CharityML – Income Prediction for Donor Targeting (Supervised Machine Learning – Binary Classification)
تفاصيل العمل

CharityML – Income Prediction for Donor Targeting
(Supervised Machine Learning – Binary Classification)
Objective
Built a predictive model to help a non-profit identify individuals likely to donate by predicting whether annual income > $50,000 using the 1994 UCI Adult Census dataset.
Dataset
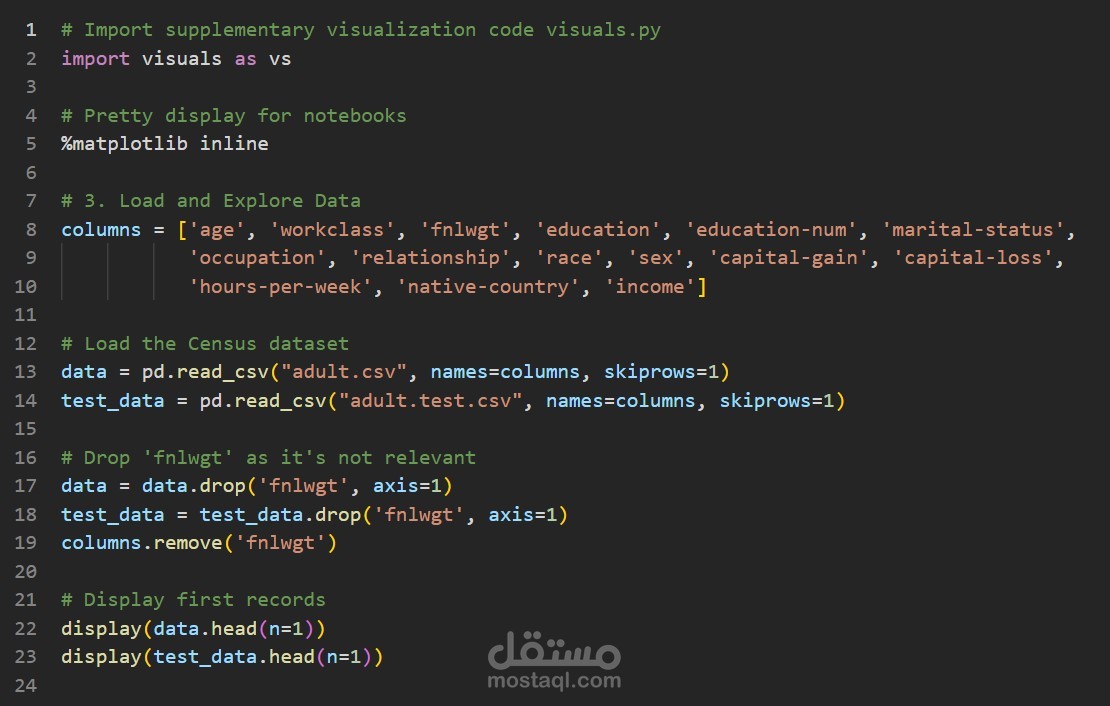
~32,561 records (after cleaning → ~26,900 usable)
Severe class imbalance (~25.6% >$50K)
14 raw features (6 numerical + 8 categorical) → expanded to ~103 features after encoding
Key Technical Achievements
Data Preparation & Cleaning
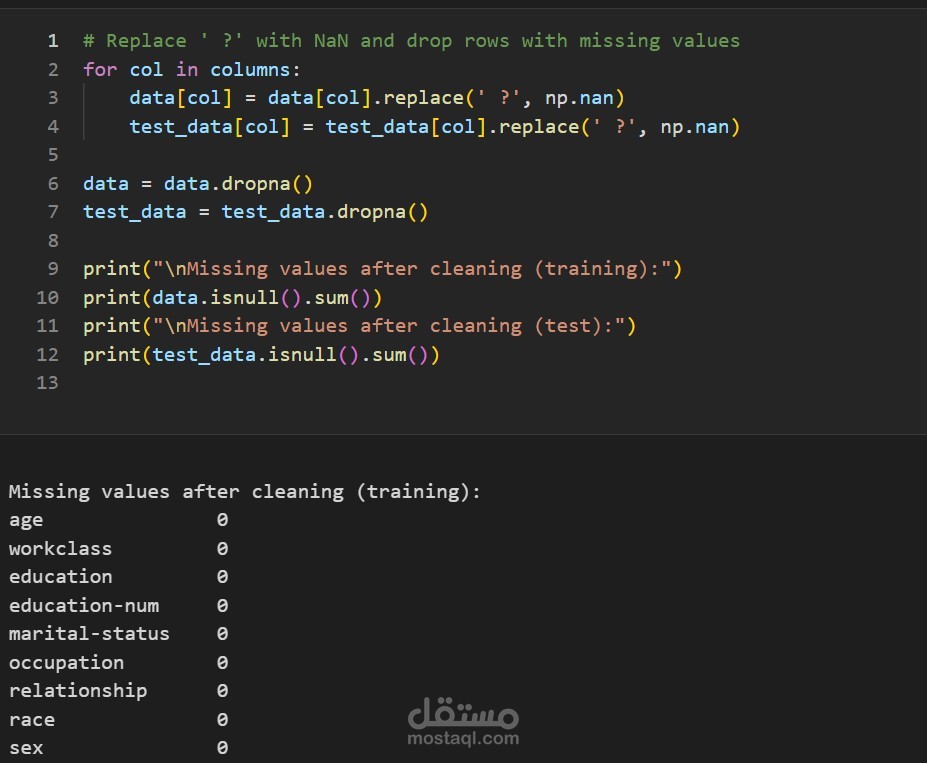
Removed duplicates, handled missing values (' ?' → NaN), standardized target labels
One-hot encoding of categorical variables
MinMax scaling of continuous features
Exploratory Data Analysis
Identified strong predictors early: capital-gain, age, education level, marital status
Visualized feature importance and class distribution
Modeling & Optimization
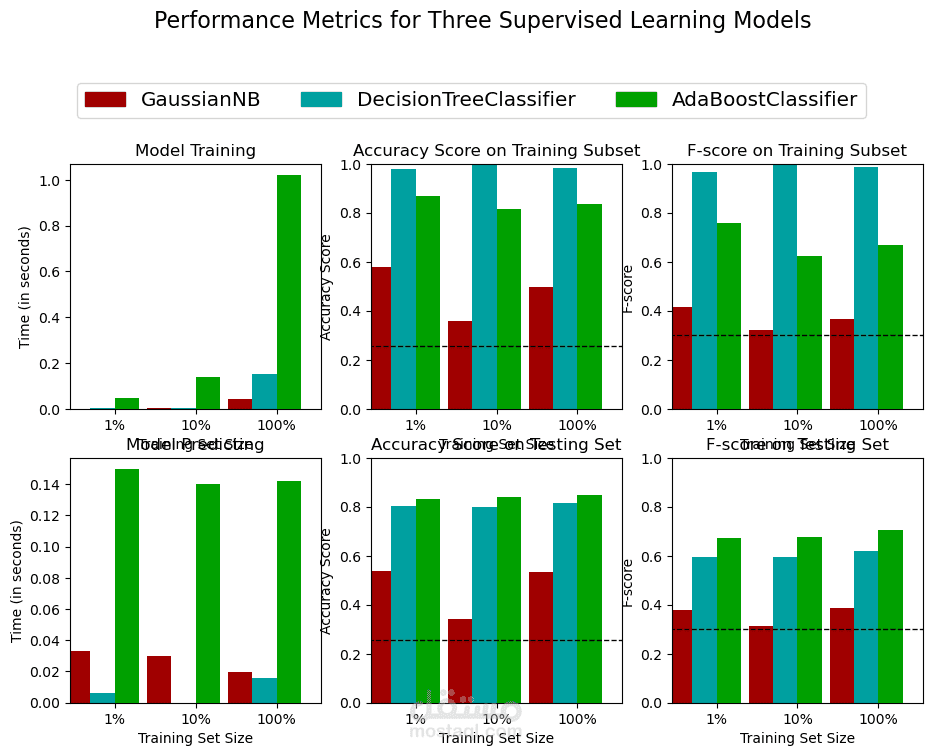
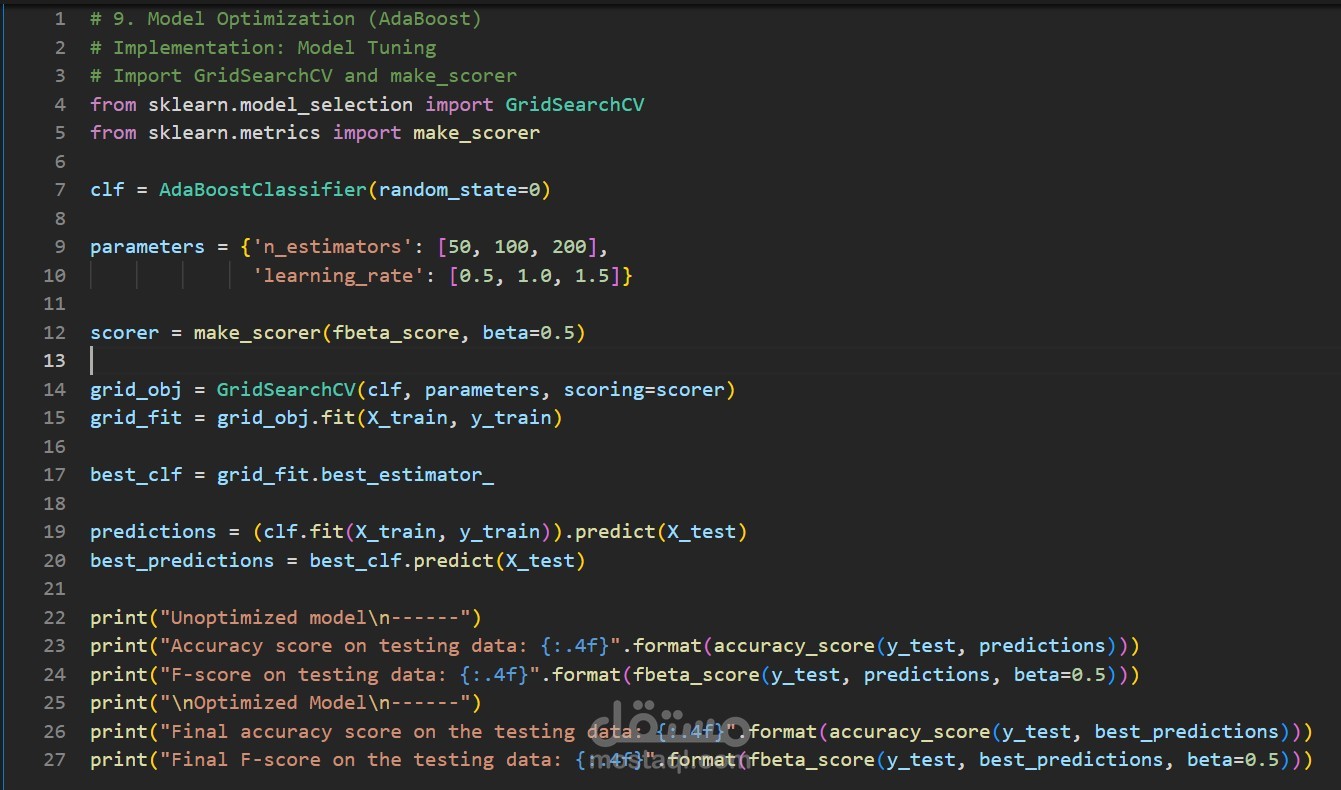
Compared 4 algorithms: GaussianNB, DecisionTree, AdaBoost, RandomForest
Used GridSearchCV for hyperparameter tuning
Optimized for Fβ=0.5 score (prioritizing precision – critical for donor targeting)
Final Model Performance (best configuration – full feature set)
Accuracy: 85.6%
Fβ=0.5: 72.4%
Feature Importance & Model Simplification
Top 5 most predictive features (Random Forest):
age
capital-gain
education-num
hours-per-week
marital-status_Married-civ-spouse
Model trained only on these 5 features:
Accuracy: 84.1% (–1.5%)
Fβ=0.5: 68.4% (–4%)
Training time reduced by ~45–50%
Business & Modeling Takeaways
Capital-gain is by far the strongest single signal
Marital status (especially “Married-civ-spouse”) is a surprisingly powerful proxy for higher household income
~95% of predictive power can be captured with only 5 features → excellent trade-off between performance and simplicity
Precision-focused evaluation metric (F0.5) was correctly chosen for real-world donor outreach use-case
Technologies & Skills Demonstrated
Python, pandas, scikit-learn
Data cleaning & preprocessing pipelines
One-hot encoding + feature scaling
Model comparison & hyperparameter tuning (GridSearchCV)
Feature importance analysis & dimensionality reduction
Handling class imbalance & appropriate metric selection (Fβ score)
End-to-end ML workflow in Jupyter Notebook
Clear business interpretation & trade-off analysis