مشروع متكامل لتحويل البيانات الخام (Raw Data) إلى بيانات جاهزة للتحليل الإحصائي.
تفاصيل العمل

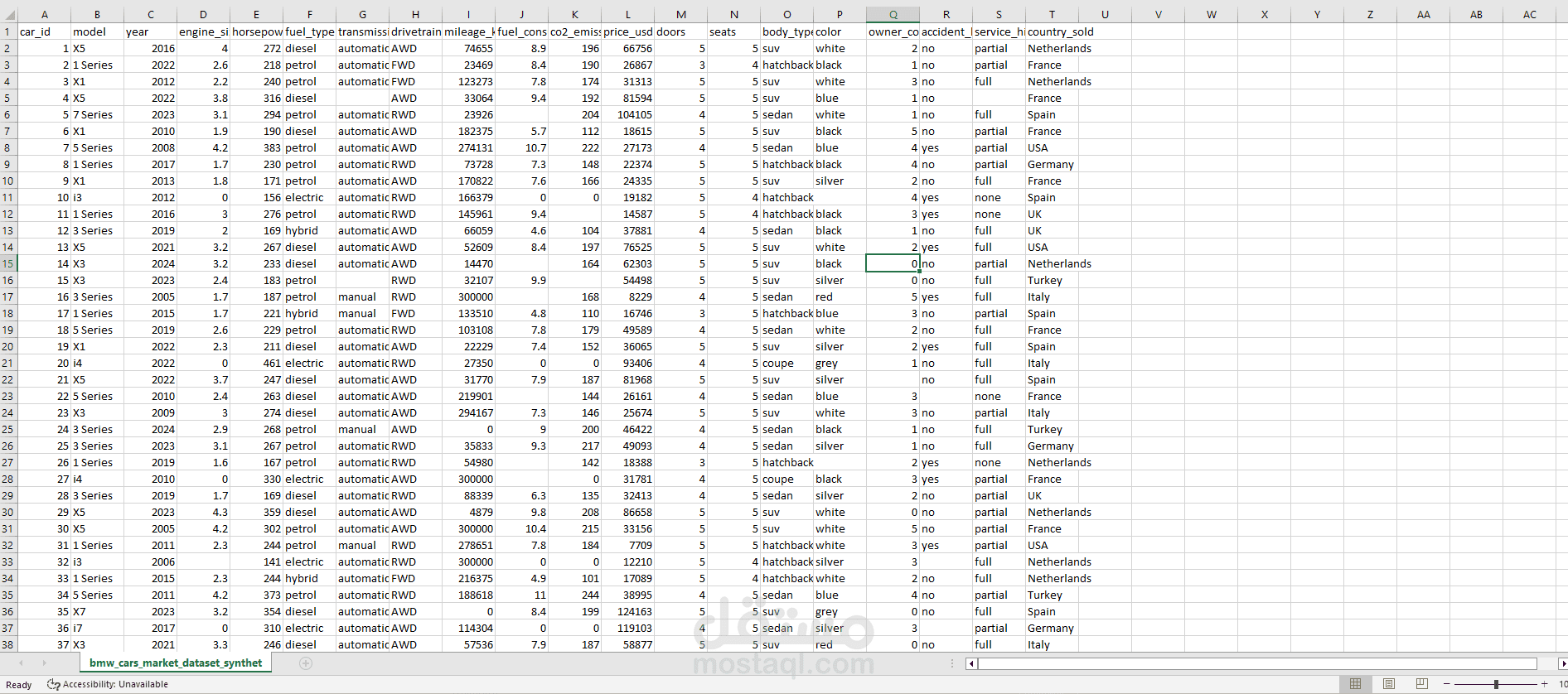
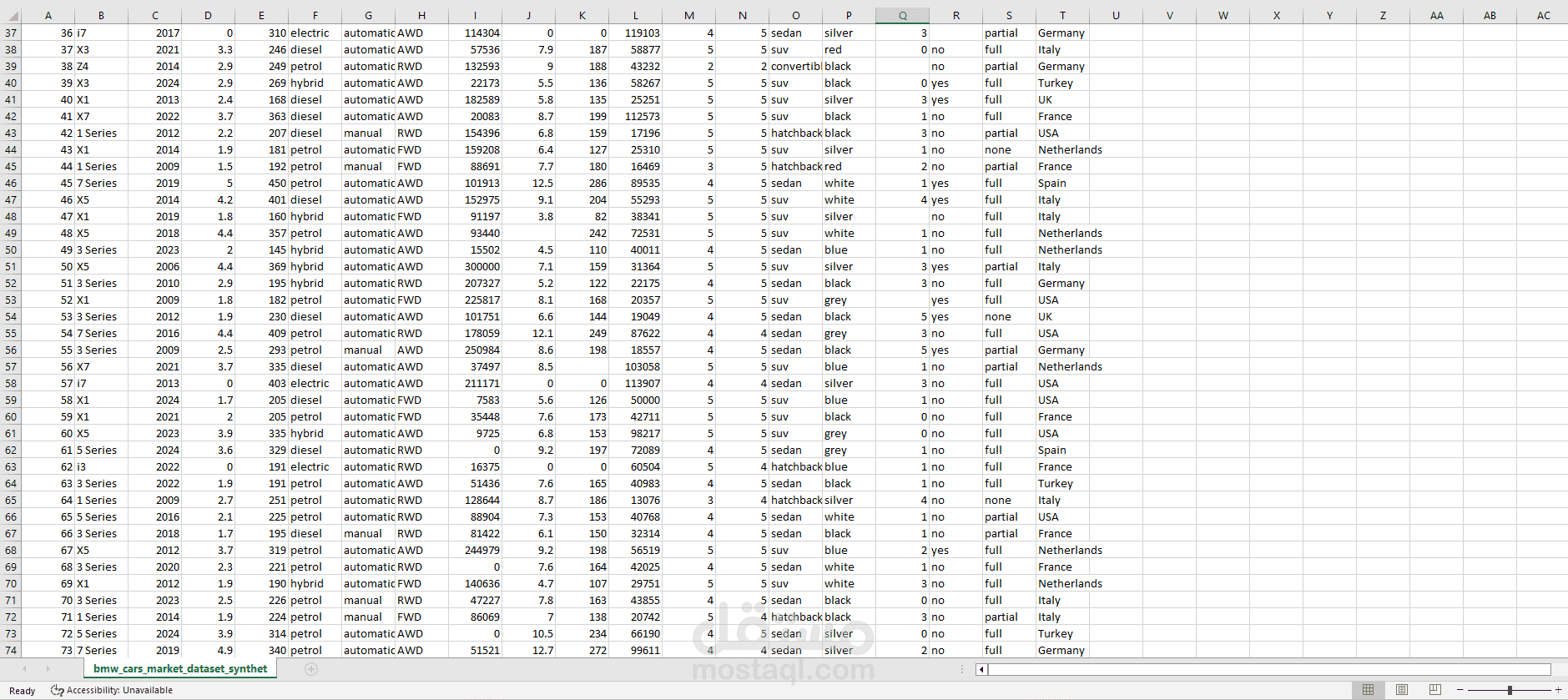
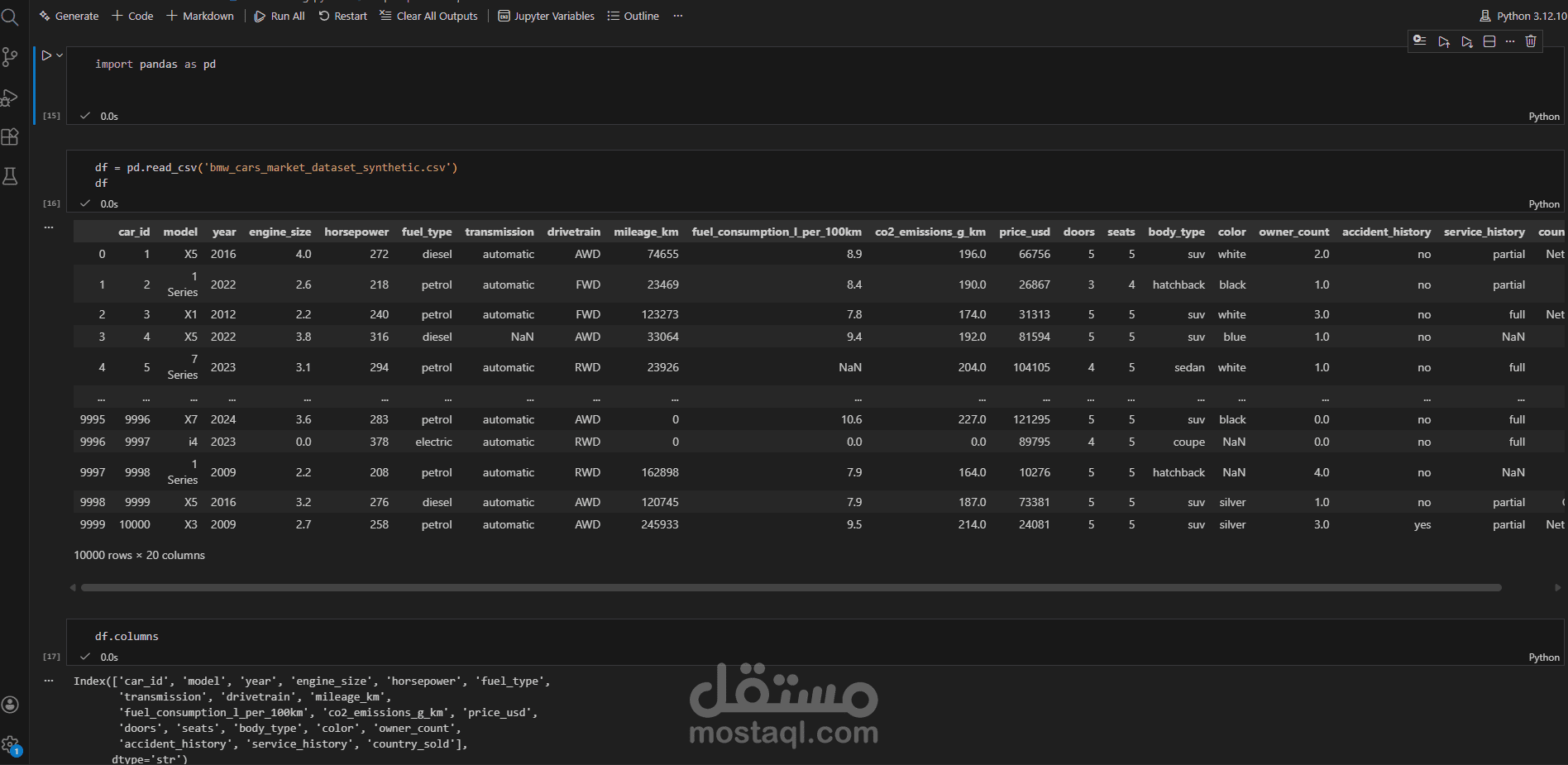
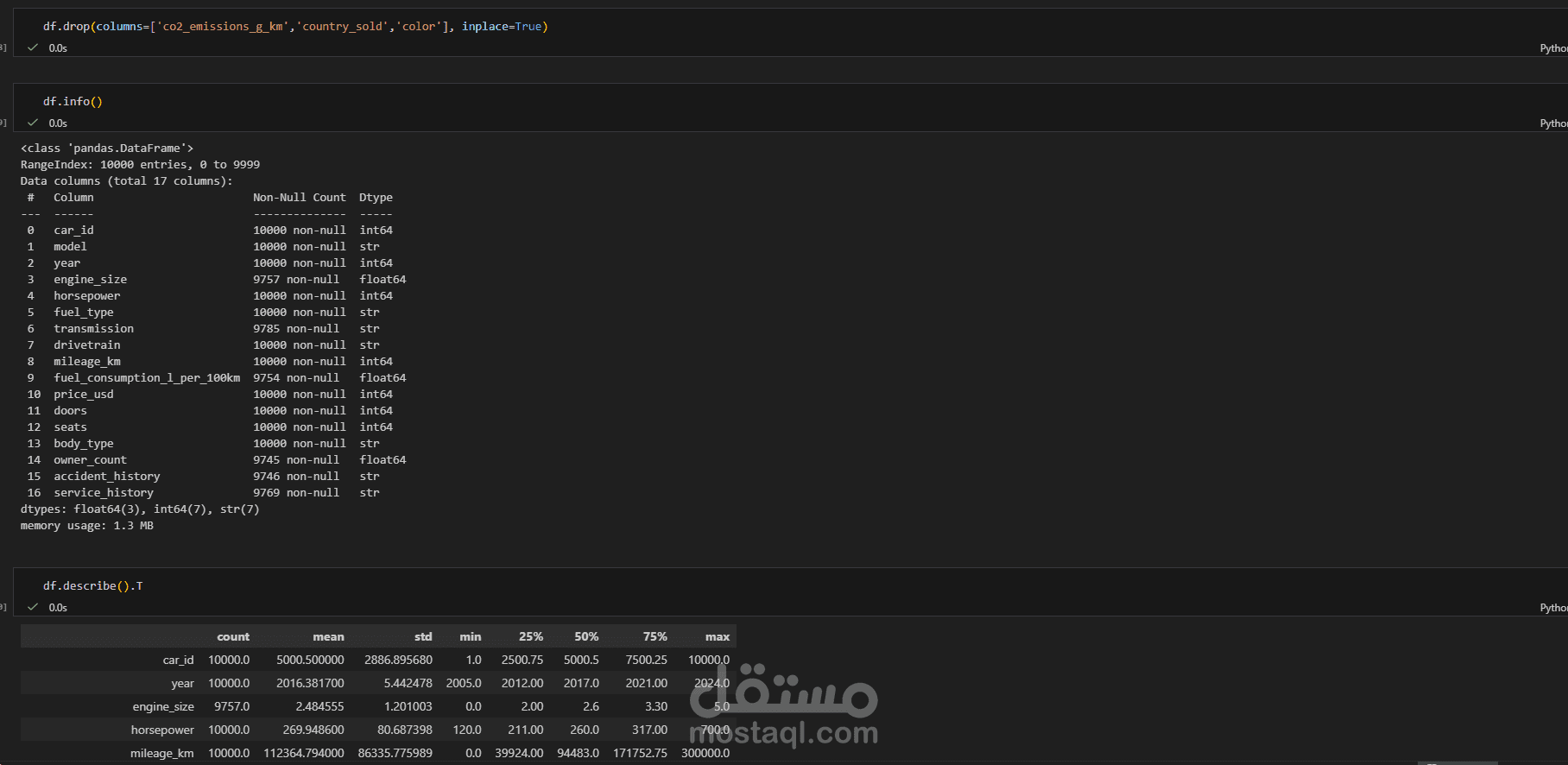
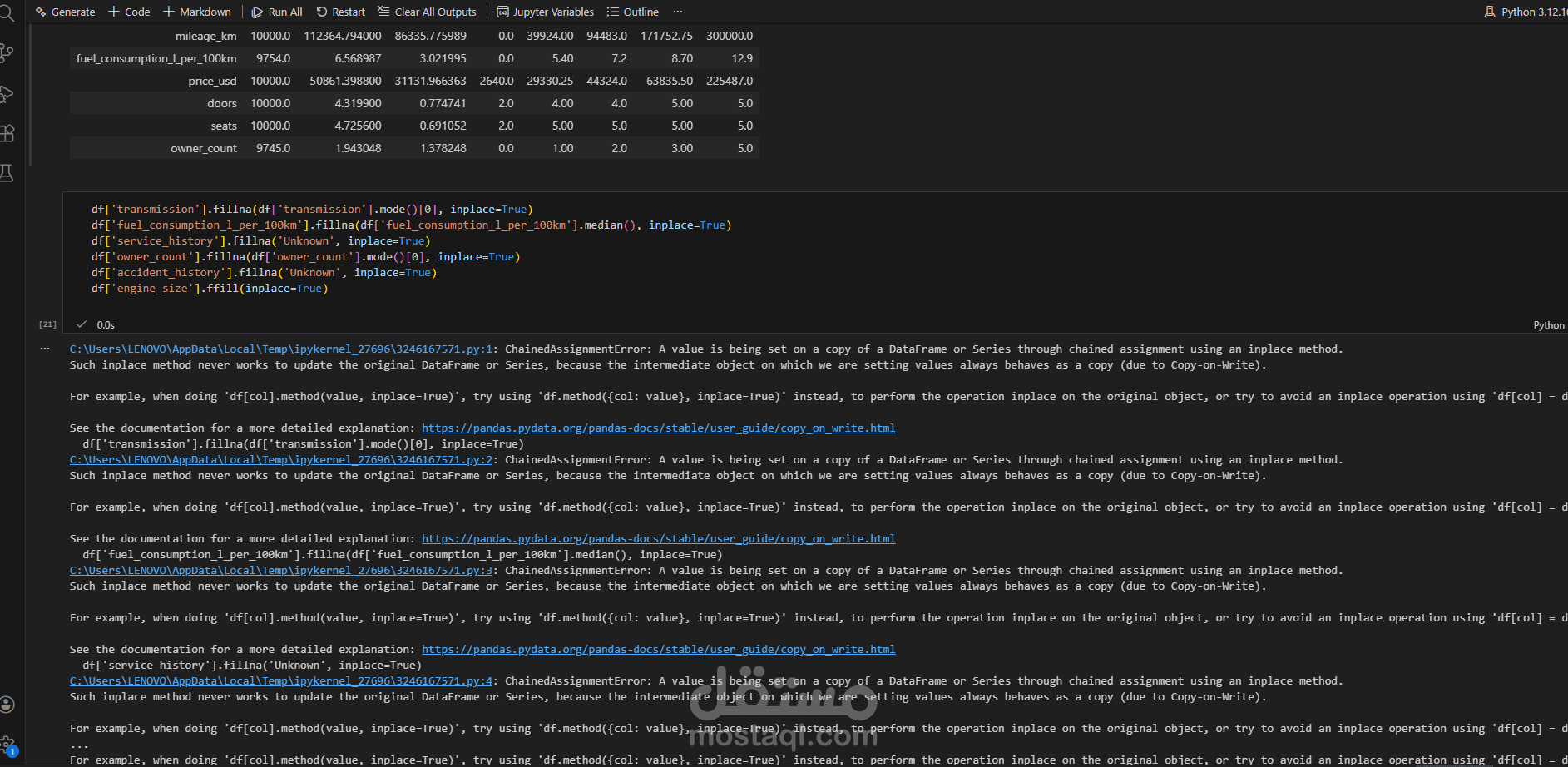
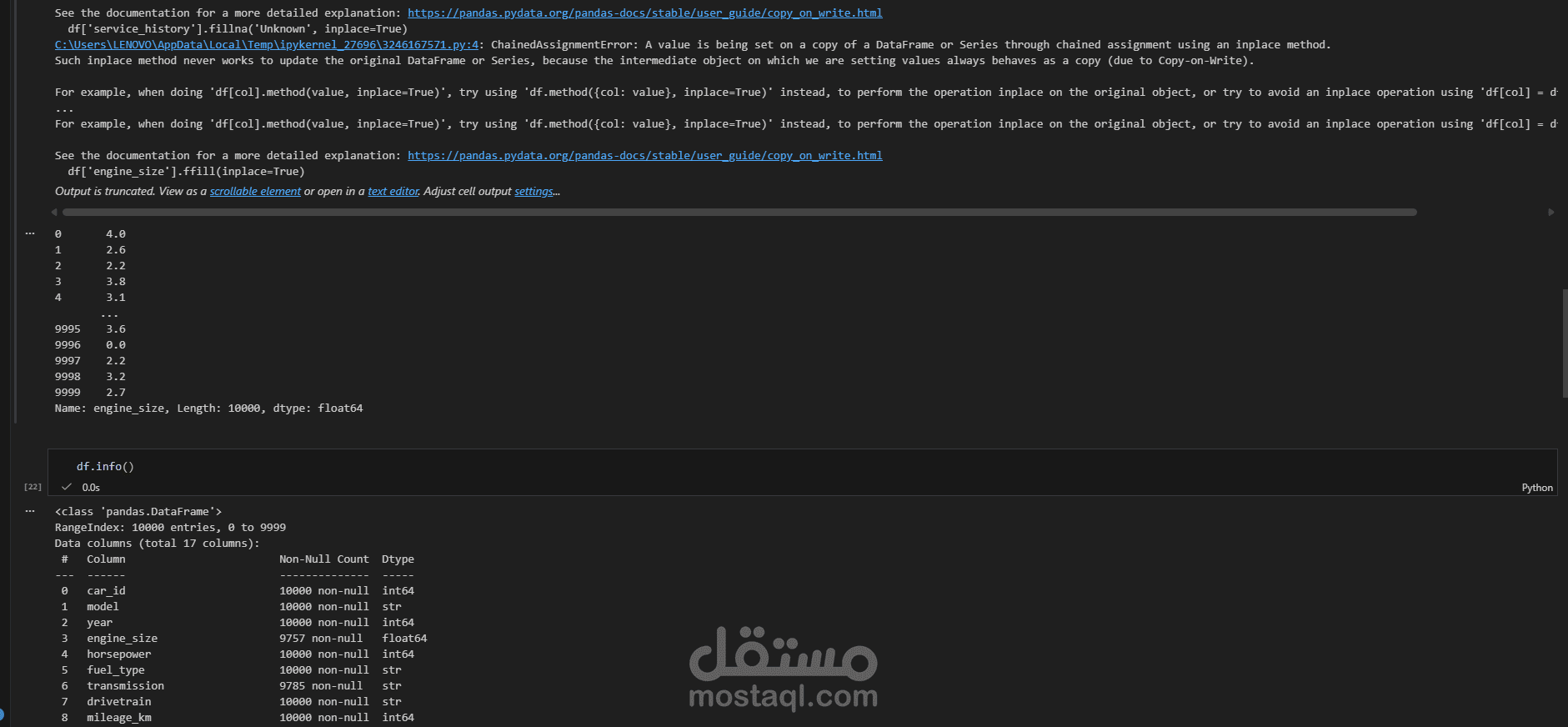
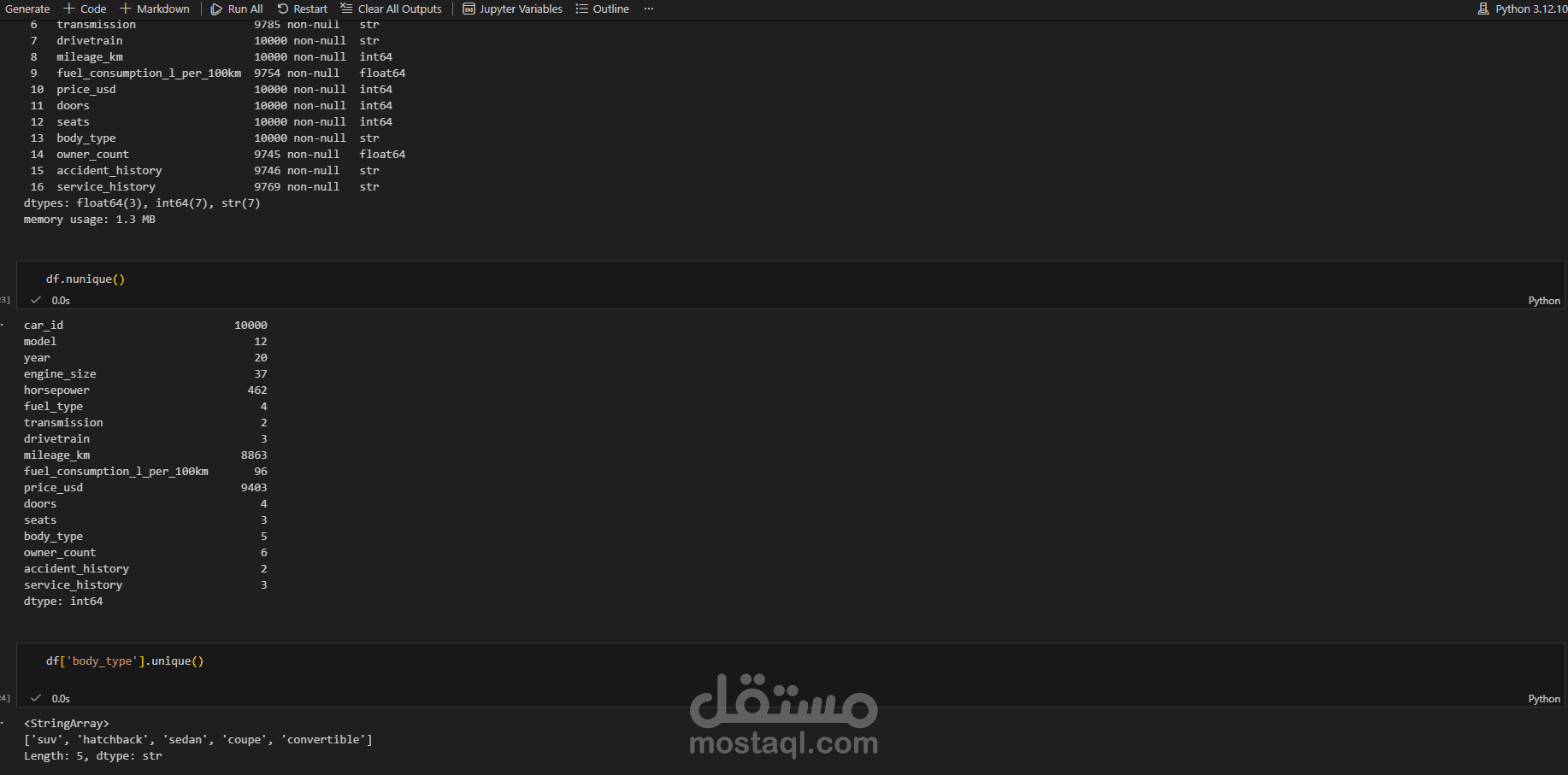
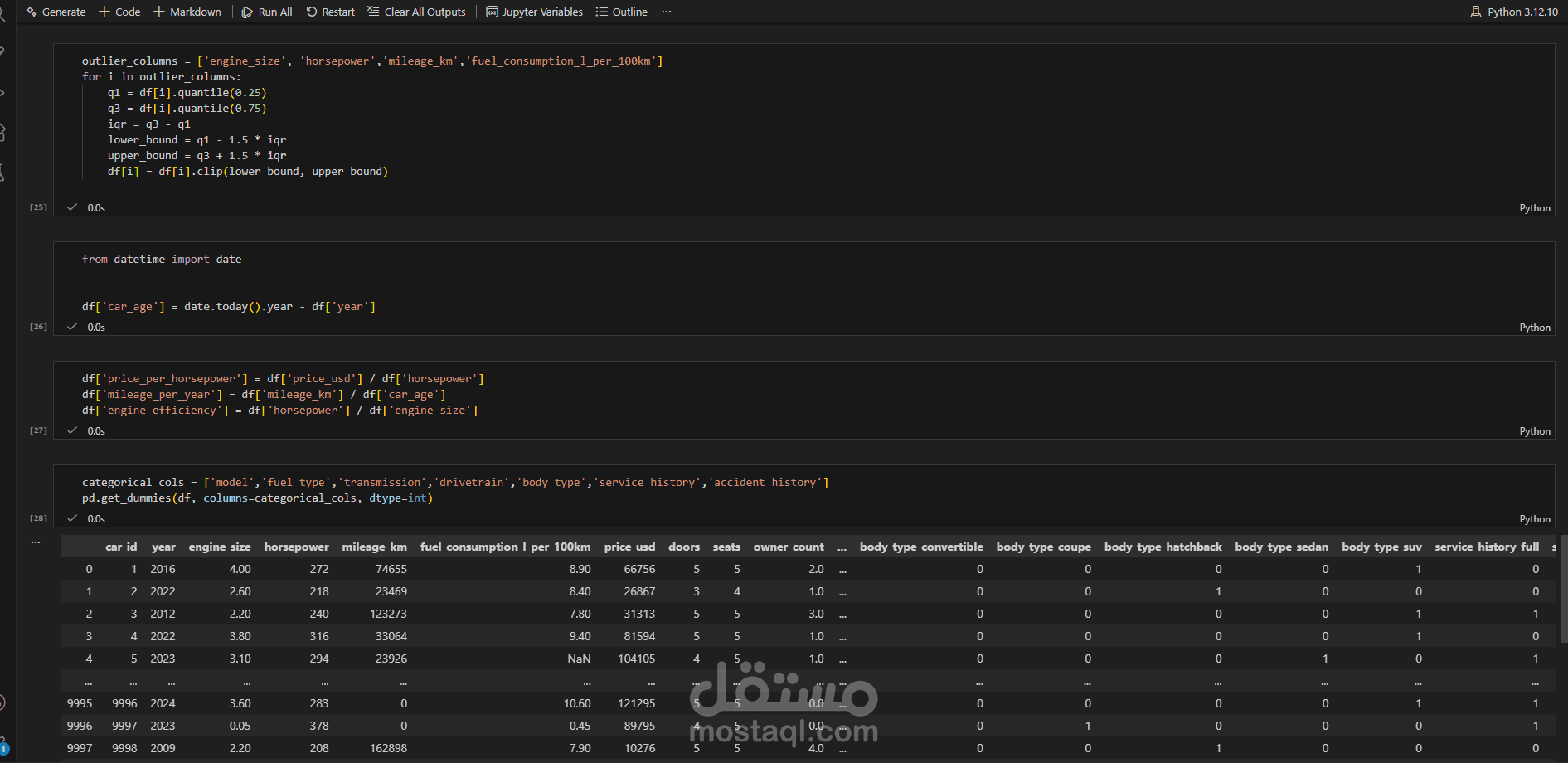
يتناول هذا المشروع مرحلة "هندسة البيانات" (Data Engineering) لمجموعة بيانات خاصة بسوق سيارات BMW. الهدف الأساسي هو تحويل مجموعة بيانات تحتوي على أخطاء، قيم مفقودة، وتنسيقات غير صحيحة إلى قاعدة بيانات نظيفة واحترافية يمكن استخدامها في اتخاذ قرارات تجارية أو بناء نماذج تنبؤ بالأسعار.
المميزات التقنية التي تم تنفيذها في المشروع:
استكشاف البيانات (Exploration): فحص أولي للبيانات لتحديد الأعمدة غير الضرورية، القيم المكررة، ونسبة البيانات المفقودة.
معالجة البيانات المفقودة (Handling Missing Values): التعامل مع الفراغات في البيانات سواء بالحذف أو التعويض (Imputation) لضمان عدم تأثر النتائج النهائية.
تصحيح أنواع البيانات (Data Type Conversion): تحويل الأعمدة من نصوص إلى أرقام أو تواريخ (مثل تحويل سنة التصنيع أو السعر) لتمكين العمليات الحسابية.
هندسة الميزات (Feature Engineering): إنشاء أعمدة جديدة مستخرجة من البيانات الحالية لتحسين جودة التحليل، وتعديل تنسيقات النصوص لتكون موحدة.
إزالة الضوضاء (Noise Removal): حذف البيانات الشاذة أو المكررة التي قد تؤدي إلى تضليل التحليل الإحصائي.
النتائج المحققة:
تحويل ملف CSV خام يحتوي على بيانات غير مرتبة إلى ملف نظيف بنسبة 100%.
توفير رؤية واضحة عن متوسط الأسعار، سنوات الصنع، وحالة السيارات بعد معالجة الأخطاء الإملائية والتقنية في البيانات.
تجهيز البيانات لتكون متوافقة تماماً مع خوارزميات تعلم الآلة (Machine Learning Ready).
التقنيات المستخدمة:
Pandas: الأداة الأساسية لمعالجة الجداول وهيكلة البيانات.
NumPy: للتعامل مع العمليات الحسابية والقيم المفقودة (NaN).
Jupyter Notebook: لتوثيق خطوات العمل وضمان إمكانية تكرار التجربة.