Web Scraping Project using Python
تفاصيل العمل
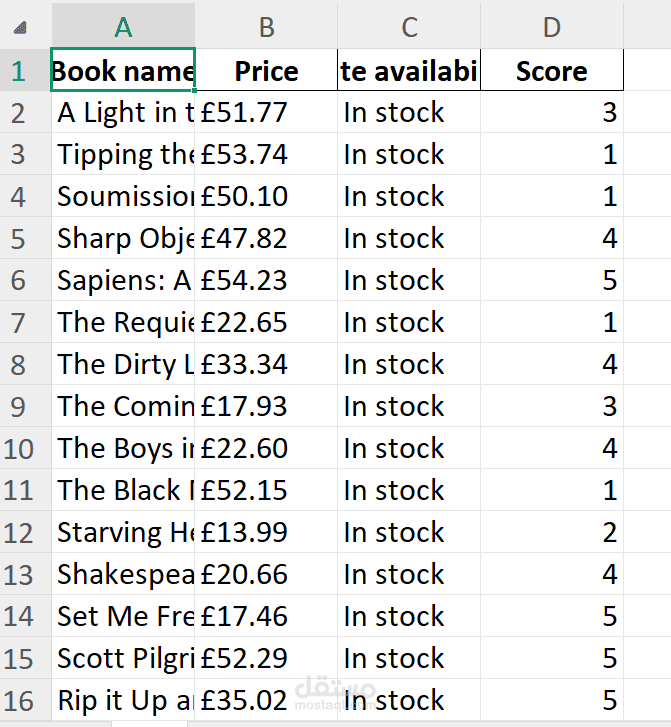
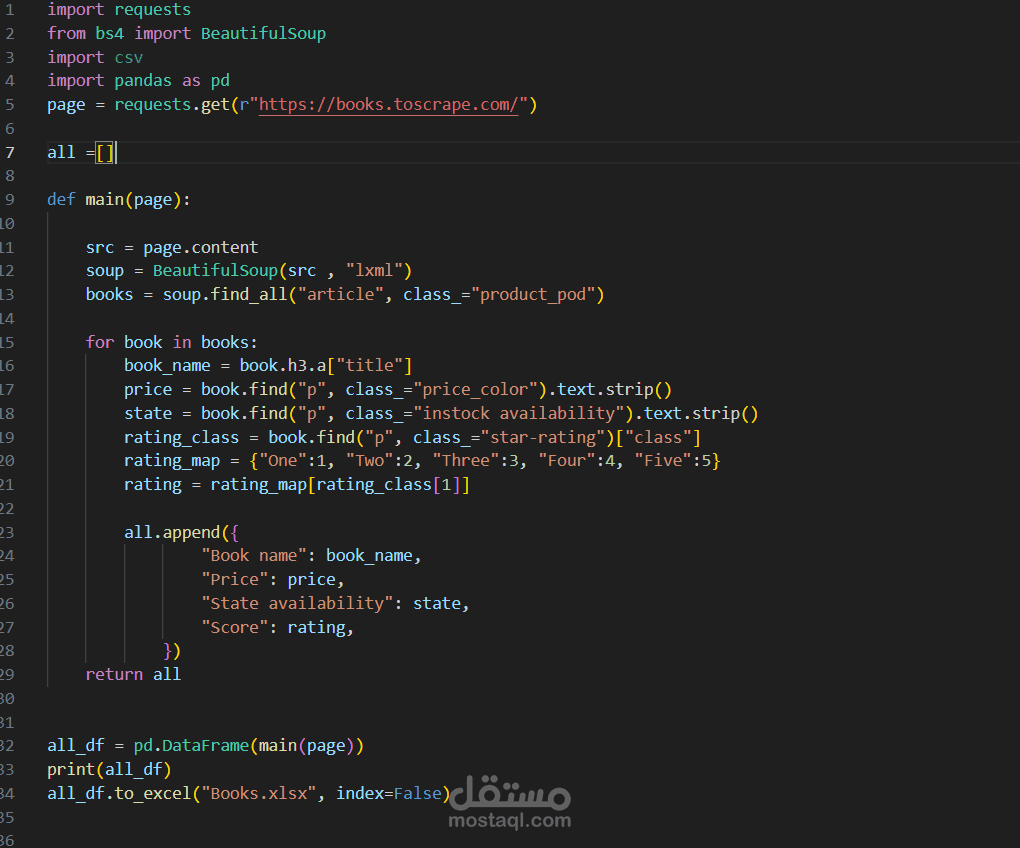
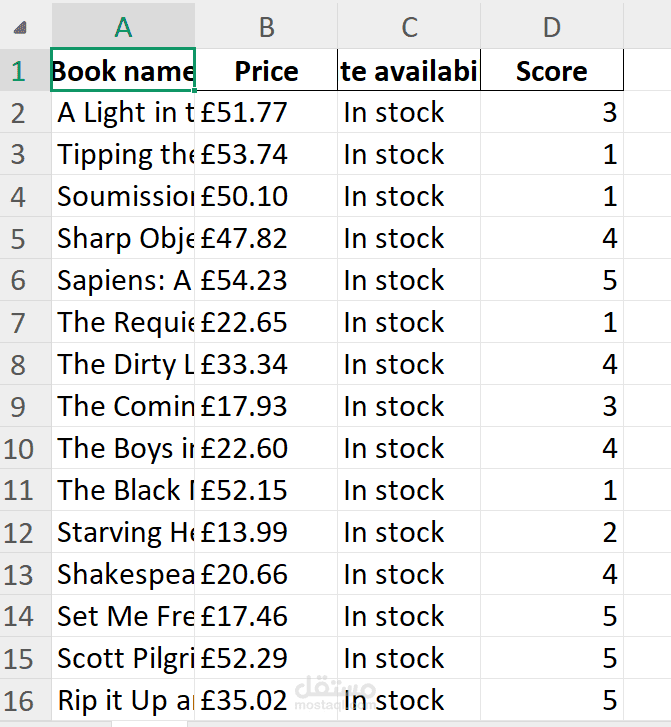
استخراج بيانات الكتب من موقع إلكتروني باستخدام بايثون (Web Scraping)
تحتوي مواقع بيع الكتب على عدد كبير من الكتب، وكل كتاب يحتوي على معلومات مهمة مثل اسم الكتاب، السعر، حالة التوفر، وتقييم الكتاب. جمع هذه البيانات يدويًا يستغرق وقتًا طويلًا ويكون غير عملي خاصة عند التعامل مع عدد كبير من الصفحات.
لذلك قمت بتطوير برنامج Web Scraping باستخدام لغة Python يقوم باستخراج بيانات الكتب بشكل تلقائي من موقع بيع كتب يقوم البرنامج بالدخول إلى صفحات الموقع وتحليل بنية الصفحة واستخراج المعلومات المطلوبة بدقة.
الأدوات والتقنيات المستخدمة:
Python
مكتبة Requests
مكتبة BeautifulSoup
مكتبة Pandas
طريقة التنفيذ:
يقوم البرنامج بإرسال طلبات إلى الموقع للحصول على محتوى الصفحات، ثم يتم تحليل كود الـ HTML باستخدام مكتبة BeautifulSoup لاستخراج البيانات المطلوبة لكل كتاب، وتشمل:
اسم الكتاب
سعر الكتاب
حالة التوفر (متوفر أو غير متوفر)
تقييم الكتاب
بعد ذلك يتم تنظيم البيانات باستخدام مكتبة Pandas وتحويلها إلى جدول منظم يسهل التعامل معه وتحليله.
النتيجة:
تم إنشاء Dataset نظيفة ومنظمة تحتوي على جميع بيانات الكتب التي تم استخراجها، ويمكن حفظها في ملفات مثل CSV أو Excel لاستخدامها لاحقًا في تحليل البيانات أو بناء نماذج تعلم الآلة.