SCRAPPING)An Automated End-to-End ETL Pipeline for Market Research)
تفاصيل العمل
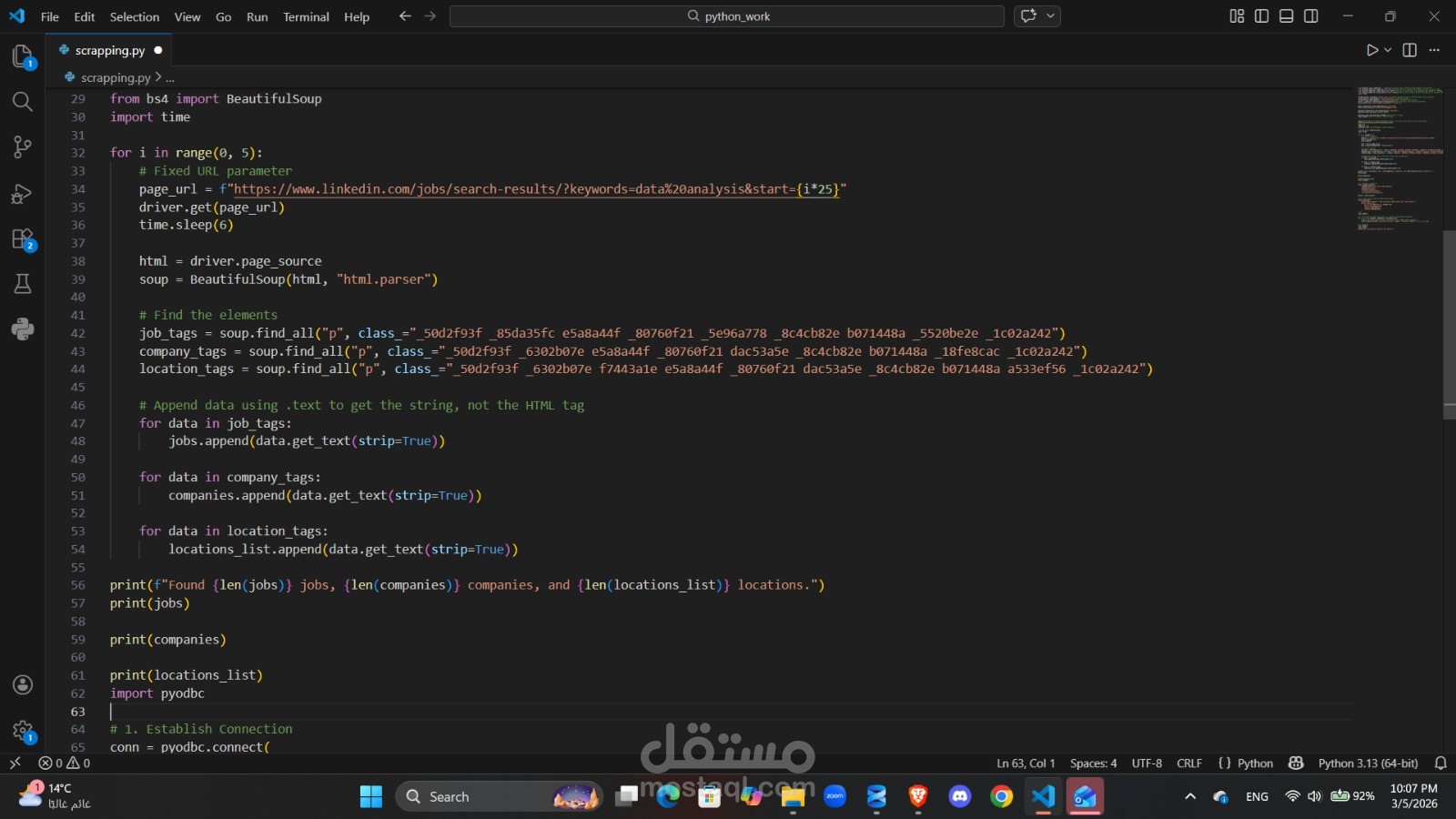
This project is a sophisticated ETL (Extract, Transform, Load) tool designed to automate the collection and storage of job market data from LinkedIn. Using Python and Selenium, the script simulates human browser behavior to bypass initial login walls and navigate through multiple pages of "Data Analyst" job postings.
The raw HTML is then parsed using BeautifulSoup to isolate key data points Job Title, Company Name, and Locationwhich are cleaned and structured. Finally, the processed data is streamed into a SQL Server database, creating a persistent repository that can be used for longitudinal trend analysis, salary benchmarking, or lead generation.
Key Technical Features
Browser Automation: Utilizes Selenium WebDriver with custom Chrome options to handle dynamic content and automated logins.
Web Scraping: Employs BeautifulSoup for precise DOM navigation and data extraction from complex, hashed CSS classes.
Data Persistence: Integrates pyodbc to bridge the gap between Python and SQL Server, including automated table schema generation.
Error Handling: Implements time.sleep and zip logic to ensure data synchronization across multi-page scrapes.