Arabic Hate Speech Detection
تفاصيل العمل

بناء نظام Natural Language Processing (NLP) لتحليل النصوص العربية وتصنيفها بدقة عالية باستخدام تقنيات Machine Learning و Deep Learning.
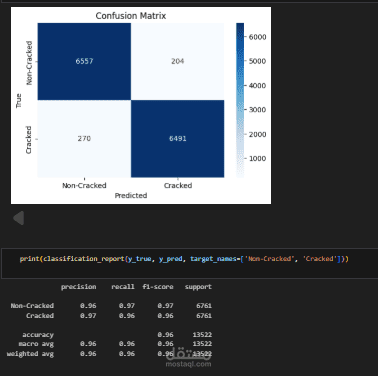
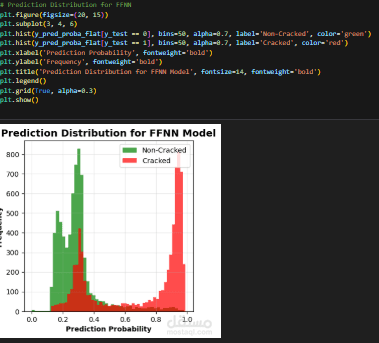
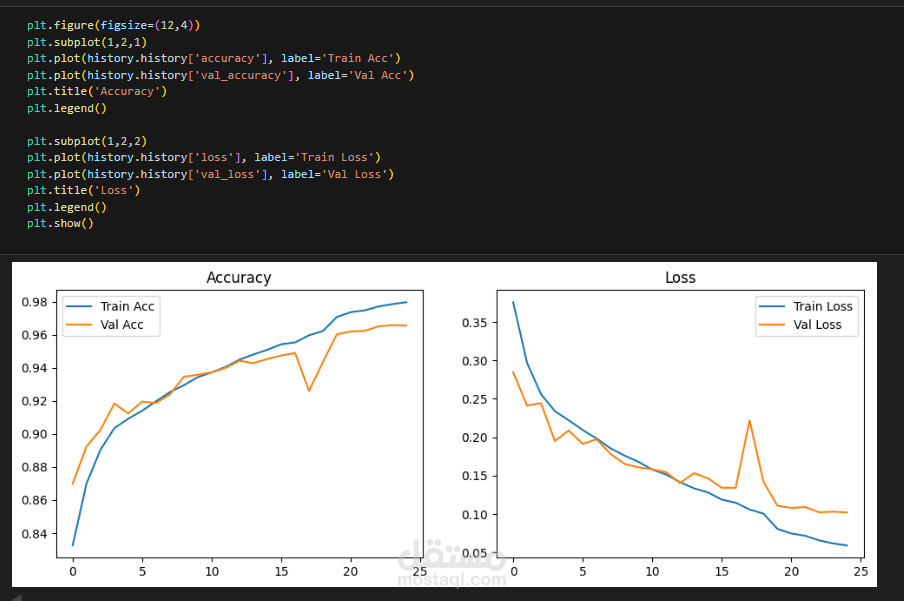
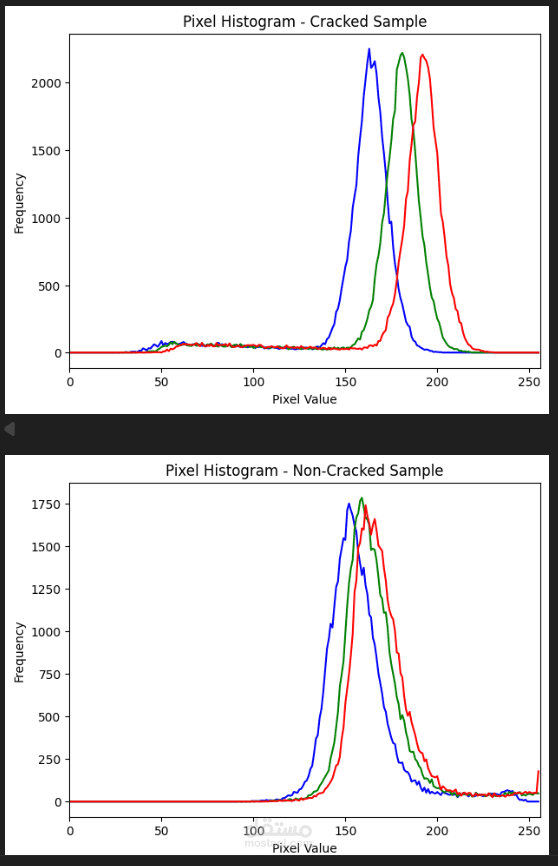
في هذا المشروع قمت بتطوير نظام متكامل لاكتشاف خطاب الكراهية في اللغة العربية وخاصة اللهجة المصرية باستخدام عدة نماذج ومقارنة أدائها لاختيار النموذج الأكثر دقة.
ماذا يتضمن المشروع؟
? تحليل ومعالجة النصوص العربية
تنظيف النصوص وإزالة الرموز والروابط
توحيد الحروف العربية
إزالة الكلمات الشائعة (Stopwords)
استخدام تقنيات Stemming
? استخراج الخصائص (Feature Extraction)
TF-IDF
Word2Vec Embeddings
Contextual Embeddings باستخدام AraBERT
? بناء عدة نماذج للمقارنة
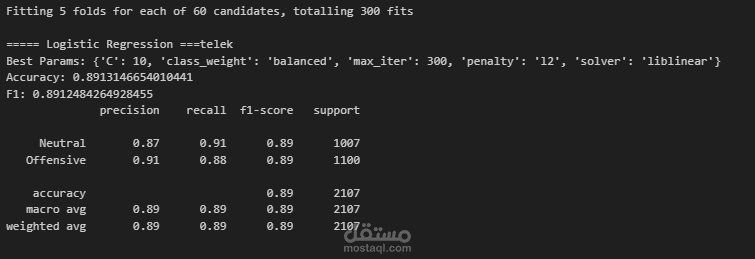
1 Logistic Regression + TF-IDF
حقق دقة 89% ويعتبر نموذجًا قويًا وسريعًا كنموذج أساسي.
2 BiLSTM + Word2Vec
نموذج Deep Learning لمعالجة تسلسل الكلمات وحقق دقة 75%.
3 AraBERT Transformer Model
أفضل نموذج في التجربة حيث حقق دقة 90% بفضل فهمه العميق لسياق اللغة العربية.