customer churn prediction
تفاصيل العمل
1. (Problem Formulation)
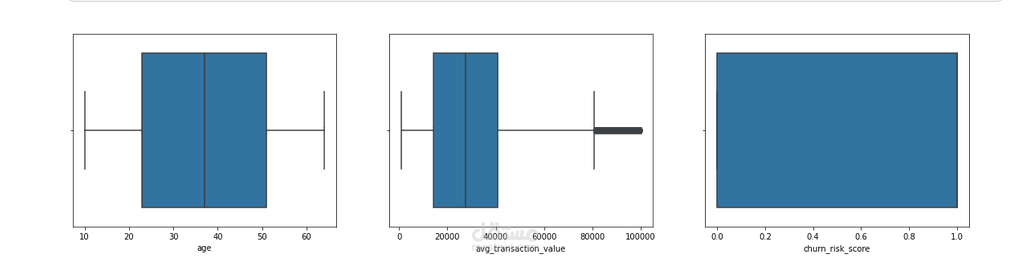
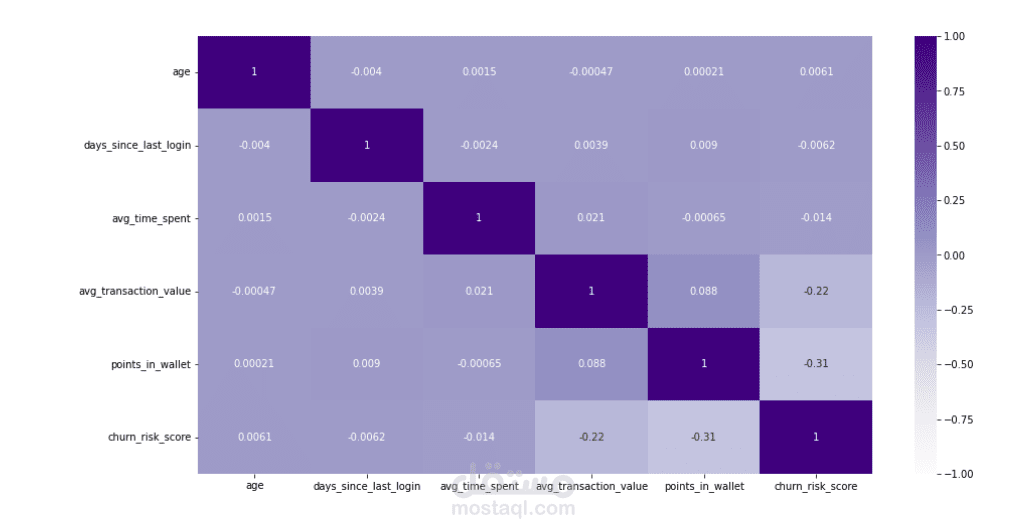
المشروع عبارة عن مسألة تصنيف ثنائي (Binary Classification)، حيث نهدف للتنبؤ بقيمة المتغير التابع (y) كـ 1 (في حال رحيل العميل) أو 0 (في حال بقائه)، بناءً على مجموعة من المتغيرات المستقلة (X).
2. (Feature Engineering)
تعتمد دقة النموذج بشكل أساسي على استخراج ميزات ذات دلالة إحصائية، وتشمل:
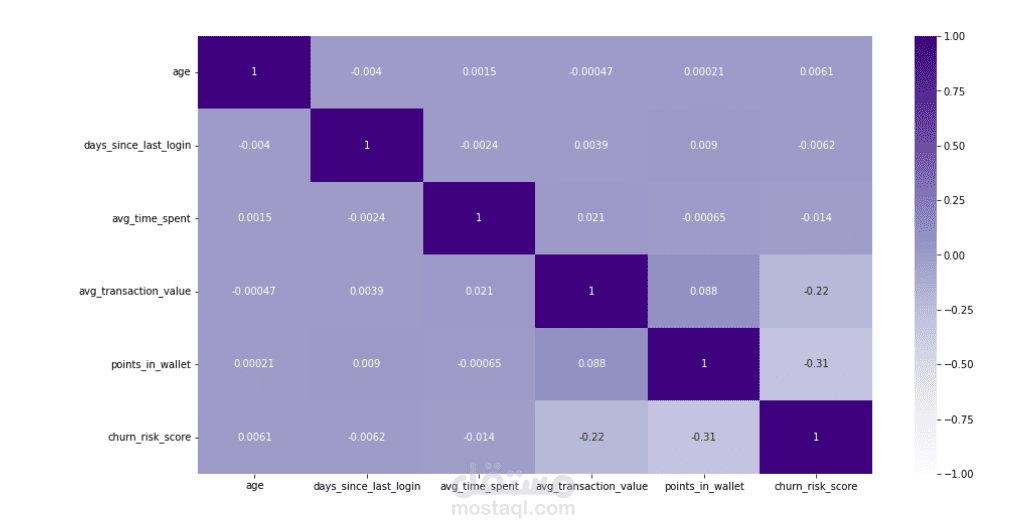
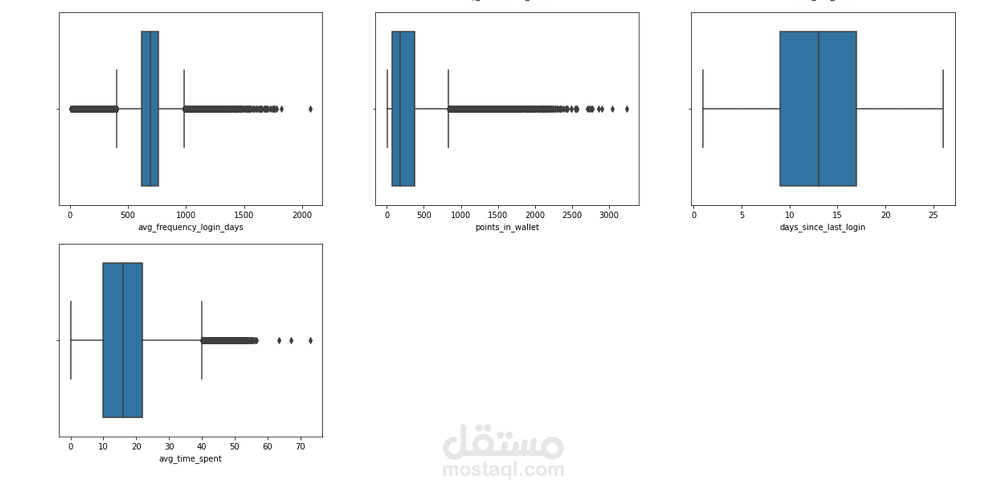
RFM Metrics: تحليل (Recency) حداثة آخر تفاعل، (Frequency) تكرار الاستخدام، و(Monetary) القيمة المالية.
Behavioral Patterns: رصد التغيرات المفاجئة في معدل الاستهلاك (مثلاً انخفاض الاستخدام بنسبة 50% في آخر شهر).
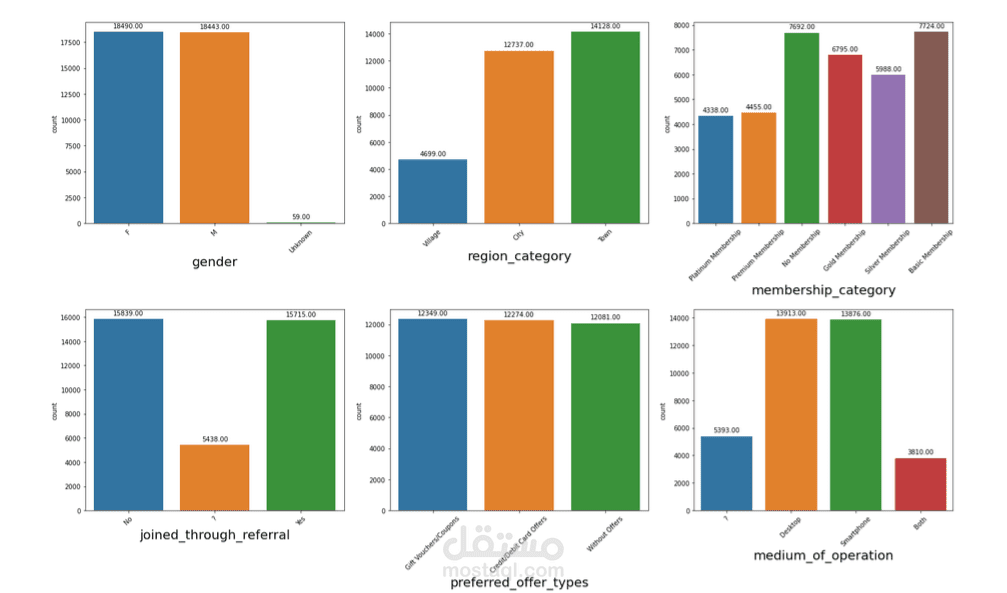
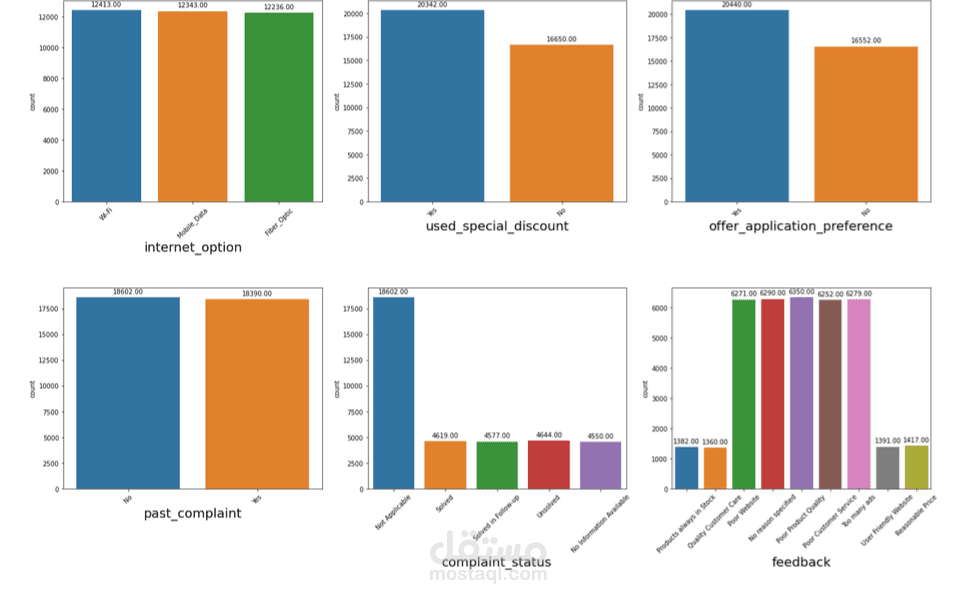
Demographics & Contractual: نوع العقد، وسيلة الدفع، والبيانات الديموغرافية.
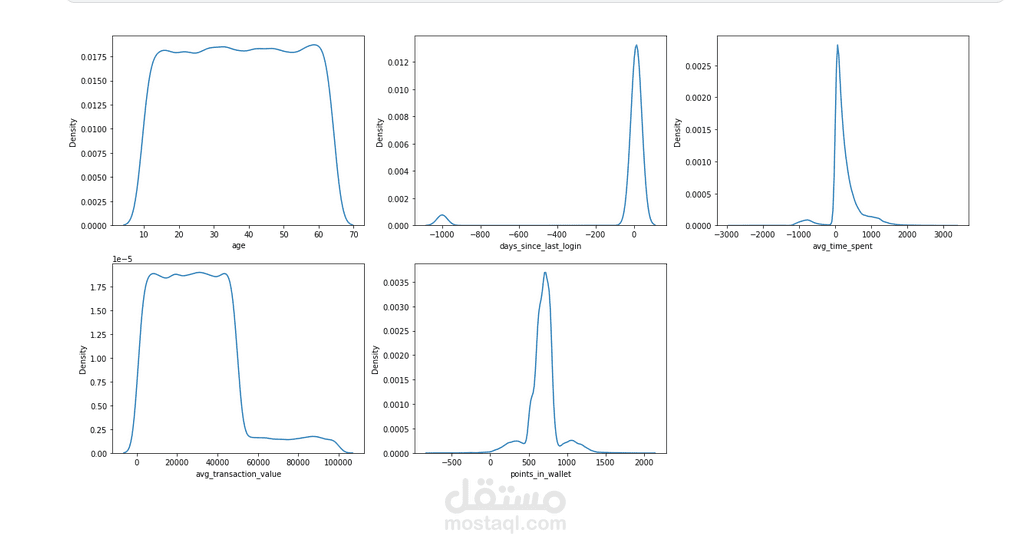
3. (Data Preprocessing)
Handling Imbalance: بما أن نسبة الراحلين عادة ما تكون أقلية، يتم استخدام تقنيات مثل SMOTE أو Random Under-sampling لموازنة البيانات.
Encoding: تحويل الميزات الفئوية باستخدام One-Hot Encoding أو Target Encoding.
Scaling: توحيد المقاييس للميزات العددية باستخدام StandardScaler لضمان كفاءة الخوارزميات الحساسة للمسافات.
4. (Modeling & Evaluation)
Algorithms: يتم المقارنة بين نماذج الـ Boosting مثل XGBoost و LightGBM، و الـ Random Forest لقدرتها العالية على التعامل مع البيانات غير الخطية.
Evaluation Metrics: لا نكتفي بالدقة (Accuracy) لخداعها في البيانات غير المتوازنة، بل نركز على:
Recall: لضمان كشف أكبر عدد ممكن من العملاء الراحلين.
Precision: لتجنب خسارة موارد الشركة على عملاء لن يرحلوا فعلياً.
AUC-ROC Curve: لتقييم قدرة النموذج على الفصل بين الفئتين.