RAG-powered CV Chatbot
تفاصيل العمل
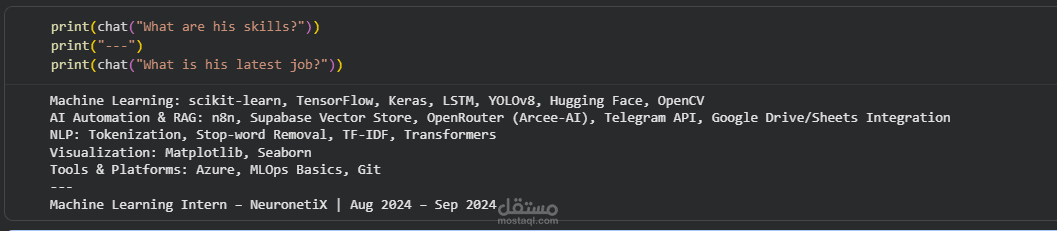
The idea is simple: you upload any CV (PDF) and start asking questions about it, and the AI answers based only on the information inside the CV.
I built it while learning LangChain and RAG, and it was a great way to understand how these systems actually work in practice.
Tech stack I used:
LangChain to connect the whole pipeline
Groq + LLaMA 3.1 (8B) as the LLM for generating responses
HuggingFace Embeddings (paraphrase-multilingual-MiniLM-L12-v2) to convert text into vectors
FAISS as the vector database
PyPDF to extract text from the CV
RecursiveCharacterTextSplitter to split the CV into chunks (500 chars with 50 overlap)
Conversation Memory so the chatbot remembers the context of the conversation
How it works:
Upload a CV as a PDF
Extract the text from the file
Split the text into smaller chunks
Convert the chunks into embeddings
Store them in FAISS
When a question is asked, the retriever finds the most relevant chunks
The LLM uses those chunks + the conversation history to generate the answer
Everything was built on Google Colab using open-source tools.