تصنيف أنواع السرطان باستخدام التعلم الآلي وبيانات الطفرات الجينية (TCGA Dataset)
تفاصيل العمل
تُعد عملية تحديد نوع السرطان بدقة من التحديات المهمة في مجال تحليل البيانات الجينومية، خاصةً عند الاعتماد فقط على بيانات الطفرات الجينية دون معلومات طبية إضافية. لذلك يهدف هذا المشروع إلى استخدام تقنيات التعلم الآلي لتحليل أنماط الطفرات الجينية وتصنيف أنواع السرطان المختلفة بشكل آلي.
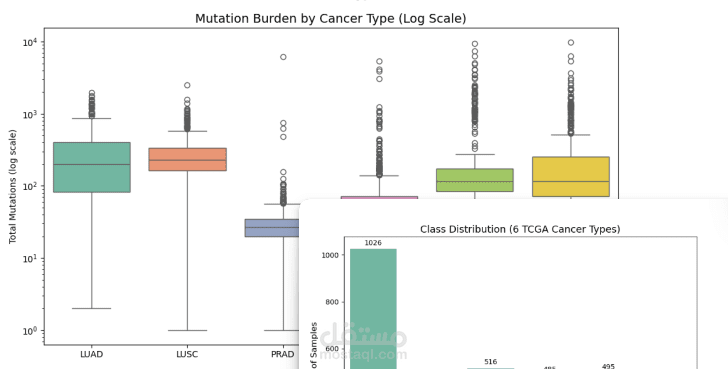
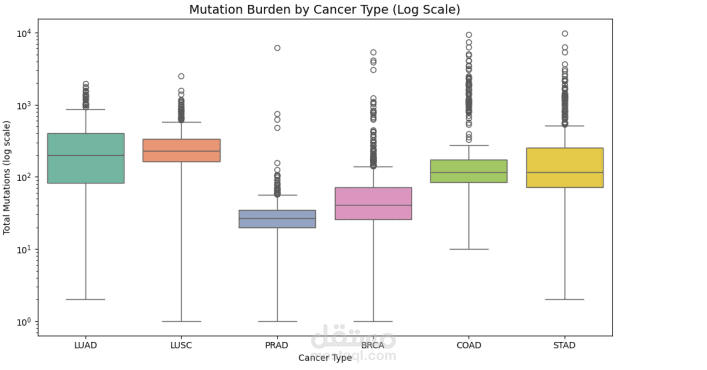
لحل هذه المشكلة، قمت باستخدام بيانات الطفرات الجسدية (Somatic Mutations) من قاعدة بيانات TCGA Pan-Cancer MC3، حيث تم بناء Pipeline كاملة لمعالجة البيانات الجينومية. شمل ذلك تنظيف البيانات، واختيار الطفرات غير الصامتة، ثم استخراج مجموعة من الخصائص المهمة مثل عدد الطفرات الكلي، توزيع أنواع الطفرات، عدد الطفرات في الجينات الأكثر شيوعًا، بالإضافة إلى تواقيع الطفرات ثلاثية السياق (96-context mutation signatures) التي تعكس العمليات البيولوجية المسببة للطفرات.
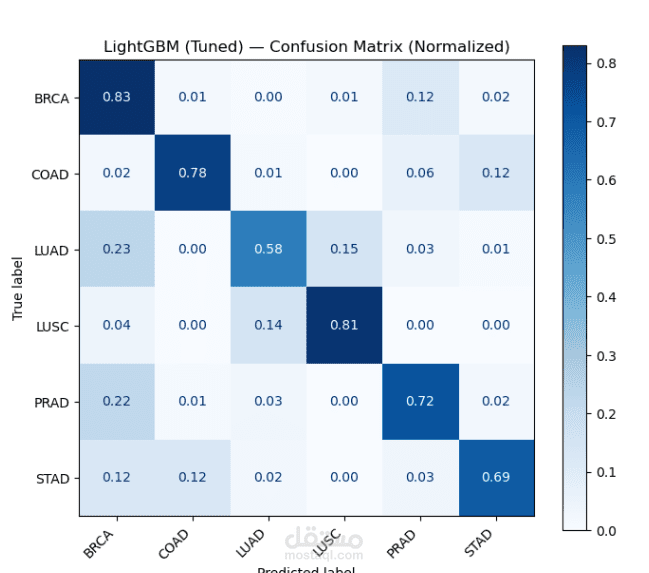
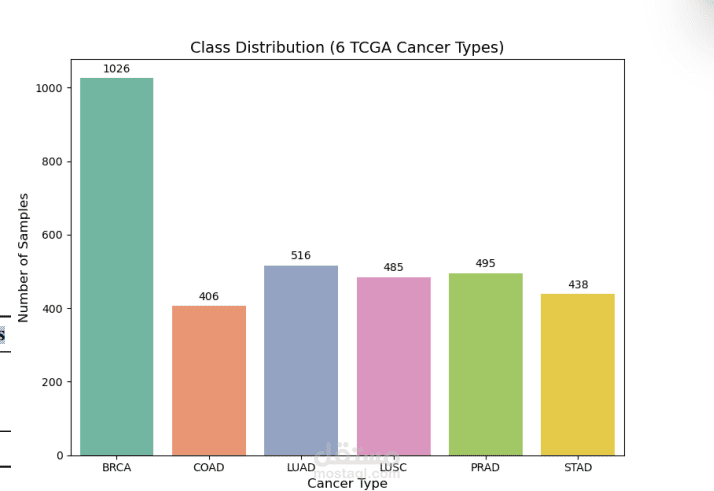
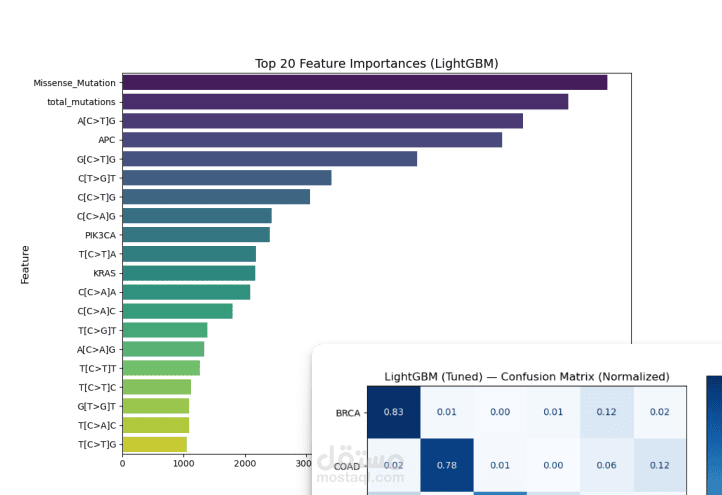
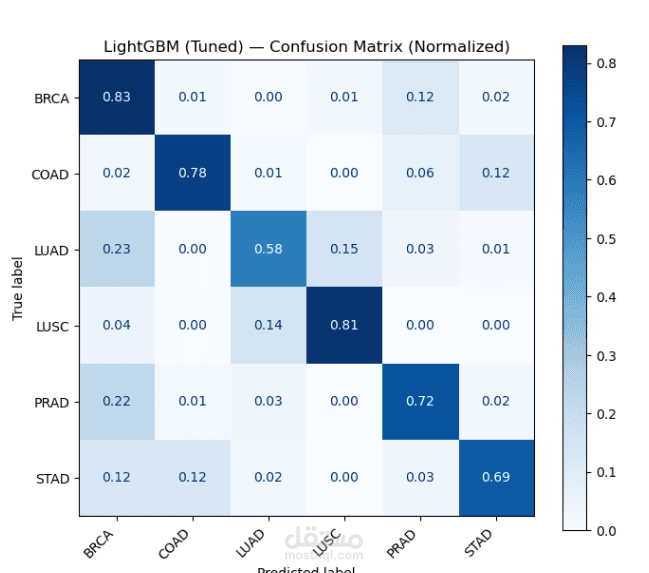
بعد تجهيز البيانات، تم تدريب عدة نماذج تعلم آلي مثل Random Forest وXGBoost وLightGBM لتصنيف ستة أنواع مختلفة من السرطان اعتمادًا على هذه الخصائص. كما تم استخدام تقنيات تقييم النماذج وتحليل أهمية الخصائص لفهم العوامل الأكثر تأثيرًا في عملية التصنيف.
أظهرت النتائج أن نماذج Gradient Boosting مع خصائص التواقيع الطفرية حققت أداءً جيدًا بدقة تقارب 75% في تصنيف أنواع السرطان، كما ساعد تحليل أهمية الخصائص في الكشف عن أنماط طفرية مرتبطة بأنواع سرطانية معينة، مما يساهم في فهم أفضل للعمليات الجينية المرتبطة بالمرض.