Twitter Sentiment Classification
تفاصيل العمل
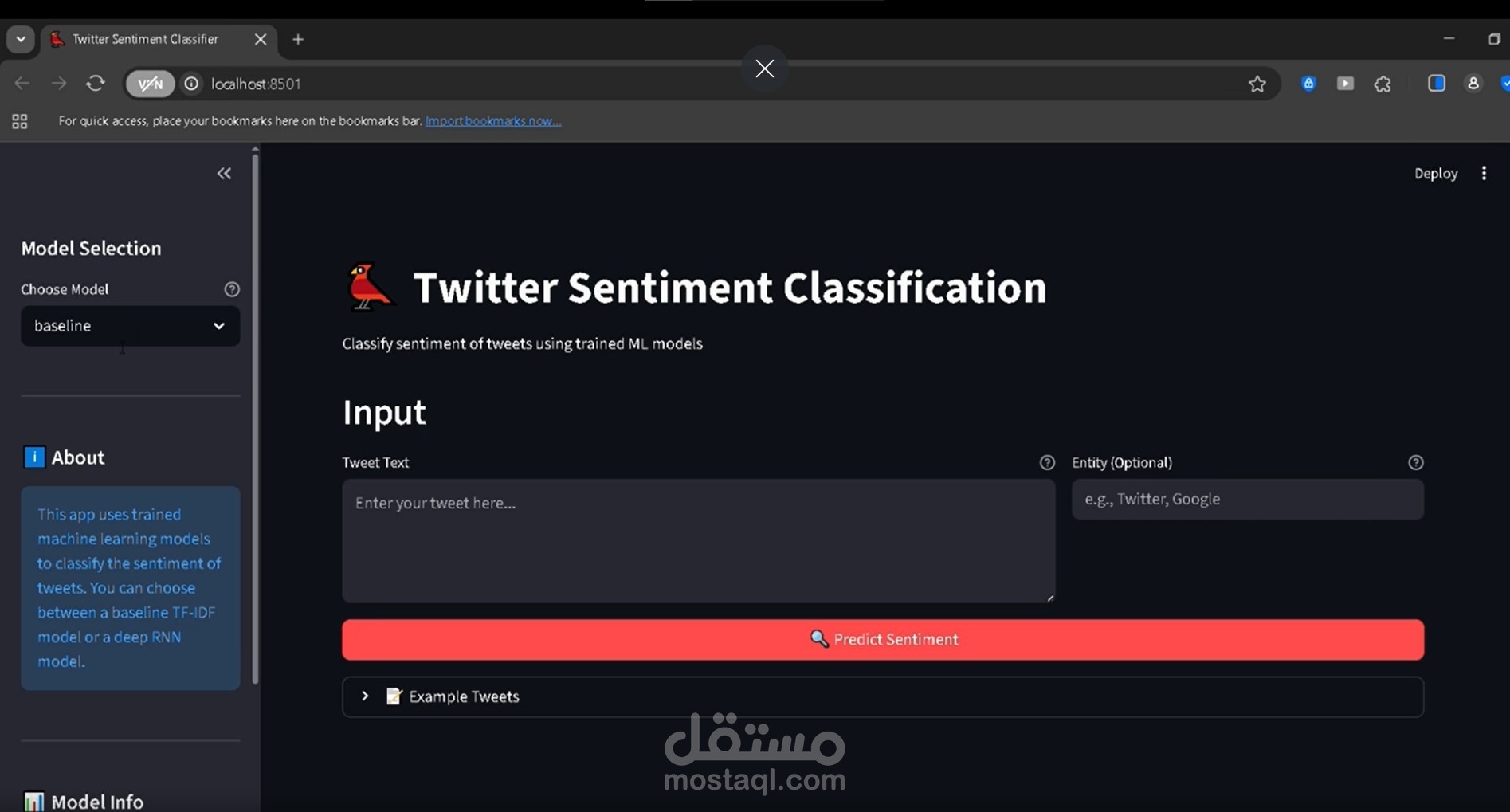
Project Title: Production-Ready Twitter Sentiment Classification System
Project Type: This project is an interactive web application built with Streamlit. It functions as a complete, production-ready system for analyzing sentiment in tweets. Its core purpose is to provide a practical, side-by-side comparison between traditional machine learning and deep learning methodologies for text classification tasks.
Key Features:
4-Class Sentiment Prediction: The system accurately classifies a tweet into one of four specific categories: Positive, Negative, Neutral, or Irrelevant.
Entity-Aware Input (Optional): An optional feature that allows users to provide context, such as a specific entity (e.g., "Microsoft," "Twitter"). The model incorporates this context during analysis, leading to more nuanced and accurate understanding.
Transparent Outputs: The system doesn't just return the final classification. It also provides a confidence score and a full probability breakdown for all four classes. This transparency helps users understand the reasoning behind the model's prediction.
Two-Model Comparison: The application allows users to compare the performance of two distinct models side-by-side:
Baseline Model (Traditional ML): Uses TF-IDF for feature extraction combined with a LinearSVC classifier.
Advanced Model (Deep Learning): Leverages a Recurrent Neural Network (RNN) , specifically a BiLSTM or GRU, which is better at capturing context and word sequences.
Practical Interface for Real Testing: The primary focus was on building a clean, intuitive, and practical user interface with Streamlit, making it an effective tool for real-world testing and experimentation.
Full Demo Walkthrough: The repository includes a comprehensive video or visual walkthrough demonstrating how to run the project and test all its features.
Implementation Approach:
Backend:
Preprocessing: Text data is cleaned (removing links, punctuation, handling case) and prepared for both models.
SVC Model: Text is transformed into TF-IDF vectors, which are then used to train a Linear SVC classifier.
RNN Model: Words are converted into numerical representations (Embeddings) and fed into a neural network with (Bilt STM /GRU) layers and dense layers for final classification.
Model Persistence: Both trained models are saved using libraries like pickle/joblib (for sklearn models) and formats like H5/Keras (for deep learning models) for later use in the app.
Frontend (Streamlit):
Input Interface: A text box for the tweet, an optional input field for the entity/context, and buttons to select which model to use.
Results Display: Upon clicking "Analyze," the chosen model is loaded and performs the prediction. Results are displayed clearly, showing the classification, confidence score, and a bar chart visualizing the probability distribution across the four classes.