مشروع Text Analyzer هو أداة مبنية بلغة بايثون
تفاصيل العمل
نبذة عن المشروع:
قمت ببرمجة وتطوير أداة "محلل النصوص" (Text Analyzer) باستخدام لغة بايثون (Python). يهدف هذا السكربت إلى استقبال أي نص، القيام بمعالجته وتفكيكه برمجياً، ثم إصدار تقرير شامل ودقيق يحتوي على إحصائيات تفصيلية حول مكونات هذا النص. هذا النوع من السكربتات يُعد خطوة أساسية في مجالات تنظيف البيانات (Data Cleaning) ومعالجة اللغات الطبيعية (NLP).
المهام التي تقوم بها الأداة:
التحليل الإحصائي: حساب إجمالي عدد الأحرف والكلمات بدقة.
تحليل الجمل: التعرف الذكي على نهايات الجمل (من خلال علامات الترقيم مثل . و ! و ?) لحساب عددها.
البحث المخصص: إيجاد وحساب معدل تكرار كلمات مفتاحية محددة داخل النص (Keyword Frequency).
فلتره البيانات (Data Filtering): تنظيف النص من علامات الترقيم، توحيد حالة الأحرف (Lowercase)، واستخراج قائمة بالكلمات الفريدة (Unique Words) بدون أي تكرار.
الخوارزميات البسيطة: البحث آلياً عن "أطول كلمة" داخل النص وحساب عدد أحرفها.
تعديل النصوص: استبدال كلمات معينة بكلمات أخرى ديناميكياً وإنشاء نسخة جديدة من النص.
التقطيع (Slicing): عكس النص بالكامل من الحرف الأخير للأول.
التقنيات والمهارات المستخدمة في الكود:
لغة البرمجة: Python
معالجة النصوص (String Manipulation & Methods).
هياكل البيانات الأساسية (Data Structures - Lists).
التحكم في مسار البرنامج عبر حلقات التكرار (For Loops) والجمل الشرطية (If Conditions).
التنسيق المتقدم للمخرجات باستخدام (f-strings).
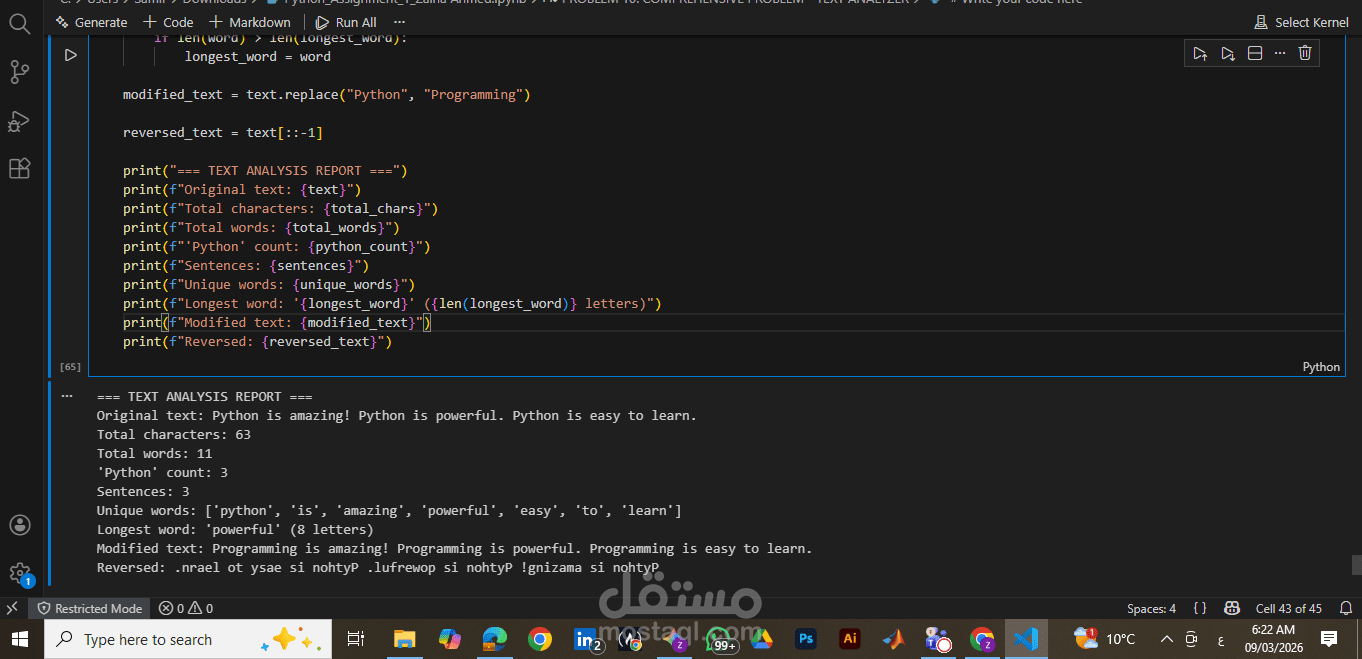
النتيجة (مخرجات البرنامج):
يقوم البرنامج بطباعة تقرير (Report) منسق ومقروء يسهل على المستخدم فهم تفاصيل النص المدخل فوراً، كما هو موضح في الصور المرفقة للمشروع.