AI Fraud Detection كشف الاحيتال
تفاصيل العمل

ما الذي يقدّمه هذا الكود للعميل؟
هذا الحل يوفّر نموذجًا أوّليًا (Prototype) لاكتشاف المعاملات الاحتيالية اعتمادًا على بيانات تاريخية. يقوم بما يلي:
قراءة البيانات وتجهيزها
استيراد ملف creditcard.csv.
حذف الصفوف الناقصة لضمان جودة التدريب (dropna).
فصل البيانات إلى مدخلات (Features) وهدف (Target).
تقييس الخصائص (Standardization)
استخدام StandardScaler لتوحيد نطاق القيم الرقمية، مما يساعد النماذج على التعلّم بشكل مستقر وفعّال.
تقسيم البيانات للتعلّم والاختبار
تقسيم البيانات إلى تدريب 80% واختبار 20% لضمان تقييم عادل للنموذج على بيانات لم يسبق له رؤيتها.
تدريب نموذج ذكاء اصطناعي
تدريب نموذج Random Forest بعدد 100 شجرة قرار—نموذج موثوق وقوي للتعامل مع بيانات متنوعة ومعقّدة.
حفظ النموذج الجاهز للاستخدام
حزم النموذج بعد التدريب وتخزينه كملف model/fraud_model.pkl باستخدام joblib لسهولة النشر والتحميل لاحقًا دون إعادة تدريب.
دوال الاستخدام التشغيلي (Inference + قرار)
predict_transaction(features): دالة تأخذ خصائص معاملة وتعيد نتيجة “Fraud Detected” أو “Transaction Safe”.
decision_engine(result): محرك قرار مبسّط يتّخذ إجراءً فوريًا (تحذير/حظر أو اعتماد العملية) بناءً على نتيجة التنبّؤ.
تقييم الأداء بالأرقام والرسوم
حساب مؤشرات الأداء الرئيسية: Accuracy, Precision, Recall, F1-score على مجموعة الاختبار.
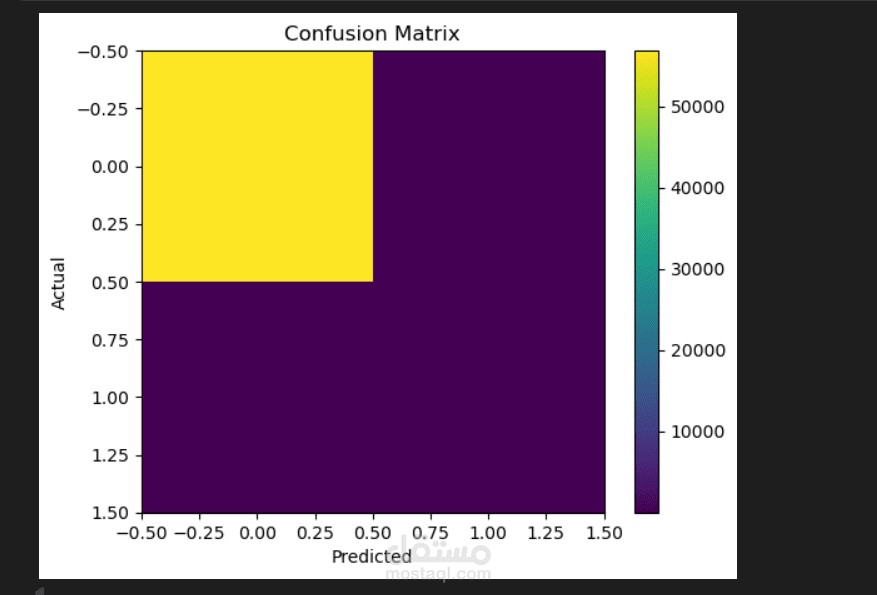
رسم مصفوفة الالتباس (Confusion Matrix) لعرض عدد الحالات المصنّفة بشكل صحيح/خاطئ بصريًا.
لماذا هذه المخرجات مهمّة للأعمال؟
تقليل الخسائر: رفع Recall يعني التقاط حالات احتيال أكثر قبل إتمام المعاملة.
تقليل الإزعاج للعملاء: رفع Precision يعني تقليل الإنذارات الكاذبة على العمليات السليمة.
سرعة النشر: حفظ النموذج كملف pkl يسمح بدمجه بسهولة في أي خدمة (API/تطبيق) دون إعادة تدريب.
شفافية الأداء: أرقام دقيقة ورسوم بصرية تسهّل على الفريق غير التقني فهم جودة الحل.
الأدوات والتقنيات المستخدمة (Stack)
Pandas: لتحميل البيانات ومعالجتها.
NumPy: عمليات رقمية ومصفوفات.
scikit‑learn:
StandardScaler لتقييس الخصائص.
train_test_split لتقسيم البيانات.
RandomForestClassifier لتدريب نموذج التصنيف.
Metrics لحساب الدقّة والدقّة الإيجابية والاستدعاء وF1 والـ Confusion Matrix.
Joblib: لحفظ/تحميل النموذج المدرَّب للنشر السريع.
Matplotlib: لعرض مصفوفة الالتباس بصريًا.
مخرجات (Deliverables) يحصل عليها العميل
ملف نموذج مدرّب fraud_model.pkl قابل لإعادة الاستخدام.
تقرير أداء رقمي على بيانات الاختبار: Accuracy / Precision / Recall / F1.
رسم مصفوفة الالتباس لفهم أنماط النجاح/الخطأ.
دوال تنبؤ ومحرك قرار يمكن استدعاؤهما داخل النظام التشغيلي.
افتراضات وحدود النسخة الحالية (لإدارة التوقعات)
التقسيم الحالي 80/20 فقط (لا يوجد Validation منفصل). عند الرغبة يمكن تعديله لـ 70/15/15 (Train/Val/Test) لتحسين اختيار الإعدادات.
عدم توازن الفئات في بيانات الاحتيال شائع جدًا؛ لذلك يُنصح لاحقًا بإضافة:
مقاييس إضافية (ROC‑AUC, PR‑AUC)
ضبط عتبة القرار (Threshold Tuning)
معالجة عدم التوازن (class_weight أو تقنيات إعادة العيّنة).
الخصائص المتوقعة يجب أن تكون بنفس ترتيب ونطاق بيانات التدريب (يلزم حفظ الـ Scaler مع النموذج في Pipeline لاستخدام الإنتاج—يمكن إضافته بسهولة عند الطلب).
المزايا المتقدّمة (مثل التنبيهات الفورية، التكامل مع قواعد بيانات/Streaming، ولوحات متابعة) غير متضمنة في هذه النسخة المبدئية، ويمكن إضافتها ضمن المرحلة التالية