تنظيف ومعالجة بيانات مجموعة بيانات "Candy Hierarchy" باستخدام Python.
تفاصيل العمل
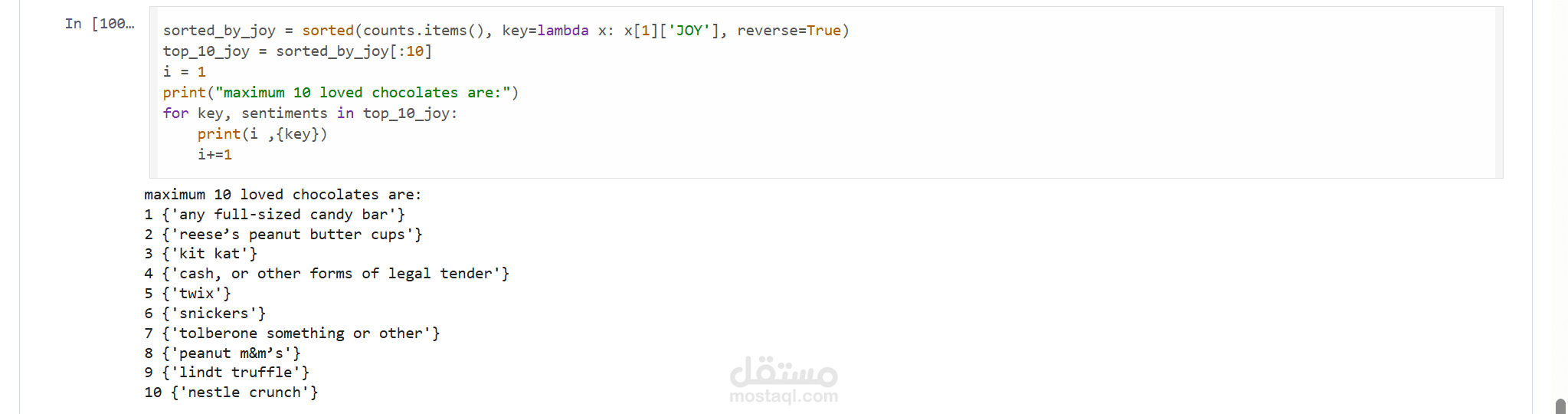
في هذا المشروع، قمت بالتعامل مع واحدة من أكثر مجموعات البيانات تعقيداً (Candy Hierarchy Dataset) والتي تحتوي على الكثير من البيانات غير المنظمة والمفقودة. قمت برحلة كاملة لتنظيف البيانات وتحويلها إلى شكل جاهز للتحليل الإحصائي.
المهام التي قمت بها:
معالجة القيم المفقودة (Handling Missing Values): اتخاذ قرارات دقيقة بشأن حذف أو تعويض البيانات الناقصة.
توحيد البيانات (Data Standardization): توحيد صيغ النصوص (مثل أسماء الدول والأعمار) التي كانت مكتوبة بطرق عشوائية.
إزالة التكرار (Dropping Duplicates): التأكد من أن كل سجل في البيانات فريد وصحيح.
هندسة البيانات (Feature Engineering): استخراج معلومات مفيدة من أعمدة غير منظمة.
الأدوات المستخدمة: Python, Pandas, NumPy.
يمكنكم الإطلاع على الكود الكامل عبر رابط GitHub المرفق.