Fake News Detection using Natural Language Processing (NLP)
تفاصيل العمل
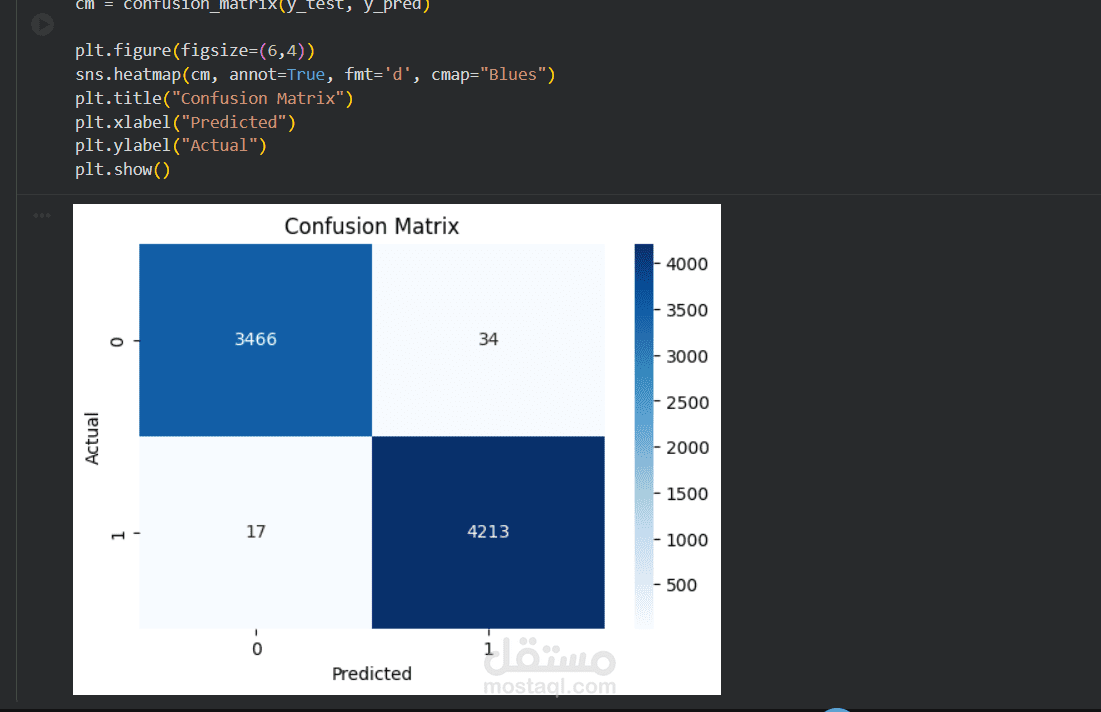
مشروع متقدم في مجال معالجة اللغات الطبيعية (NLP) يهدف إلى تصنيف الأخبار إلى (حقيقية) أو (مزيفة) بدقة عالية. قمت في هذا المشروع بالخطوات التالية:
تنظيف البيانات: معالجة النصوص لإزالة الرموز، الروابط، وعلامات الترقيم، وتطبيق تقنيات الـ Lemmatization لرد الكلمات إلى أصولها.
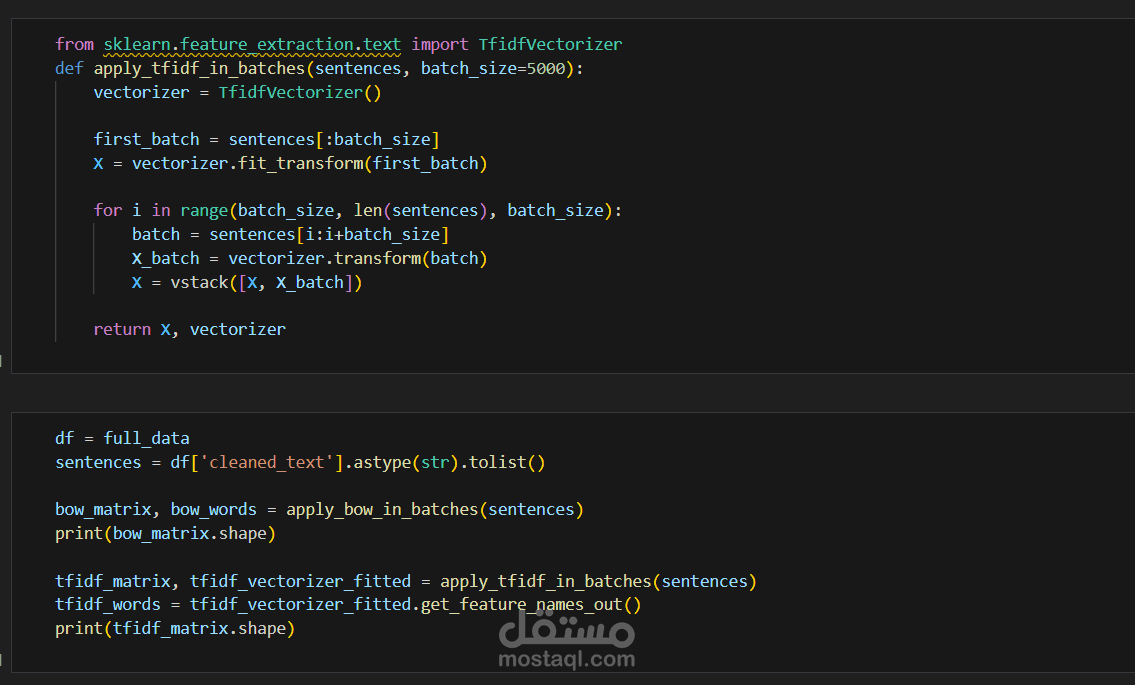
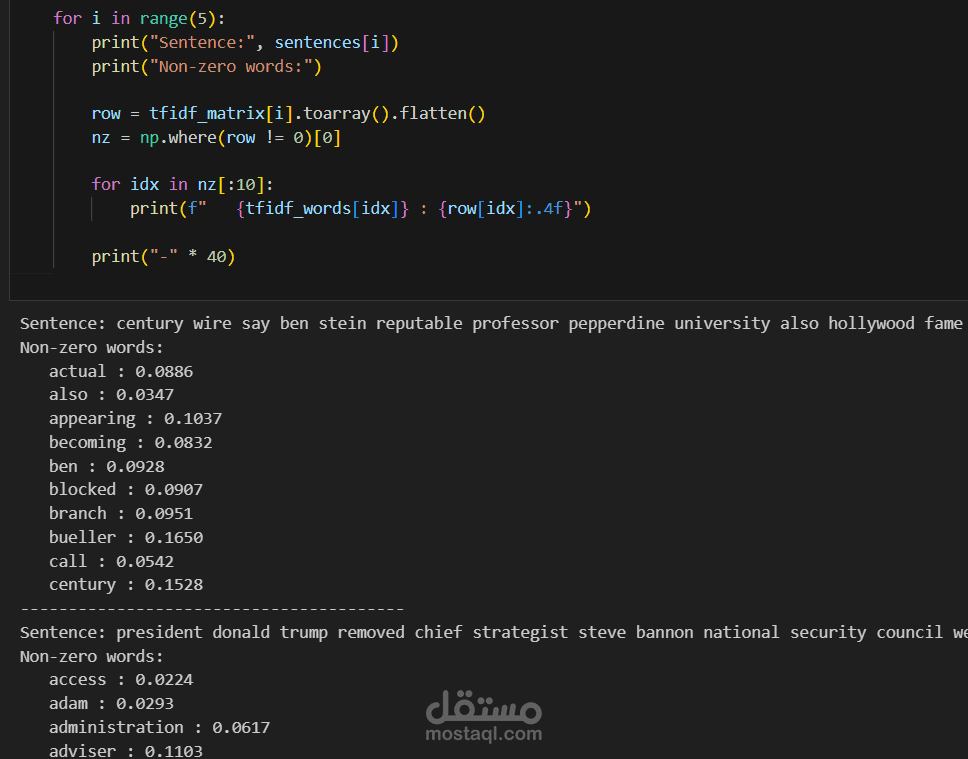
هندسة الميزات: تحويل النصوص إلى أرقام باستخدام TF-IDF Vectorizer.
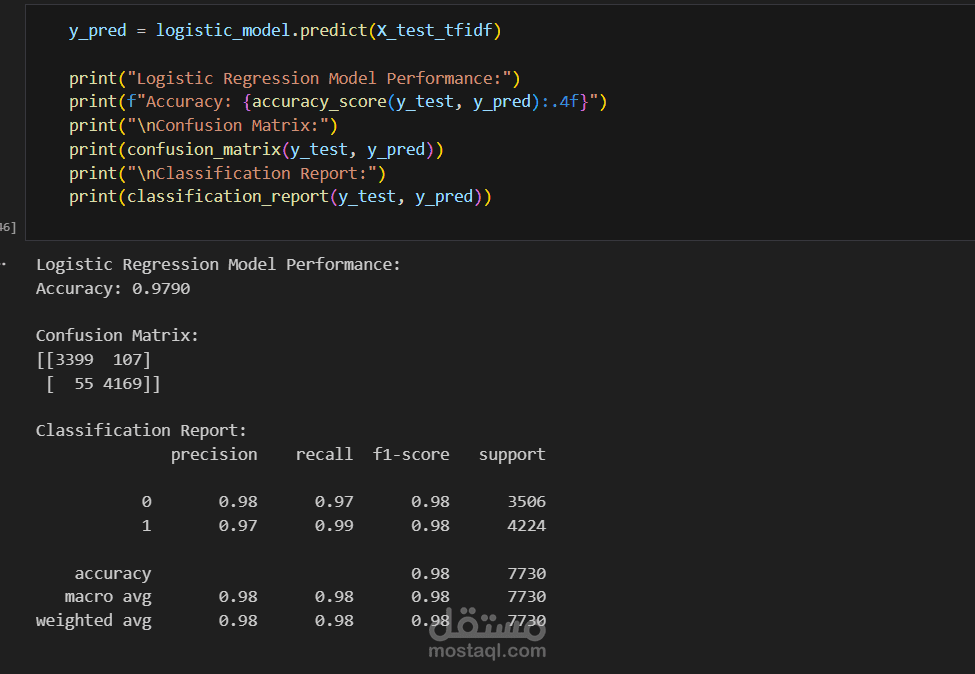
بناء النموذج: استخدام خوارزمية Logistic Regression لتدريب النموذج على بيانات ضخمة (أكثر من 38,000 خبر).
النتائج: حقق النموذج دقة تصل إلى 98% على بيانات الاختبار، وتم اختباره بنجاح على مجموعة بيانات خارجية للتأكد من كفاءته.
الأدوات المستخدمة: Python, Scikit-learn, NLTK, Pandas, Matplotlib.