Audio Gender Classification Using NB From Scratch
تفاصيل العمل
في هذا المشروع قمت بتطوير نظام تصنيف صوتي يعتمد على تقنيات معالجة الإشارة الصوتية والتعلم الآلي، بهدف التمييز بين صوت الذكور والإناث اعتمادًا على خصائص الصوت المستخرجة من المقاطع الصوتية.
بدأ العمل بمرحلة معالجة البيانات الصوتية حيث تم:
- تقليل الضوضاء من الملفات الصوتية لتحسين جودة الإشارة.
- استخراج الخصائص الصوتية المهمة باستخدام MFCC (Mel-Frequency Cepstral Coefficients) التي تُعد من أهم الميزات المستخدمة في تحليل الكلام.
بعد ذلك تم بناء خوارزمية Gaussian Naïve Bayes من الصفر بدون استخدام مكتبات جاهزة للنموذج، وذلك لفهم آلية عمل الخوارزمية رياضيًا وتنفيذها برمجيًا خطوة بخطوة، بما يشمل:
- حساب المتوسط والانحراف المعياري لكل ميزة داخل كل فئة.
- حساب احتمالية كل فئة باستخدام التوزيع الجاوسي.
- تنفيذ عملية التنبؤ بالاعتماد على أعلى احتمال.
كما يتضمن المشروع:
- إنشاء Dataset من المقاطع الصوتية وتحويلها إلى Feature Vectors.
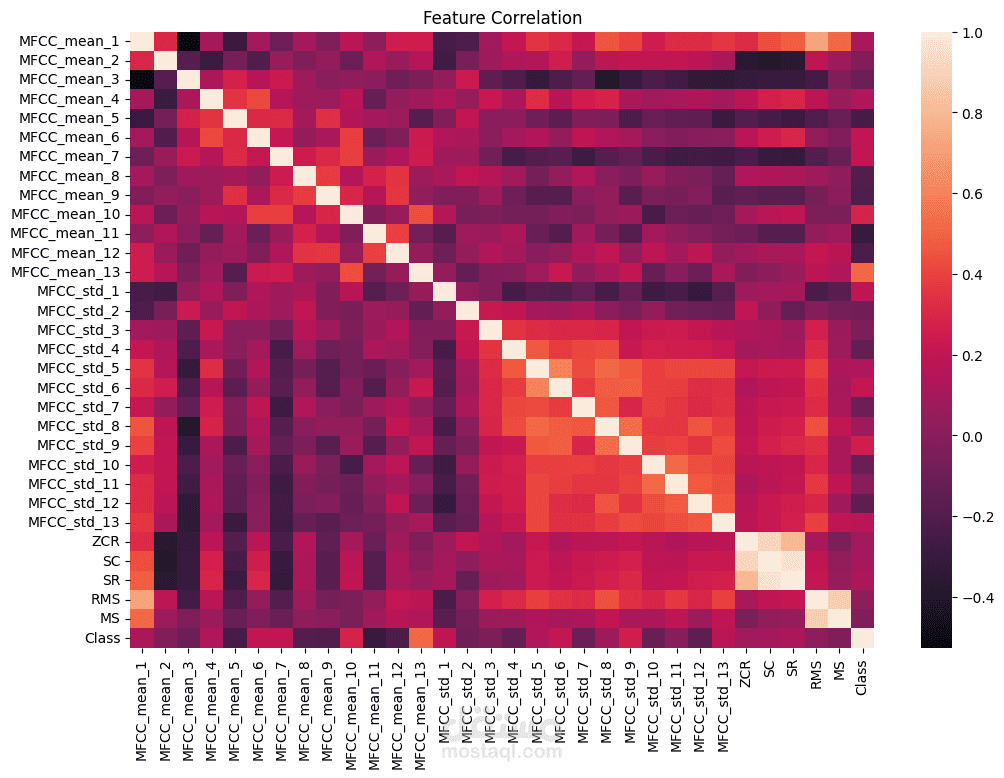
- تحليل البيانات واستكشافها باستخدام الرسوم البيانية والإحصائيات.
- تقسيم البيانات إلى تدريب واختبار.
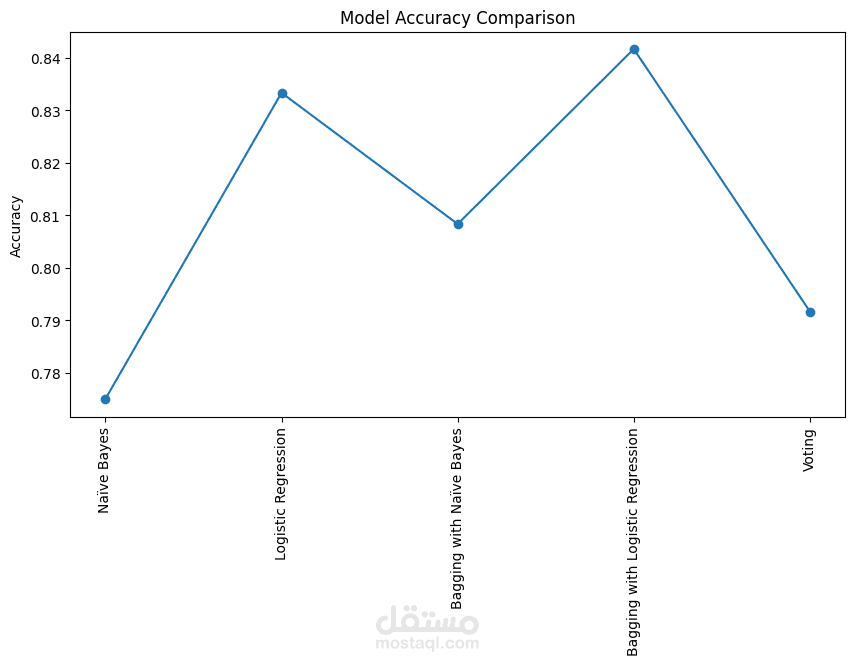
- تقييم النموذج باستخدام Accuracy ومصفوفة الالتباس (Confusion Matrix).
- عرض وتحليل نتائج النموذج لفهم أداء التصنيف.
هذا المشروع يوضح القدرة على العمل على المراحل الكاملة لمشروع تعلم آلي صوتي بداية من معالجة البيانات واستخراج الميزات، مرورًا ببناء الخوارزمية من الصفر، وحتى تقييم النموذج وتحليل نتائجه.