خط أنابيب كشف الاحتيال في بطاقات الائتمان (Credit Card Fraud Detection Pipeline)
تفاصيل العمل
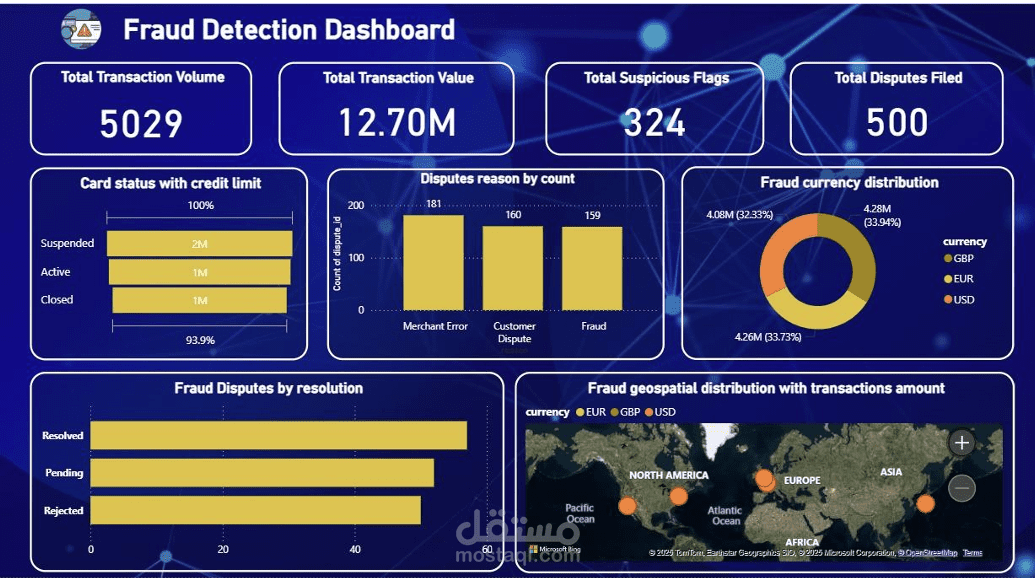
يركّز هذا المشروع على بناء خط معالجة بيانات ضخمة منخفض الكمون (Low-Latency Big Data Pipeline) لاكتشاف عمليات الاحتيال في بطاقات الائتمان. يقوم النظام باستقبال كميات كبيرة من بيانات المعاملات من قاعدة بيانات MariaDB باستخدام Apache Sqoop، ثم معالجتها باستخدام PySpark، وتخزين البيانات بعد تحويلها في Hive وفق تصميم Star Schema.
يعتمد خط المعالجة على تحليلات السلاسل الزمنية مثل حساب الوقت منذ آخر معاملة ومجاميع المعاملات المتحركة، بالإضافة إلى فحوصات سرعة المعاملات (Velocity Checks) وتقنيات التجزئة الجغرافية (Geospatial Hashing) للكشف عن الأنماط المشبوهة في النشاط المالي. كما تم تطبيق تقنيات تحسين الأداء مثل التخزين المؤقت (Caching) و Broadcast Joins و تقسيم البيانات (Partitioning) لضمان معالجة موزعة قابلة للتوسع.
وفي النهاية، ينتج النظام جداول Hive جاهزة للتحليل، مما يتيح إجراء استعلامات سريعة ودعم عمليات التحقيق الاستباقي في حالات الاحتيال.