Titanic-Passenger-Survival-Prediction
تفاصيل العمل
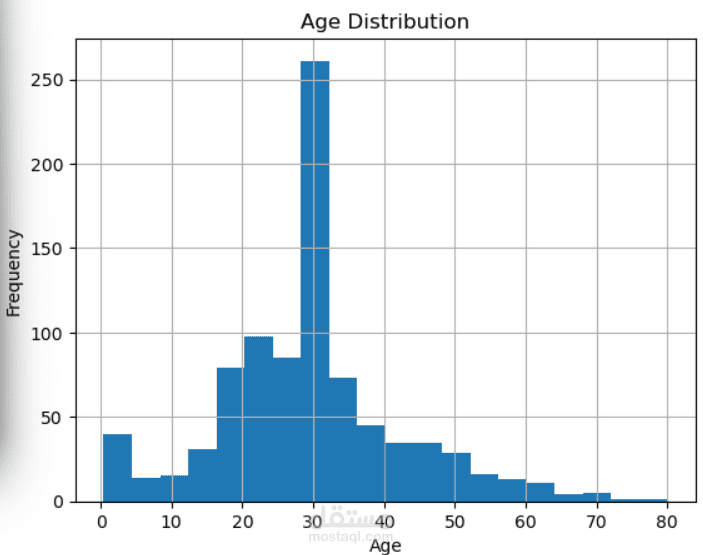
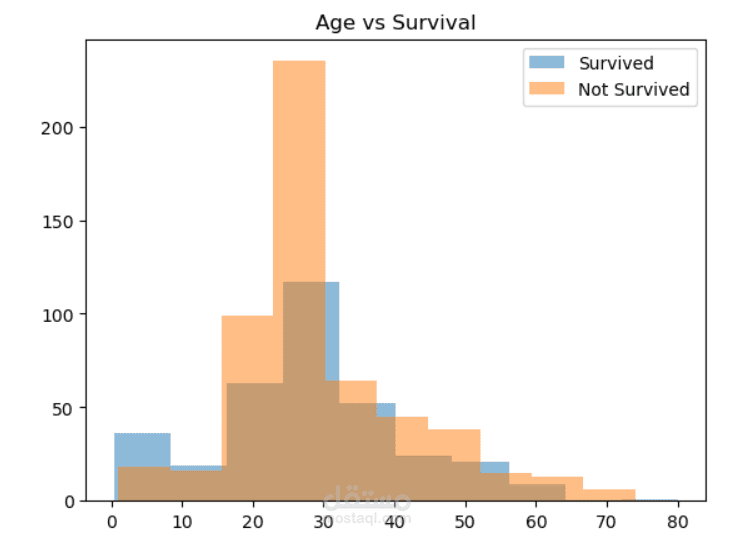
A Machine Learning project focused on binary classification to predict passenger survival on the Titanic based on available passenger data.
Key Features:
End-to-End ML Pipeline: Covers all stages from data collection to modelling:
Data acquisition
Data cleaning
Exploratory Data Analysis (EDA)
Feature engineering
Feature selection
Model training and evaluation
Smart Data Analysis: Handles missing values, encodes categorical features, and explores relationships between features and survival.
Multiple ML Models: Experiments with models like Logistic Regression, Random Forest, Gradient Boosting to select the best-performing one.
Performance Evaluation: Uses Accuracy, Precision, Recall, F1-score, and ROC-AUC metrics for robust model assessment.
Interpretable Predictions: Identifies feature importance to understand which factors most influence survival.
Implementation Steps:
Load Dataset: Use Titanic passenger data from Kaggle or official sources.
Explore Data: Analyse columns such as Age, Sex, Passenger Class, Sib S p, and Parch.
Data Cleaning:
Handle missing values (e.g., Age, Cabin).
Remove irrelevant columns (e.g., Name, Ticket).
Feature Engineering:
Create new features like family size (Sib Sp + Parch).
Extract titles from passenger names to capture social status.
Data Transformation: Encode categorical features using Label Encoding or One-Hot Encoding.
Train-Test Split: Divide data into training and testing sets.
Model Training: Train and compare multiple classification models to select the best.
Model Evaluation: Assess model performance using multiple metrics to ensure accuracy and reliability.
Prediction: Use the trained model to predict survival for new passengers.
Project Value:
Provides insights into factors influencing passenger survival on the Titanic.
The model can be applied to similar datasets for survival or outcome predictions.
A strong addition to your Portfolio, demonstrating skills in Data Preprocessing, Feature Engineering, Model Selection, and Evaluation.