SMS-Spam-Detection-Using-Machine-Learning
تفاصيل العمل
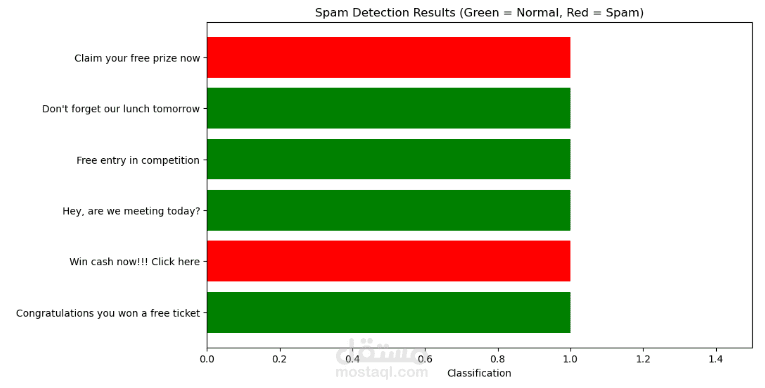
This project implements a complete machine learning pipeline to automatically classify SMS messages as spam or normal (ham). It addresses the real-world problem of filtering unwanted messages, improving user experience, and preventing potential phishing or promotional scams.
Key Features & Highlights:
Text Preprocessing: Cleans messages by removing punctuation, numbers, and stop words, and applies stemming to reduce word variations.
Feature Extraction: Converts text into numerical vectors using TF-IDF, capturing the importance of words in the messages.
Model Training: Uses Linear Support Vector Classifier (LinearSVC) for accurate classification of messages.
Model Evaluation: Measures performance using metrics such as accuracy, precision, recall, and F1-score to ensure reliable predictions.
Prediction Interface: Enables testing new messages to determine if they are spam, showcasing practical NLP applications.
Data Insights: Helps understand common patterns in spam messages and key indicators that differentiate spam from normal messages.
Implementation Approach:
Load and inspect the dataset of SMS messages labelled as spam or ham.
Preprocess the text: lowercase conversion, removing special characters, stop words elimination, and stemming.
Transform messages into TF-IDF features for modeling.
Split data into training and testing sets for model evaluation.
Train a Linear SVC model and validate its performance on unseen messages.
Test new SMS examples to demonstrate the model’s ability to classify messages in real time.
This project demonstrates practical applications of natural language processing (NLP) and supervised machine learning for automated content filtering and spam detection, making it suitable for real-world communication platforms