تحليل المشاعر لمراجعات الأفلام باستخدام تقنيات معالجة اللغة الطبيعية
تفاصيل العمل
نوع العمل: معالجة اللغة الطبيعية (NLP)
في هذا المشروع قمت ببناء نموذج تعلم آلة لتحليل مشاعر مراجعات الأفلام وتصنيفها إلى مراجعات إيجابية أو سلبية باستخدام تقنيات معالجة اللغة الطبيعية.
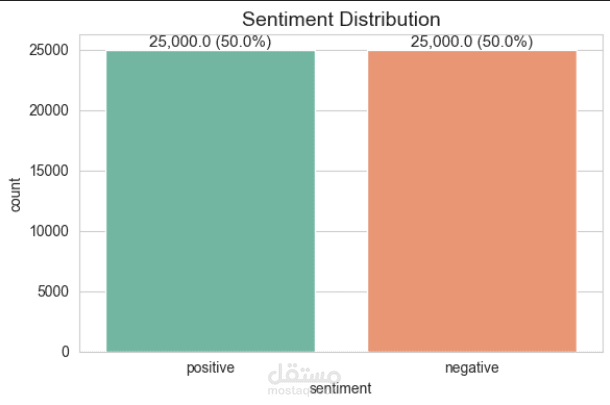
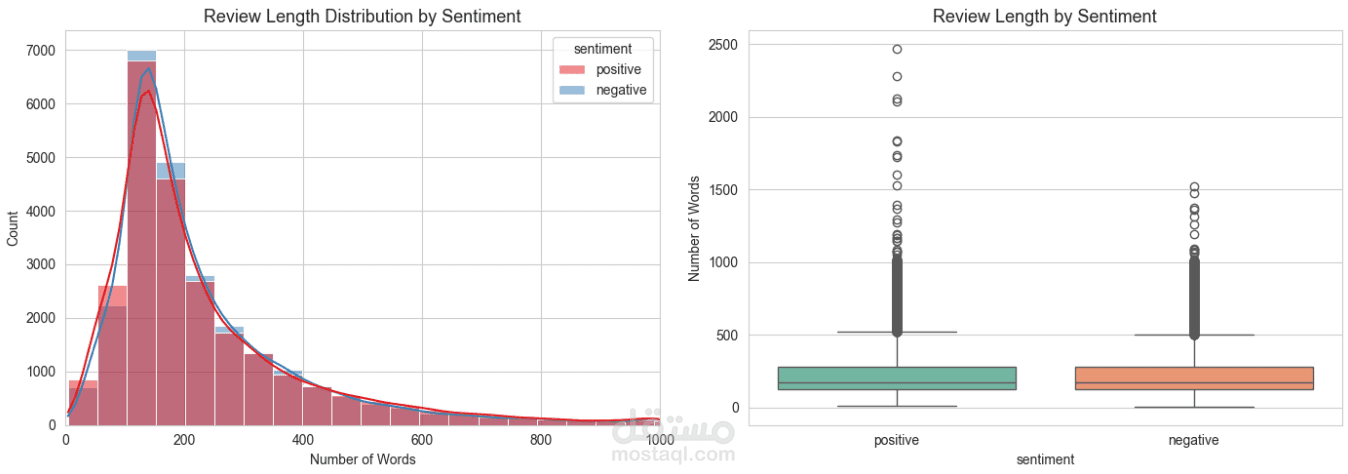
يعتمد المشروع على مجموعة بيانات تحتوي على 50,000 مراجعة أفلام من موقع IMDB.
تم تنفيذ المشروع عبر عدة مراحل رئيسية:
تنظيف النصوص باستخدام تقنيات Text Preprocessing مثل:
إزالة الرموز غير المهمة
إزالة الكلمات الشائعة (Stopwords)
تطبيق Stemming لتوحيد الكلمات
تحويل النصوص إلى تمثيل رقمي باستخدام تقنيات:
TF-IDF Vectorization
Count Vectorization
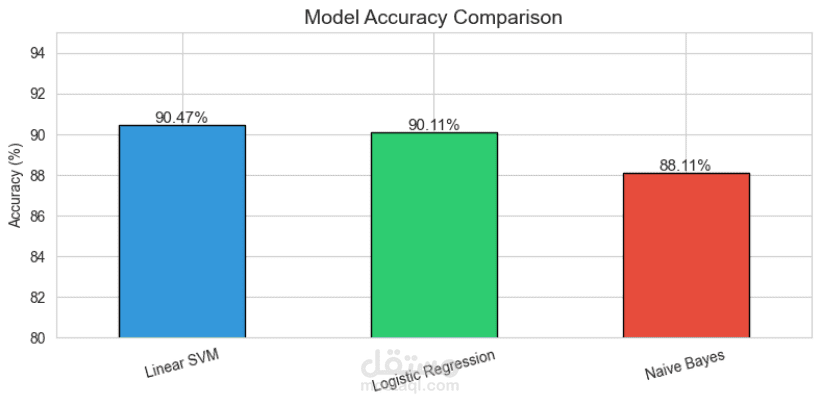
تدريب عدة نماذج تصنيف للمقارنة بينها مثل:
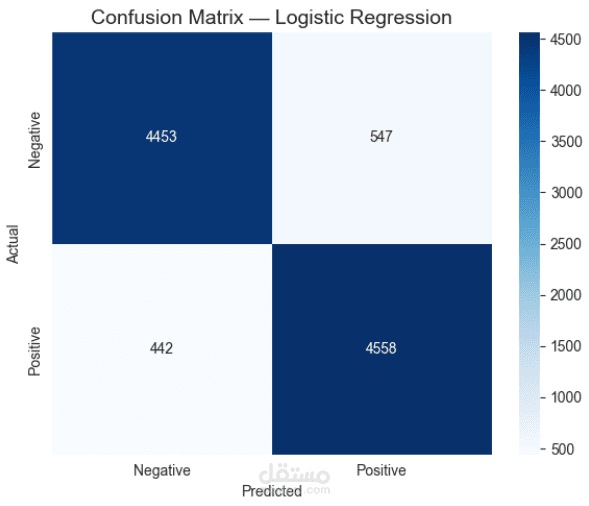
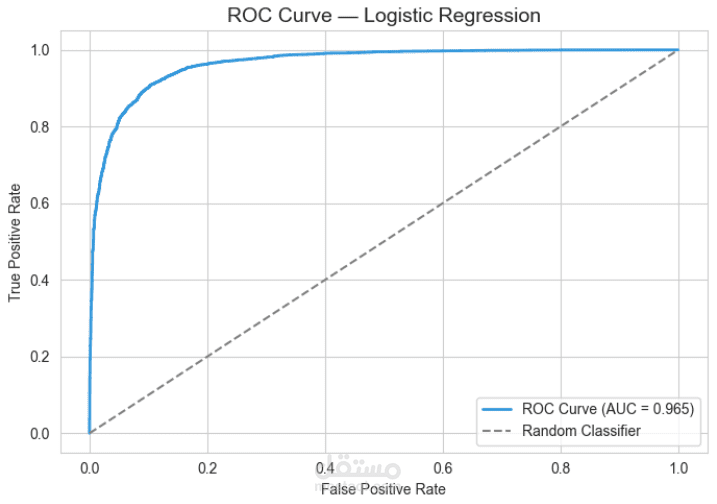
Logistic Regression
Naive Bayes
Support Vector Machine
Random Forest
Gradient Boosting
تقييم أداء النماذج باستخدام المقاييس التالية:
Accuracy
Precision
Recall
F1-score
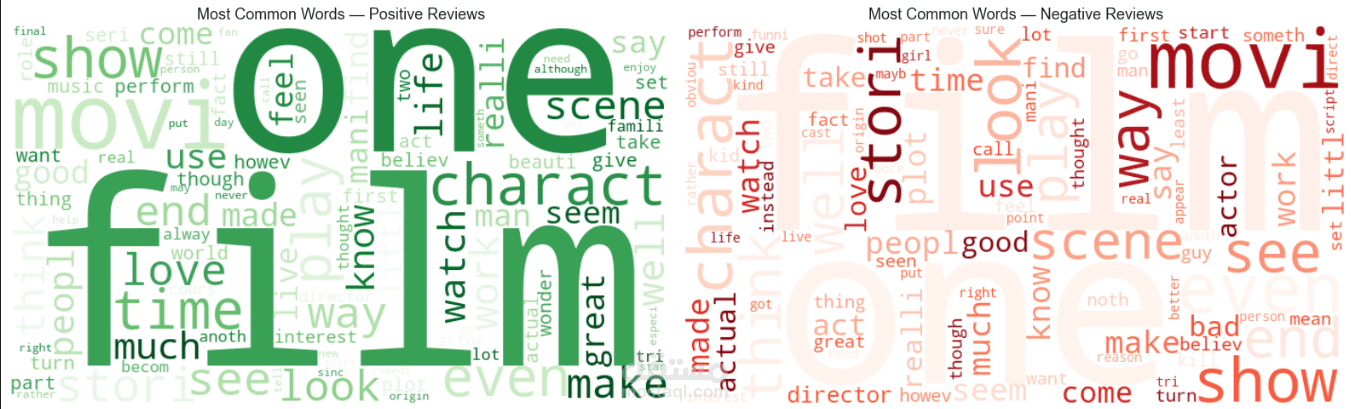
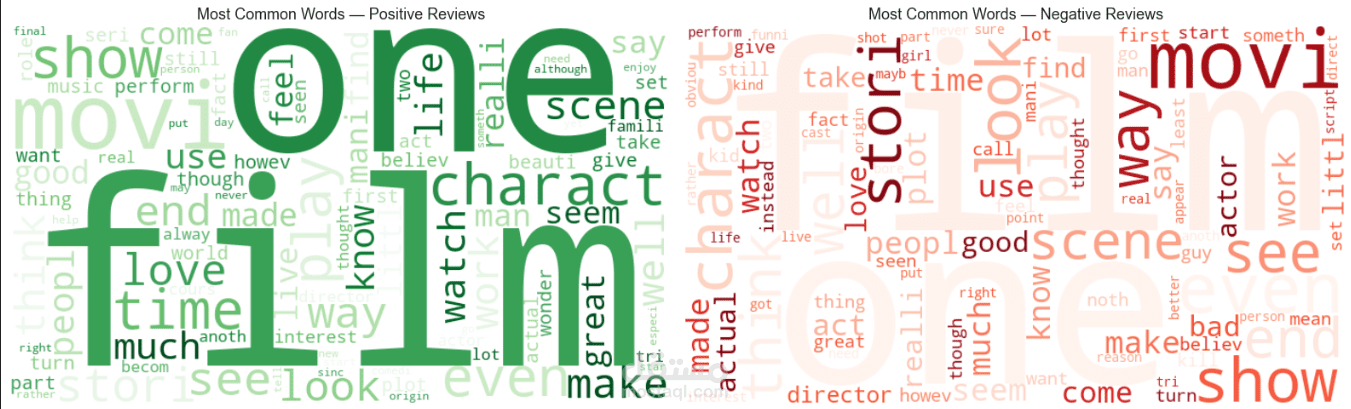
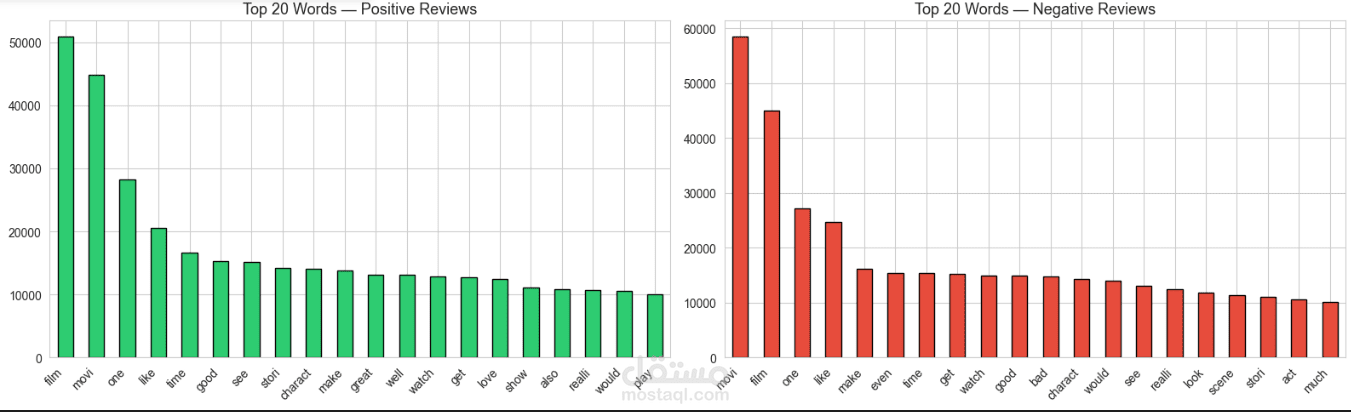
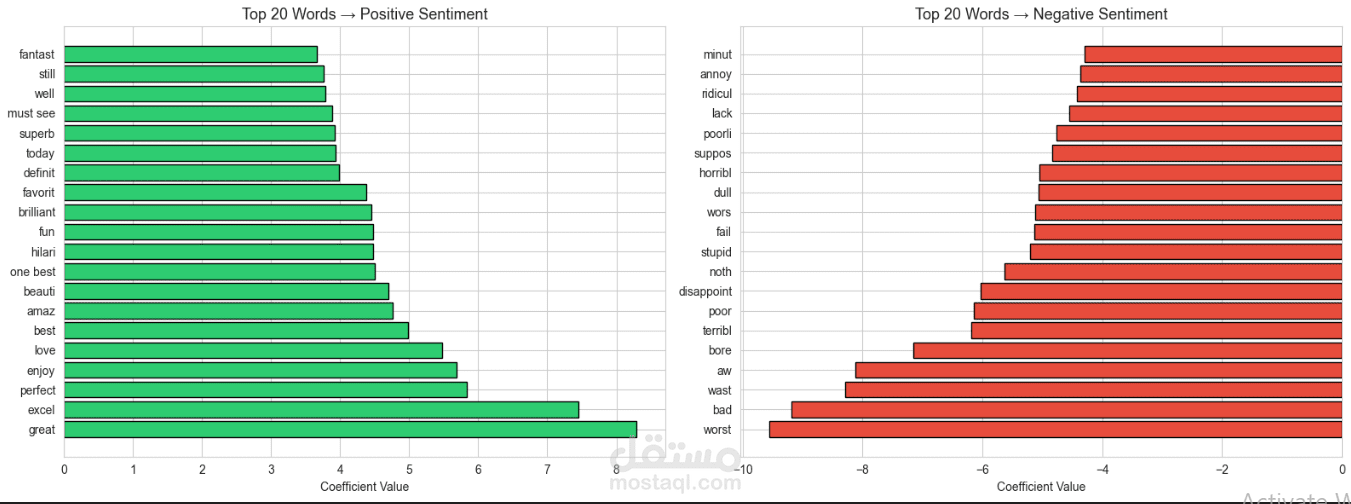
كما تم استخدام أدوات visualization مثل WordCloud لتحليل الكلمات الأكثر استخدامًا في المراجعات.
يوضح هذا المشروع القدرة على:
تحليل البيانات النصية
استخدام تقنيات معالجة اللغة الطبيعية
بناء نماذج تصنيف للنصوص
تقييم أداء النماذج وتحليل النتائج
الأدوات المستخدمة:
Python
Pandas
NumPy
NLTK
Scikit-learn
Matplotlib
WordCloud