titanic survival prediction
تفاصيل العمل
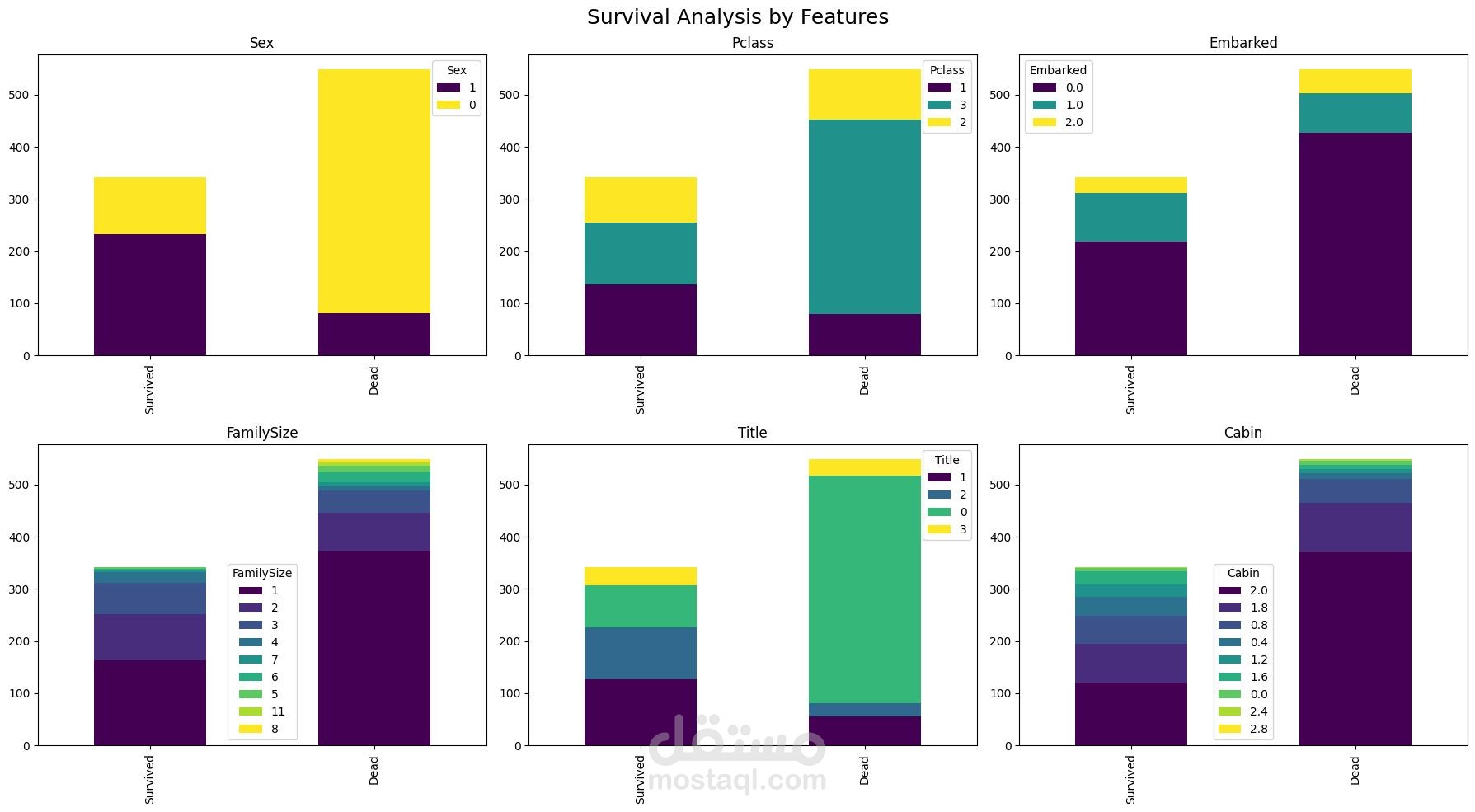
مشروع لبناء Pipeline كامل لتعلم الآلة لتوقع بقاء ركاب Titanic باستخدام بيانات جدولية منظمة.
خطوات المشروع:
1️⃣ معالجة البيانات:
التعامل مع القيم المفقودة (العمر، Fare، Embarked)
ترميز المتغيرات الفئوية (Sex، Embarked، Title)
إزالة الأعمدة غير المهمة (PassengerId، Ticket)
2️⃣ استخراج الميزات (Feature Engineering):
استخراج Title من الاسم
إنشاء ميزة FamilySize
معالجة معلومات الكابينة (Cabin)
3️⃣ تقييم النماذج:
استخدام Cross Validation بـ 15-Folds
مقارنة عدة خوارزميات تصنيف
أفضل نموذج:
Random Forest Classifier بدقة 80.81%
الأدوات المستخدمة:
Python | Pandas | NumPy | Matplotlib | Seaborn | Scikit-learn
أهم النتائج والتعلم:
بناء Pipeline كامل لتعلم الآلة
استخراج ميزات قوية من البيانات
تقييم النماذج بشكل متين باستخدام Cross-Validation
اختيار أفضل نموذج للتصنيف