Data Cleaning & Preprocessing لبيانات سيارات باستخدام بايثون
تفاصيل العمل

تنظيف ومعالجة بيانات سوق سيارات BMW باستخدام Python
مواقع بيع السيارات بتتعامل مع كميات ضخمة من البيانات يومياً، وعشان البيانات دي تكون مفيدة فعلاً في تحديد الأسعار أو توقع المبيعات، لازم تكون "نضيفة" ومترتبة صح، لأن البيانات الخام (Raw Data) غالباً بتكون مليانة أخطاء وقيم ناقصة.
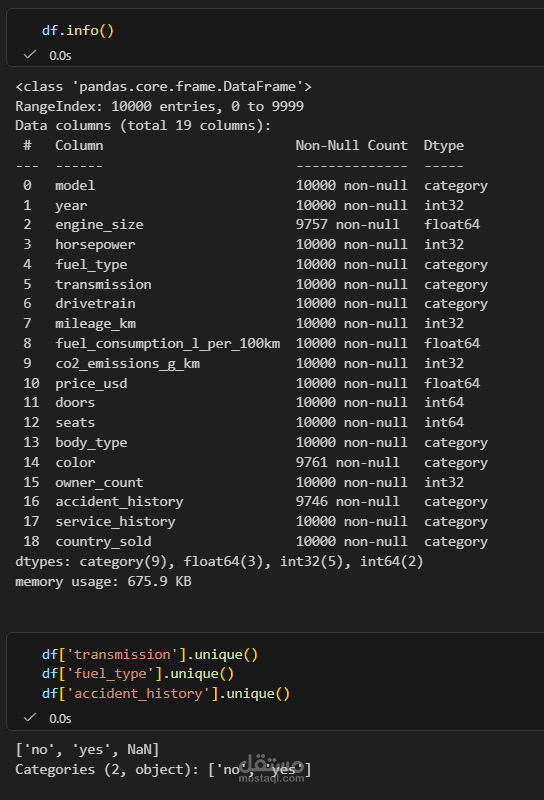
لذلك قمت بتنفيذ مشروع كامل لتجهيز ومعالجة مجموعة بيانات (Dataset) لسيارات BMW تحتوي على 10,000 سجل، باستخدام لغة Python ومكتبة Pandas، لضمان أعلى جودة للبيانات قبل مرحلة التحليل.
الخطوات التقنية التي تم تنفيذها:
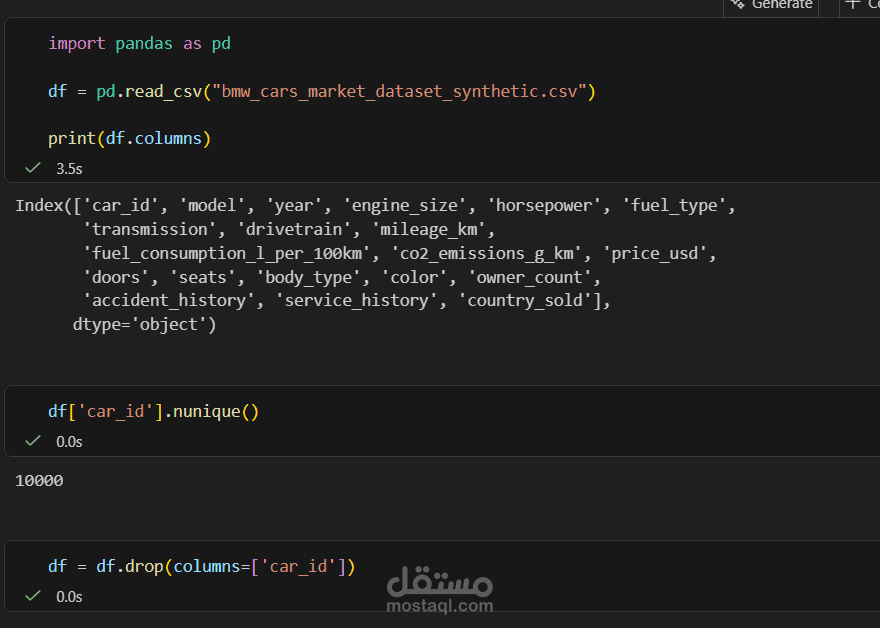
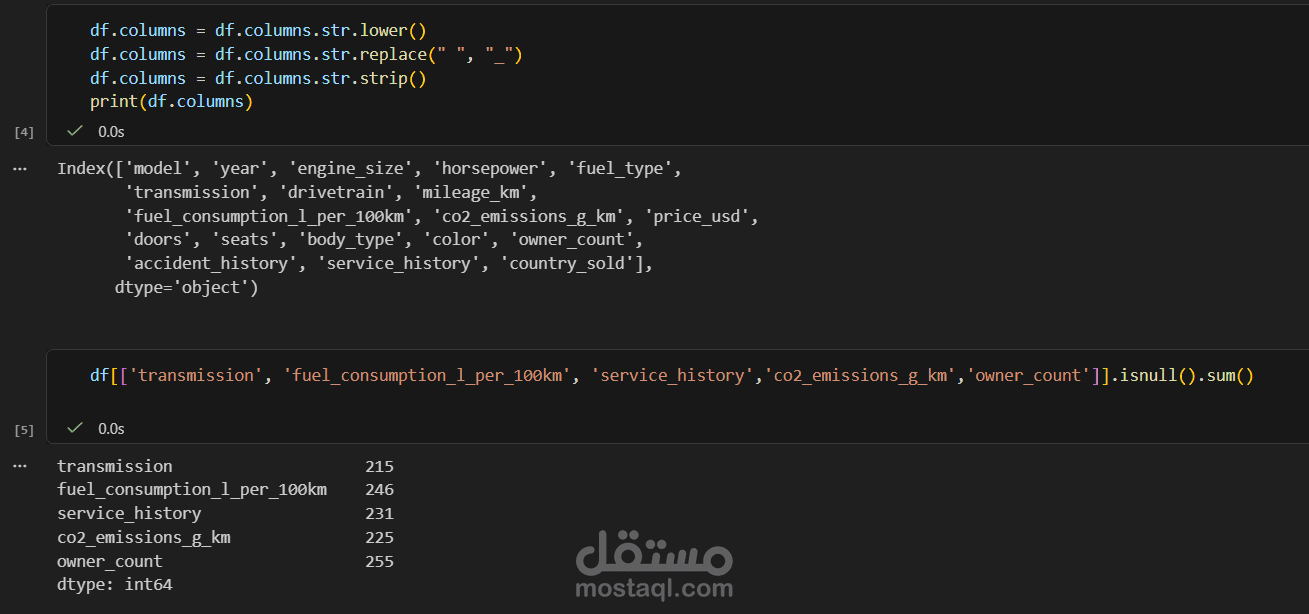
هيكلة وتنظيف الأعمدة: قمت بتوحيد أسامي الأعمدة كلها (Lower Case) واستبدال المسافات بـ (Underscores) عشان الكود يشتغل بسلاسة.
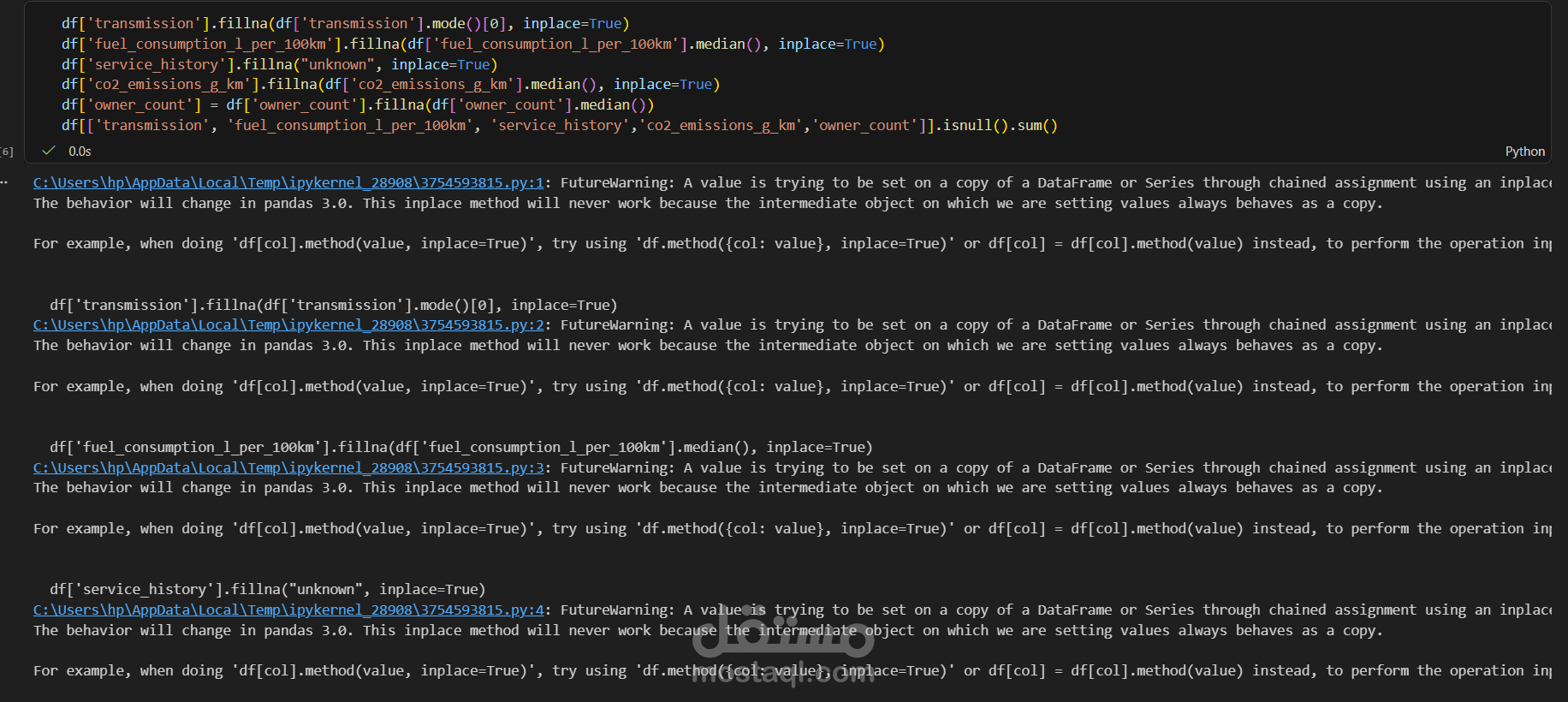
إدارة القيم المفقودة (Handling Nulls): بدل ما أمسح بيانات مهمة، استخدمت الـ (Median) والـ (Mode) لملء الخانات الفاضية بناءً على نوع كل عمود.
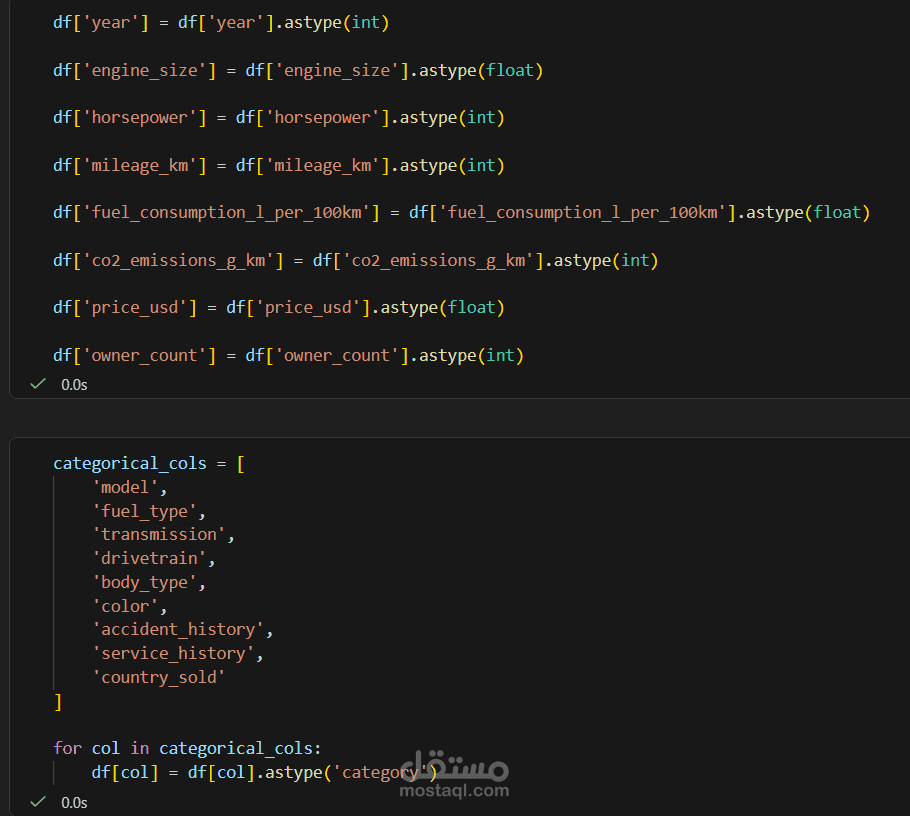
تجهيز وتحويل أنواع البيانات: حولت الأعمدة لأرقام ونصوص وفئات (Categories) عشان أقلل استهلاك الذاكرة وأسرع المعالجة.
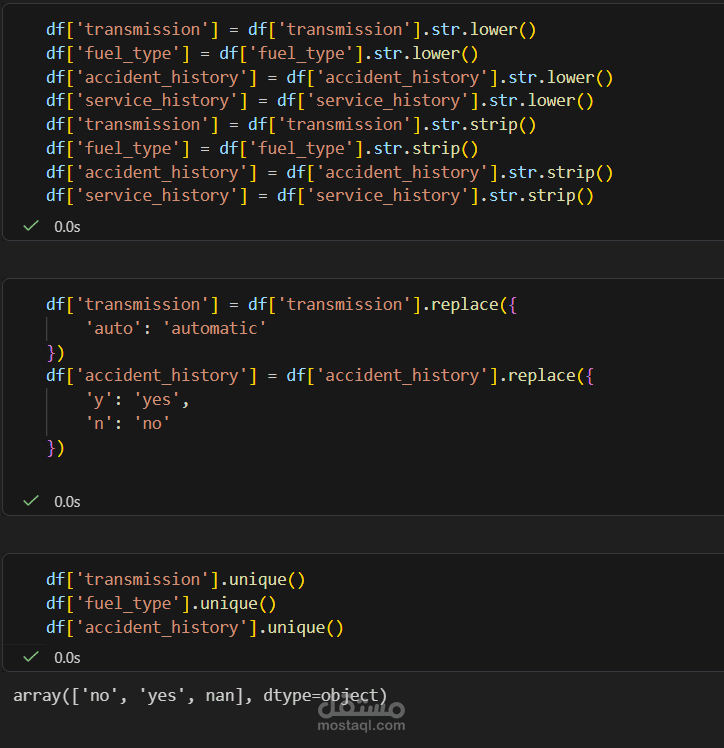
توحيد المسميات النصية: نظفت النصوص من المسافات الزيادة ووحدت المصطلحات (زي تحويل 'y' لـ 'yes' و 'auto' لـ 'automatic') عشان ميبقاش فيه تكرار وهمي.
الاستعلامات والعمليات المنفذة على البيانات:
حسابات إحصائية: استخراج Median و Mode لمعالجة القيم المفقودة بدقة.
تحسين الذاكرة (Memory Optimization): تقليل حجم البيانات في الرامات بنسبة كبيرة جداً.
فلترة البيانات: التأكد من فرادة المعرفات (Unique IDs) وحذف الأعمدة غير المؤثرة في التحليل.
النتيجة:
تم الوصول لـ Dataset احترافية بنسبة أخطاء 0%، واستهلاك ذاكرة أقل بنسبة تزيد عن 50% (من 1.4 MB إلى 675 KB)، مما يجعلها جاهزة فوراً لعمليات التحليل الإحصائي أو بناء نماذج التنبؤ بالأسعار (Machine Learning).