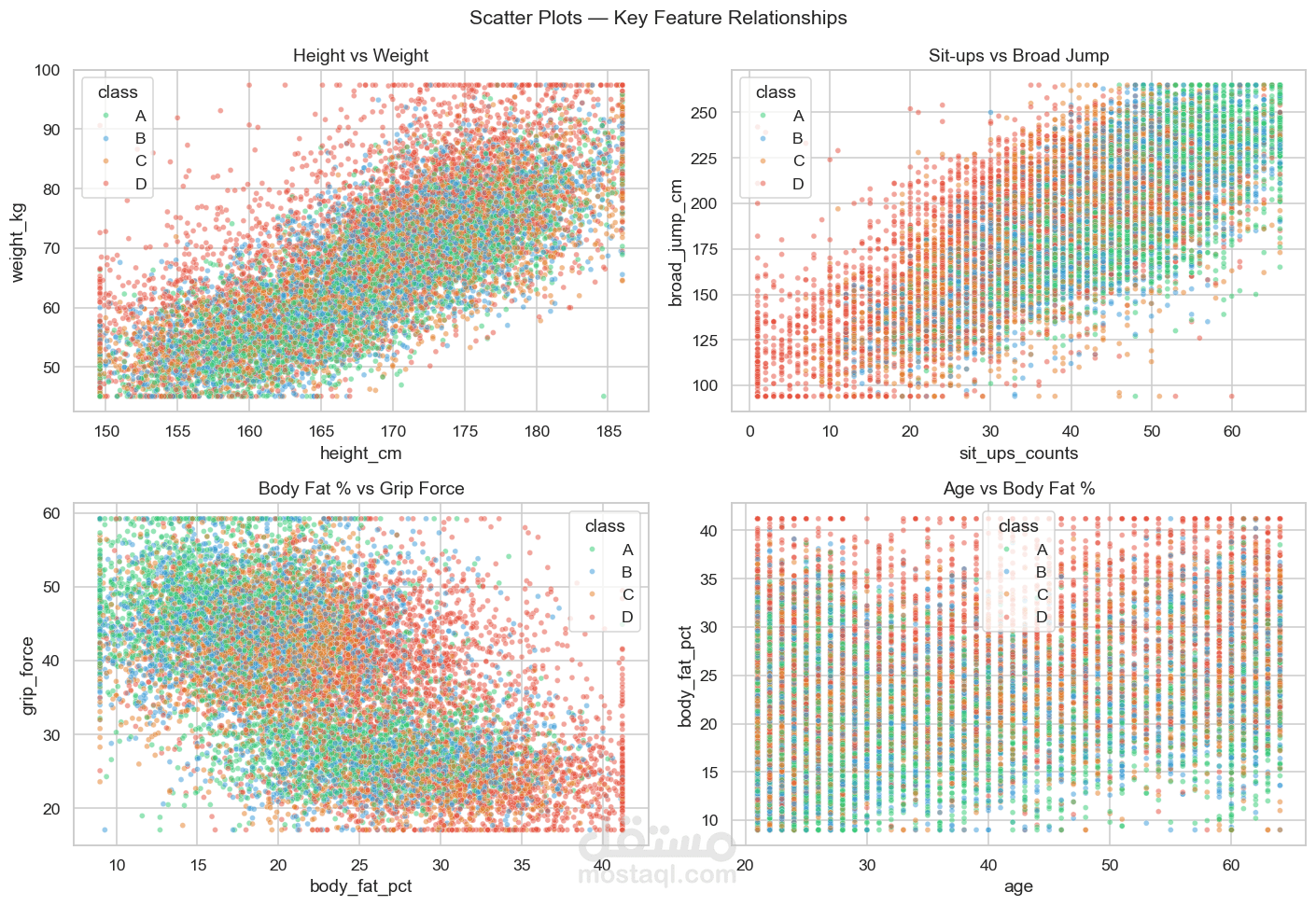
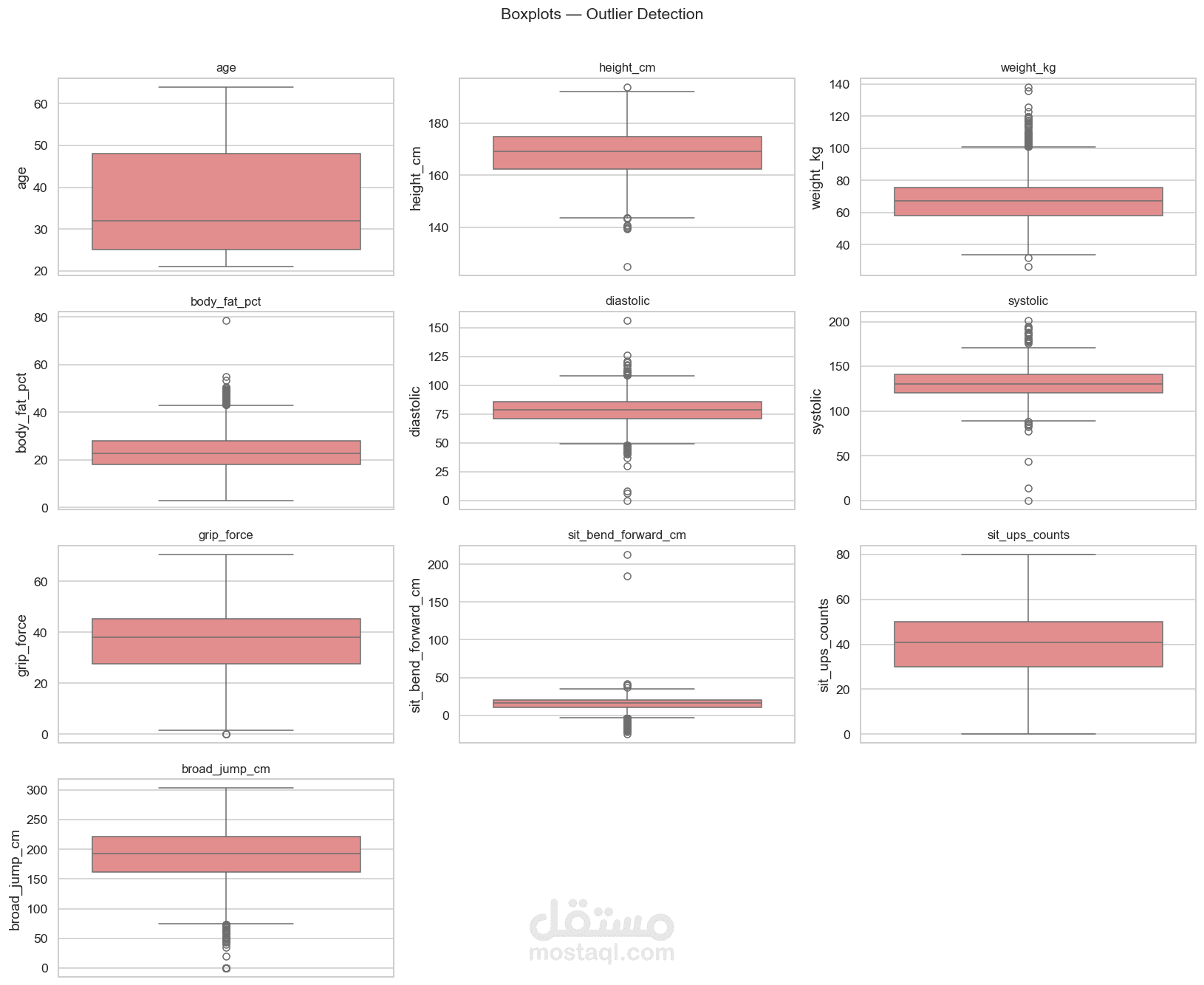
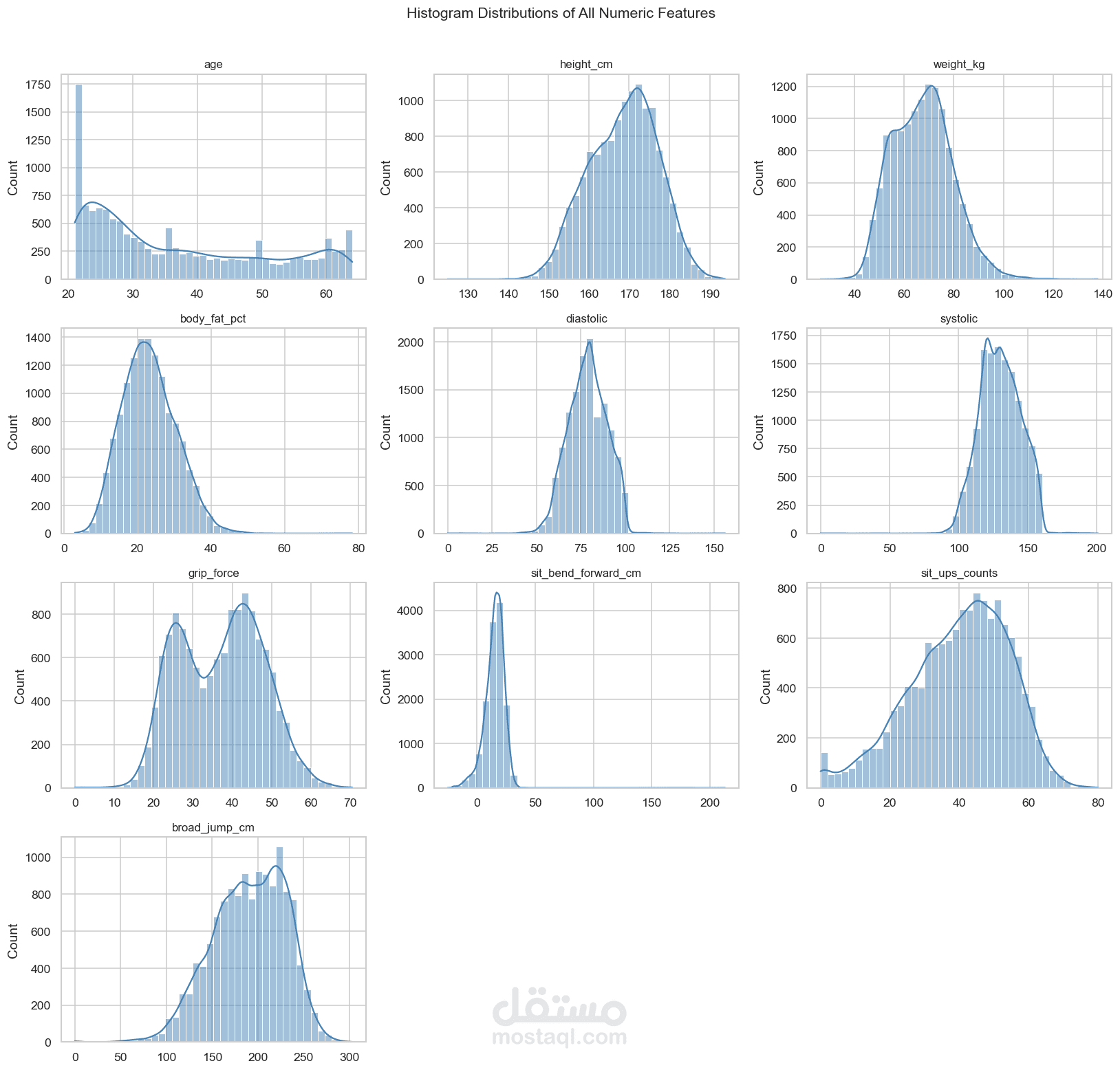
5. تحليل التوزيع
تم استخدام الرسوم البيانية مثل:
Histogram
Boxplot
لفهم توزيع المتغيرات واكتشاف القيم الشاذة.
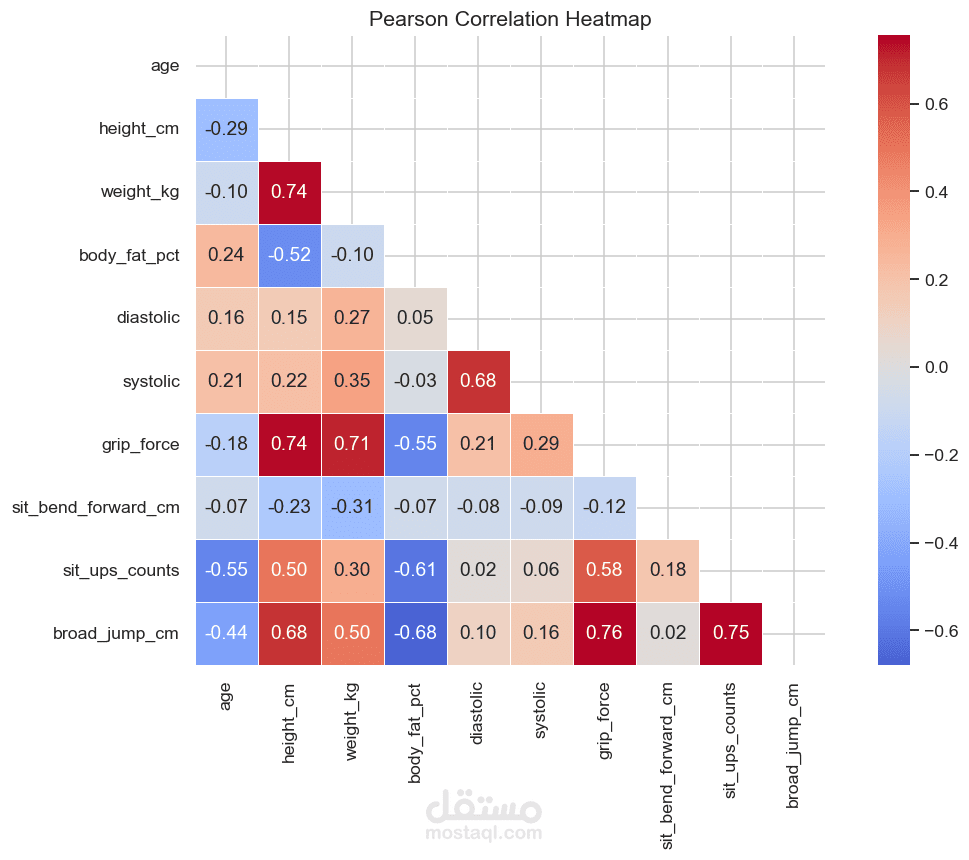
6. تحليل الارتباط
تم استخدام Correlation Heatmap لدراسة العلاقة بين المتغيرات المختلفة.
المرحلة الثانية: بناء نماذج تعلم الآلة
بعد تنظيف البيانات وتحليلها تم الانتقال إلى بناء نماذج تعلم آلي بهدف:
تصنيف مستوى الأداء البدني للأفراد.
Feature Engineering
تم تحويل البيانات إلى شكل مناسب للنماذج عبر:
Encoding للمتغيرات الفئوية
تجهيز البيانات للتدريب
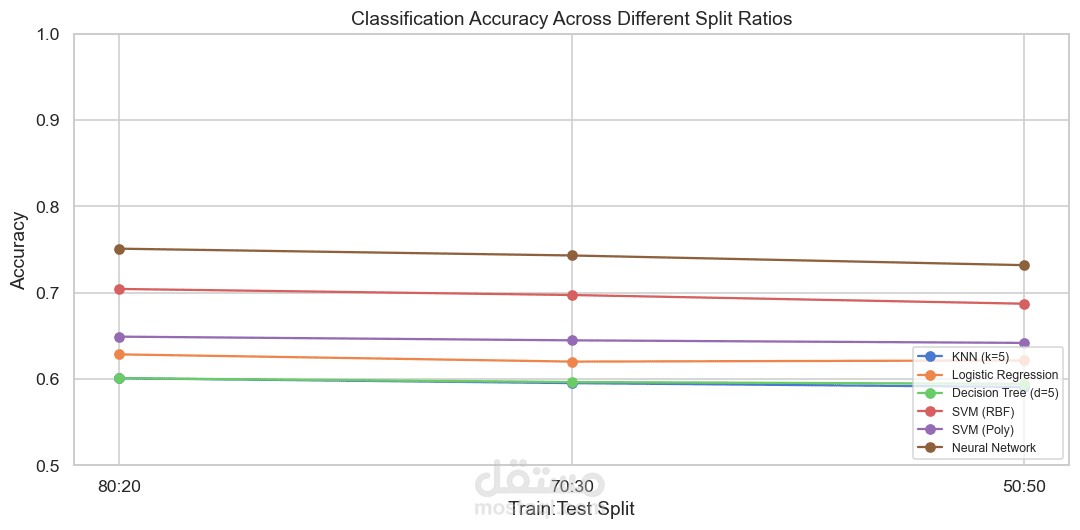
تقسيم البيانات
تم تقسيم البيانات إلى:
Training Set
Testing Set
باستخدام عدة نسب مثل:
70/30
80/20
النماذج المستخدمة
تم تجربة عدة نماذج تعلم آلي مثل:
K-Nearest Neighbors (KNN)
Logistic Regression
نماذج تصنيف أخرى
كما تم استخدام:
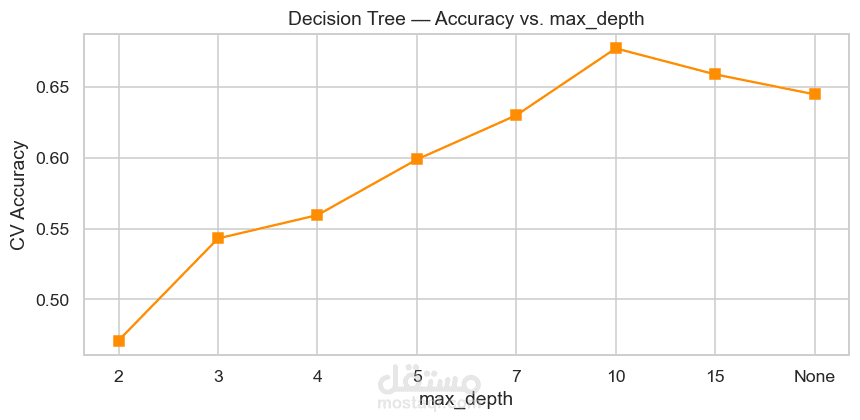
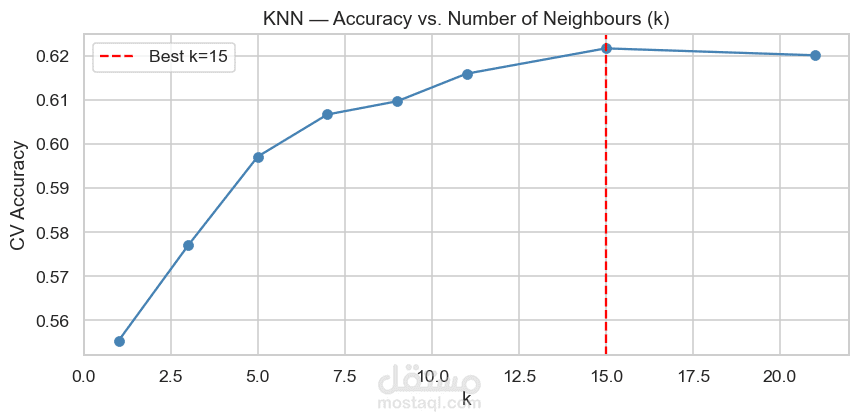
Hyperparameter Tuning لتحسين أداء نموذج KNN عن طريق تجربة قيم مختلفة لـ k.
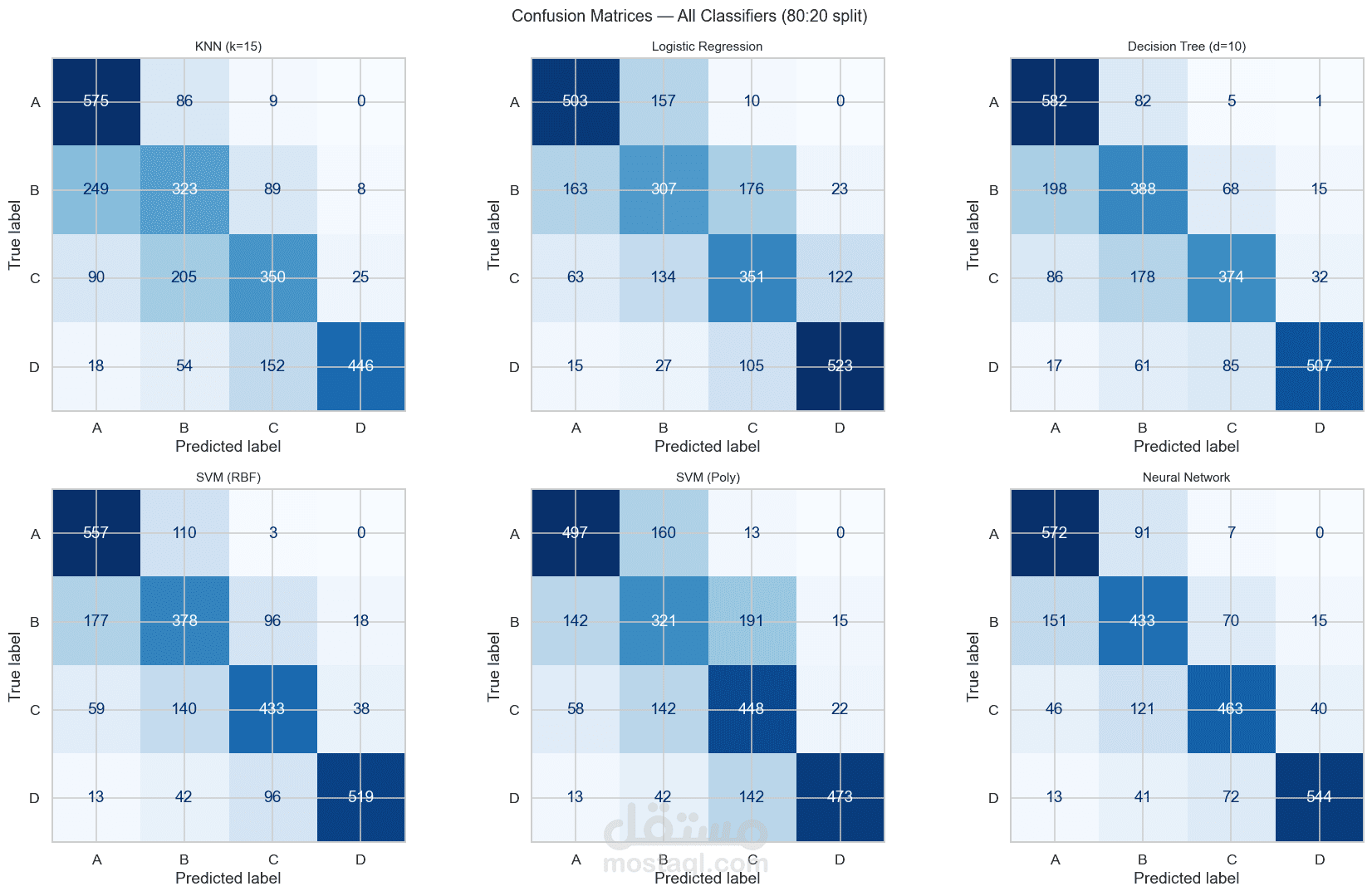
المرحلة الثالثة: تقييم النماذج
تم تقييم النماذج باستخدام عدة مقاييس أداء.
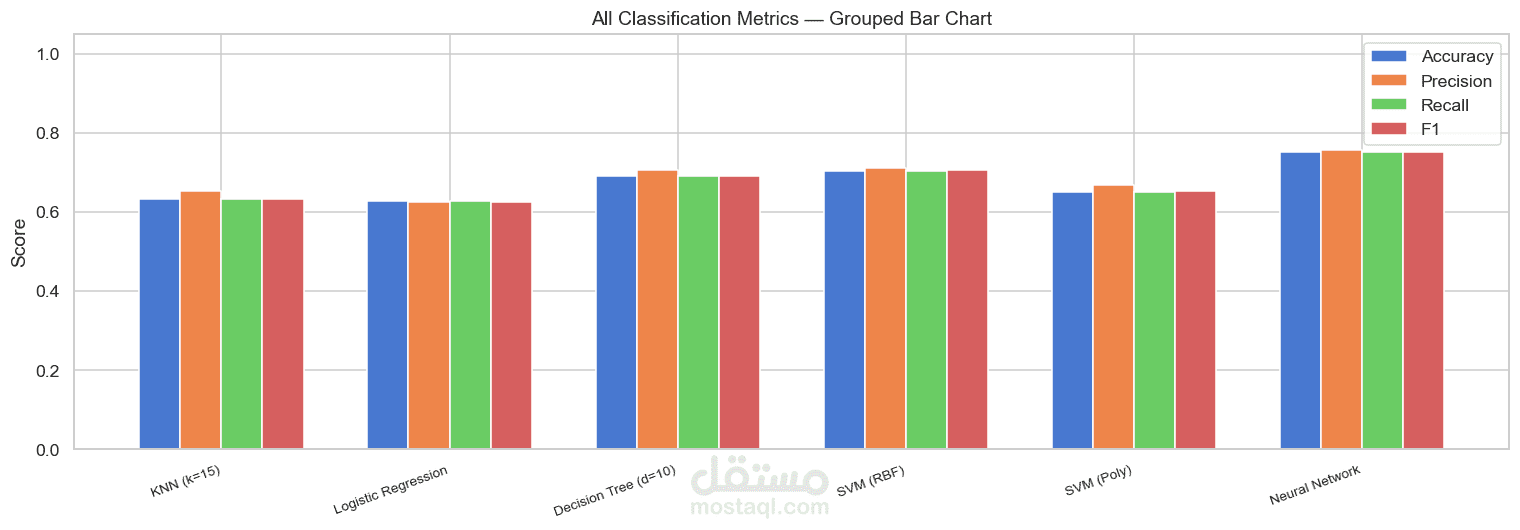
مقاييس التصنيف
Accuracy
Precision
Recall
F1 Score
أدوات التقييم
تم استخدام
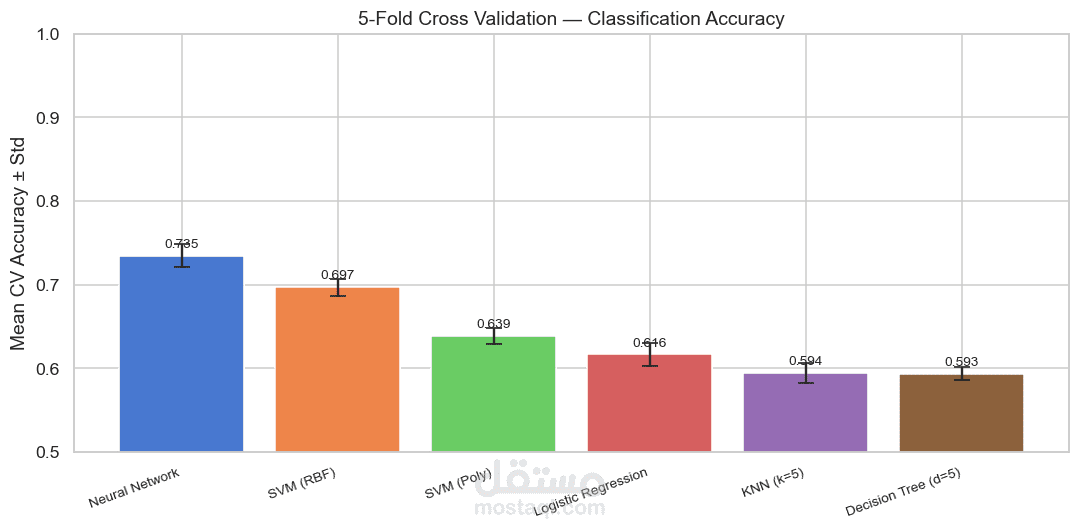
Confusion Matrix, Cross Validation
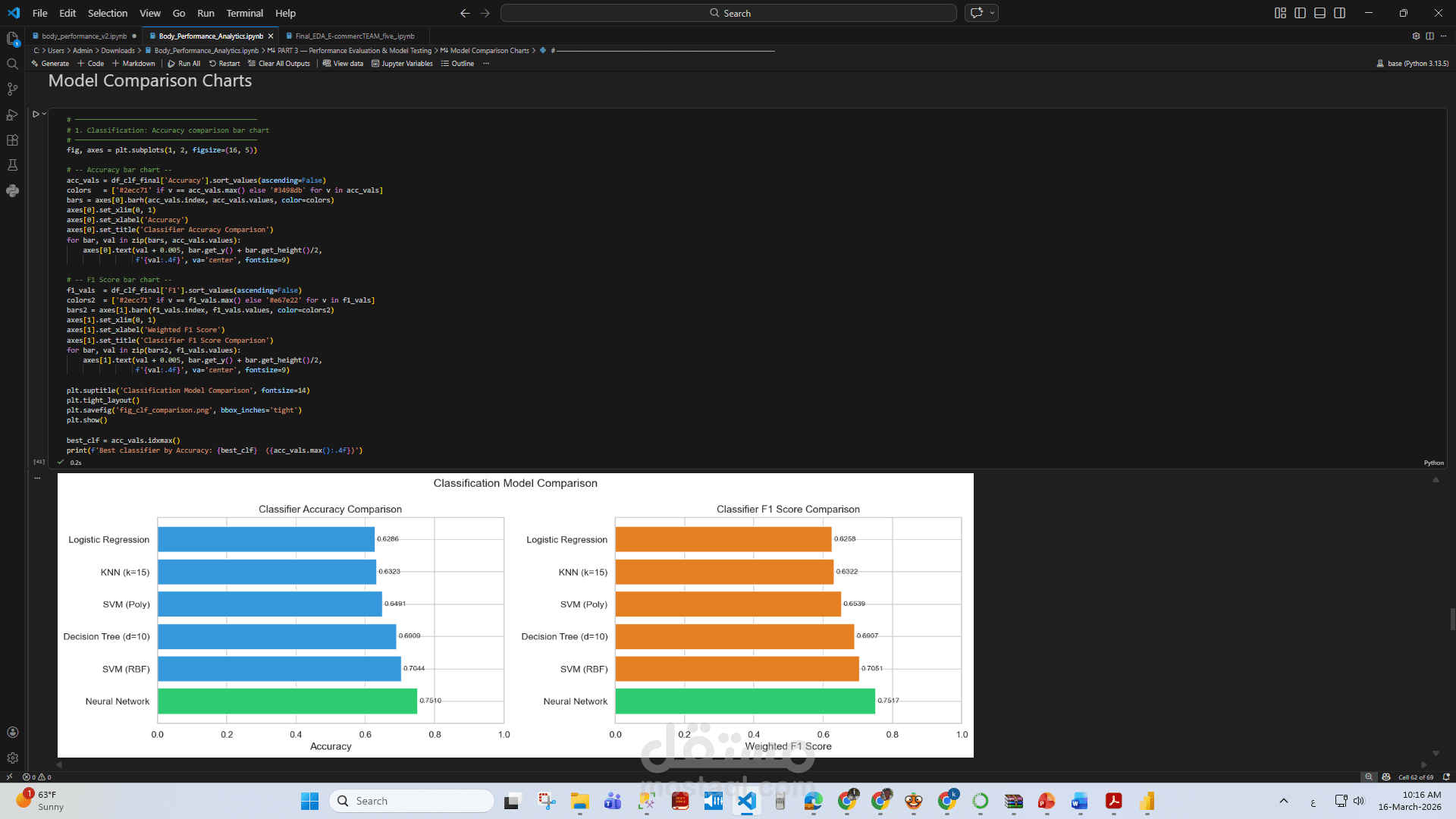
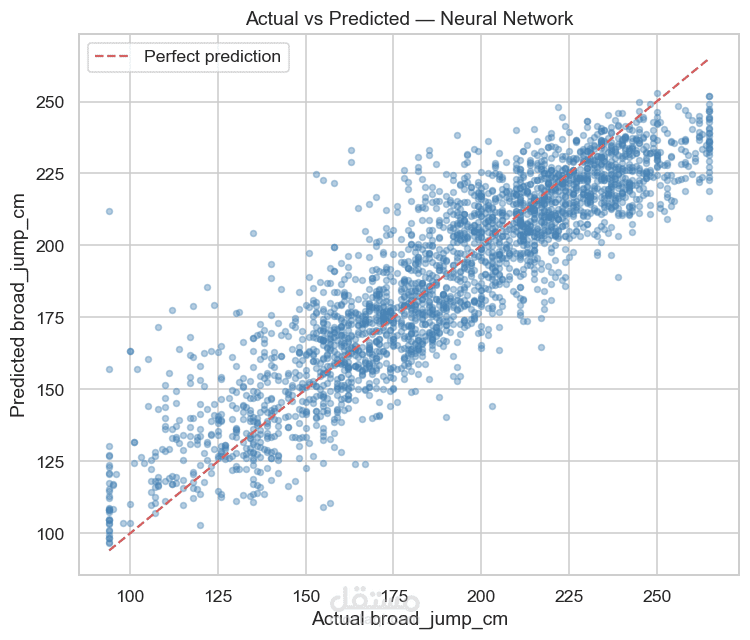
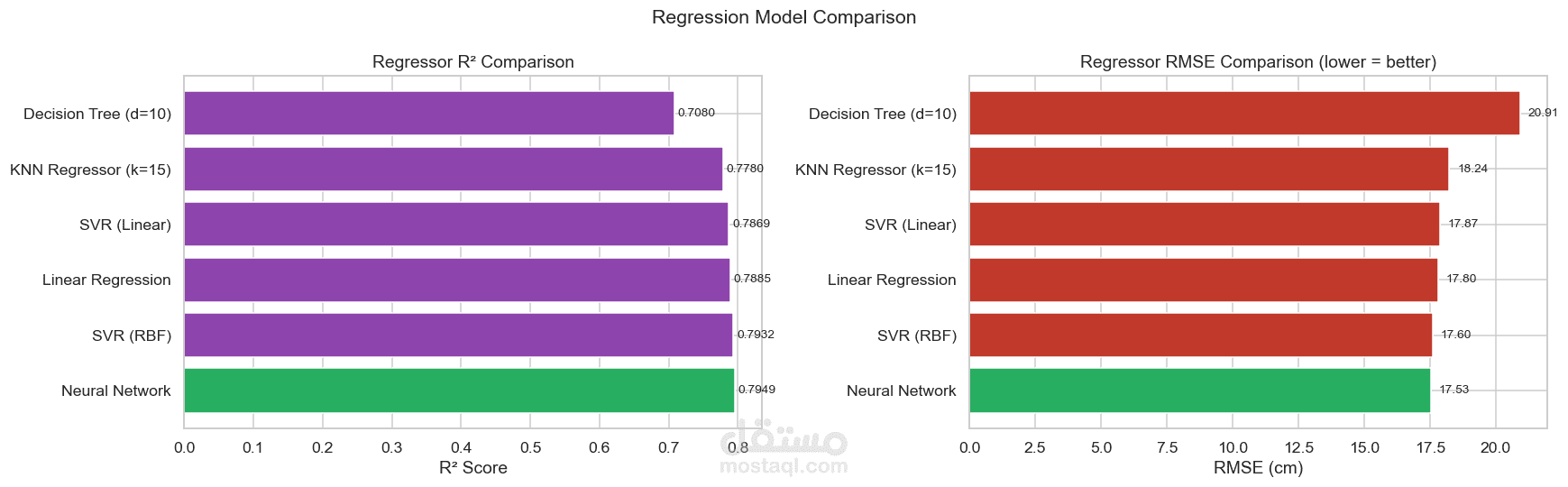
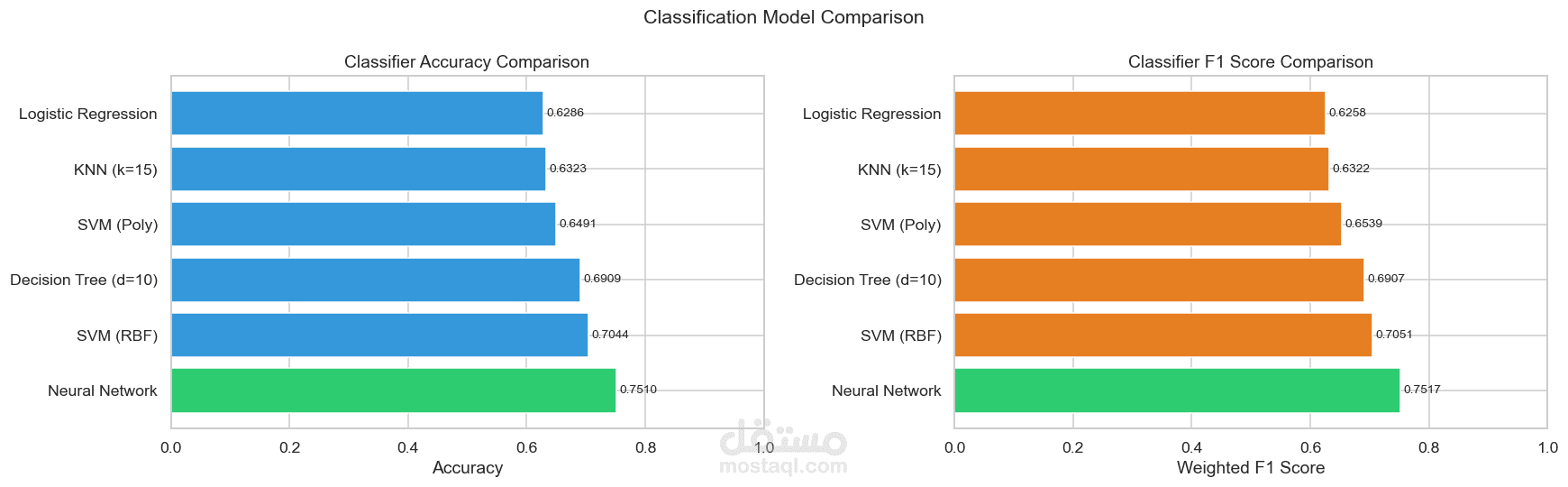
مقارنة أداء النماذج
نتائج المشروع
ساعد المشروع في:
فهم العلاقة بين القياسات البدنية ومستوى الأداء
بناء نموذج قادر على تصنيف مستوى الأداء البدني للأفراد
مقارنة عدة نماذج تعلم آلي واختيار الأفضل بينها
الأدوات المستخدمة في المشروع
تم تنفيذ المشروع باستخدام:
Python
Pandas
NumPy
Matplotlib
Seaborn
Scikit-learn
Jupyter Notebook
الهدف من المشروع
الهدف من المشروع هو استخدام تقنيات تحليل البيانات وتعلم الآلة لاستخراج رؤى مفيدة من بيانات الأداء البدني وبناء نموذج يمكنه التنبؤ بمستوى اللياقة البدنية للأفراد اعتمادًا على مجموعة من القياسات الصحية والبدنية.