Machine Learning Model On Churning Dataset
تفاصيل العمل
قمت بتطوير نظام متكامل للتنبؤ باحتمالية انسحاب العملاء من خدمات شركة اتصالات باستخدام تقنيات تعلم الآلة (Machine Learning) وتحليل البيانات. يهدف المشروع إلى مساعدة الشركات على تحديد العملاء الأكثر عرضة لترك الخدمة مبكرًا، مما يتيح اتخاذ إجراءات استباقية لتحسين تجربة العملاء وزيادة معدل الاحتفاظ بهم.
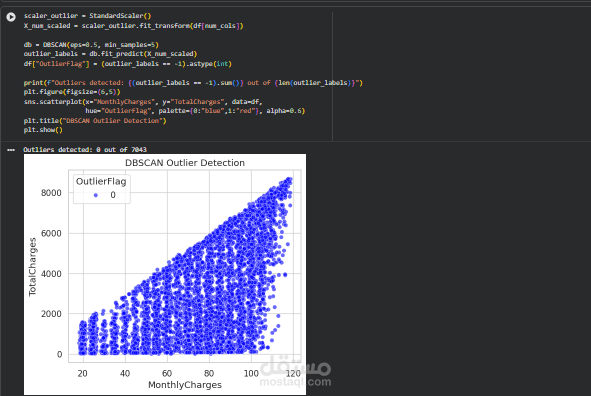
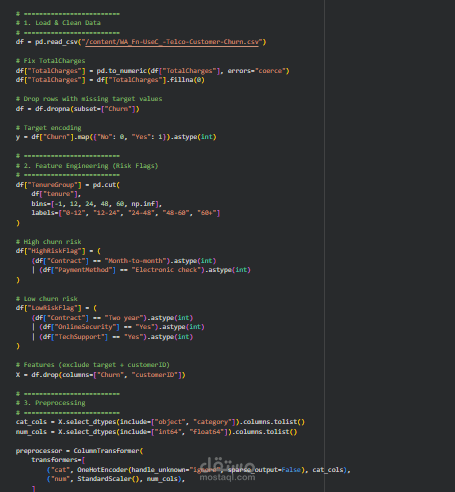
بدأ المشروع بمرحلة جمع البيانات وتحضيرها (Data Preparation) حيث تم تحميل مجموعة البيانات وتحليلها لاكتشاف أي مشاكل مثل القيم المفقودة أو الأنواع غير الصحيحة للبيانات. تم تحويل العمود TotalCharges من نص إلى قيمة رقمية ومعالجة القيم المفقودة لضمان أن البيانات قابلة للاستخدام في تدريب النموذج. كما تم تحويل المتغير المستهدف Churn إلى قيم رقمية (0 و 1) لتمثيل بقاء العميل أو انسحابه.
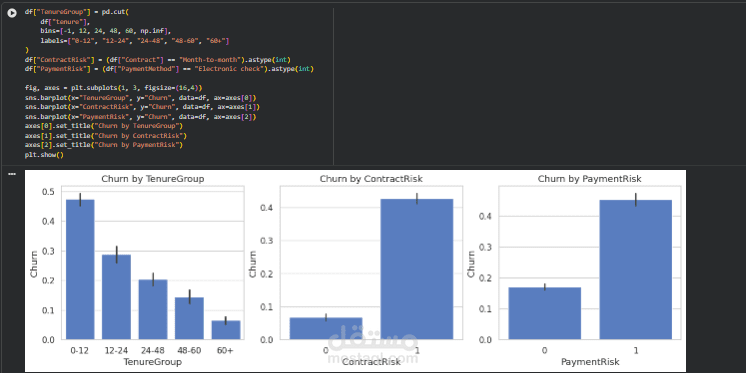
بعد ذلك تم تنفيذ مرحلة هندسة الخصائص (Feature Engineering) لتحسين قدرة النموذج على التعلم واكتشاف الأنماط. تم إنشاء متغير جديد يسمى TenureGroup لتصنيف العملاء حسب مدة اشتراكهم في الخدمة، مما يساعد النموذج على فهم العلاقة بين مدة الاشتراك واحتمالية الانسحاب. كما تم إنشاء خصائص إضافية مثل HighRiskFlag و LowRiskFlag لتحديد العملاء ذوي المخاطر المرتفعة أو المنخفضة للانسحاب بناءً على عوامل مثل نوع العقد وطريقة الدفع والخدمات المستخدمة.
ثم تم بناء Pipeline متكامل لمعالجة البيانات باستخدام مكتبة Scikit-learn لضمان تطبيق نفس خطوات المعالجة على بيانات التدريب والاختبار. تم استخدام One-Hot Encoding لتحويل المتغيرات الفئوية إلى تمثيل رقمي، بينما تم استخدام StandardScaler لتوحيد القيم العددية وتحسين أداء النموذج.
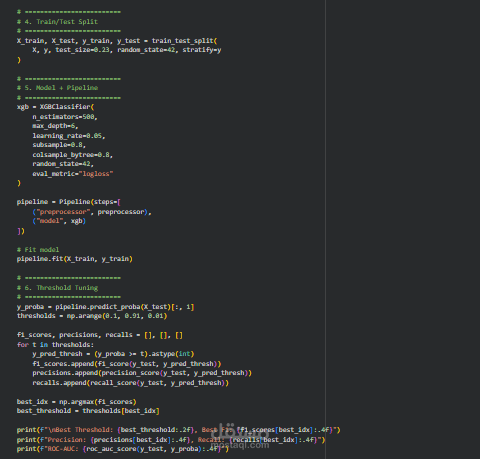
بعد تجهيز البيانات، تم تقسيمها إلى بيانات تدريب واختبار باستخدام طريقة التقسيم الطبقي (Stratified Split) للحفاظ على نفس توزيع الفئات في كلا المجموعتين، مما يضمن تقييمًا أكثر دقة للنموذج.
بالنسبة للنموذج المستخدم، تم بناء نموذج XGBoost Classifier وهو من أقوى الخوارزميات المستخدمة في التعامل مع البيانات الجدولية. تم ضبط عدة معاملات مهمة مثل عدد الأشجار (n_estimators)، عمق الشجرة (max_depth)، ومعدل التعلم (learning_rate) بالإضافة إلى تقنيات مثل subsampling لتحسين قدرة النموذج على التعميم وتقليل مشكلة overfitting.
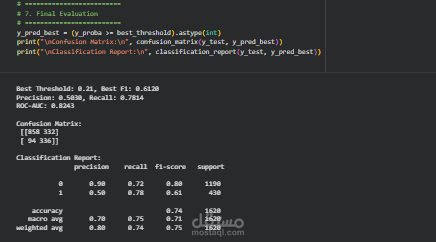
لتحسين الأداء بشكل إضافي، تم تنفيذ عملية ضبط عتبة القرار (Threshold Tuning). بدلاً من استخدام العتبة الافتراضية (0.5)، تم اختبار عدة قيم مختلفة للعثبة من أجل إيجاد القيمة التي تحقق أفضل توازن بين Precision و Recall. تم اختيار العتبة التي تحقق أعلى F1 Score لضمان قدرة النموذج على اكتشاف أكبر عدد ممكن من حالات الانسحاب مع تقليل الأخطاء.
في النهاية، تم تقييم أداء النموذج باستخدام عدة مقاييس مهمة في نماذج التصنيف مثل:
Confusion Matrix لتحليل توزيع التوقعات الصحيحة والخاطئة
Precision و Recall لقياس دقة النموذج في اكتشاف العملاء المنسحبين
F1 Score لتحقيق توازن بين الدقة والاسترجاع
ROC-AUC Score لقياس قدرة النموذج على التمييز بين العملاء المنسحبين وغير المنسحبين
يمثل هذا المشروع تطبيقًا عمليًا متكاملًا لدورة حياة مشروع تعلم الآلة، بدءًا من تنظيف البيانات وهندسة الخصائص مرورًا بـ بناء النموذج وتحسينه وانتهاءً بـ تقييم الأداء واستخراج النتائج، مما يوفر أداة تحليلية يمكن استخدامها لدعم قرارات الأعمال وتحسين استراتيجيات الاحتفاظ بالعملاء.
التقنيات والأدوات المستخدمة:
Python
Pandas & NumPy
Scikit-learn
XGBoost
Data Preprocessing
Feature Engineering
Machine Learning Pipelines
Model Evaluation & Threshold Optimization