Sentiment Analysis Project -مشروع تحليل المشاعر
تفاصيل العمل
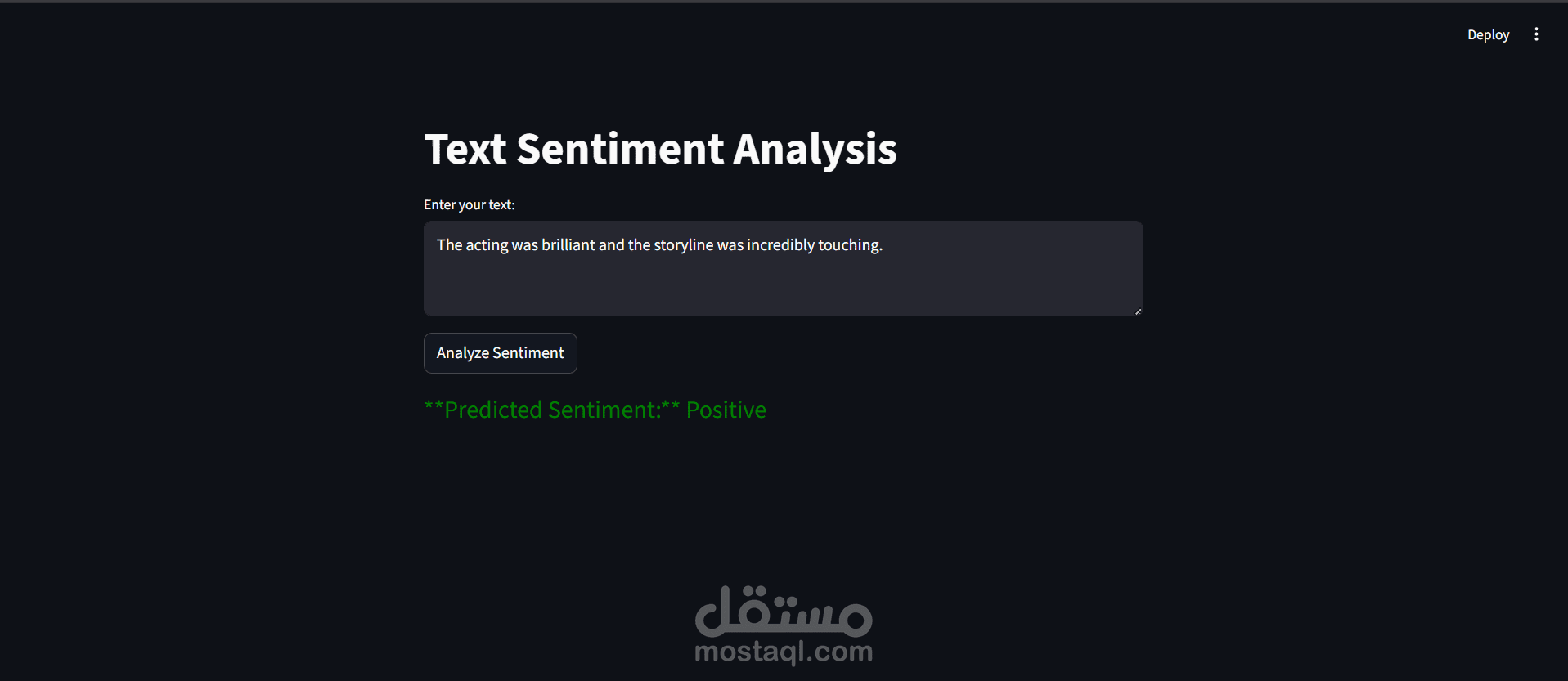

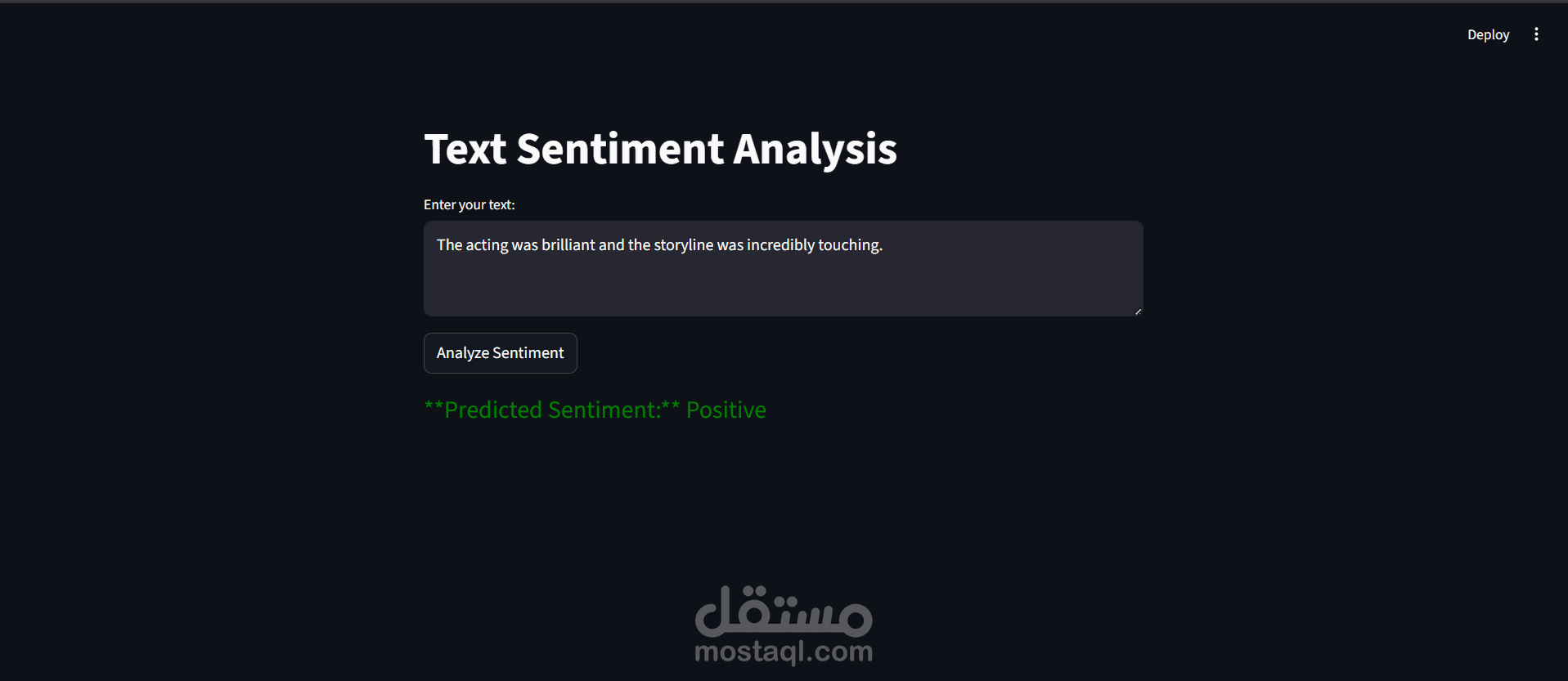
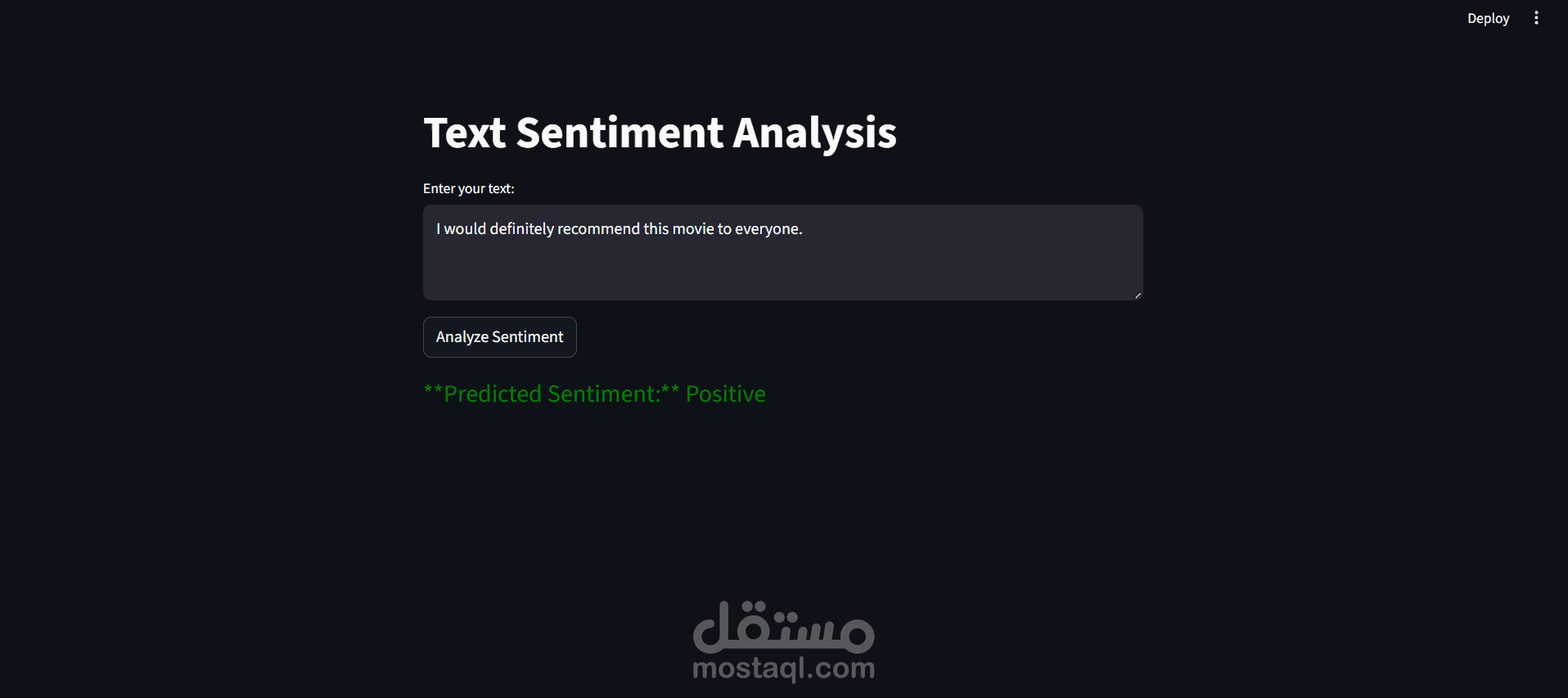

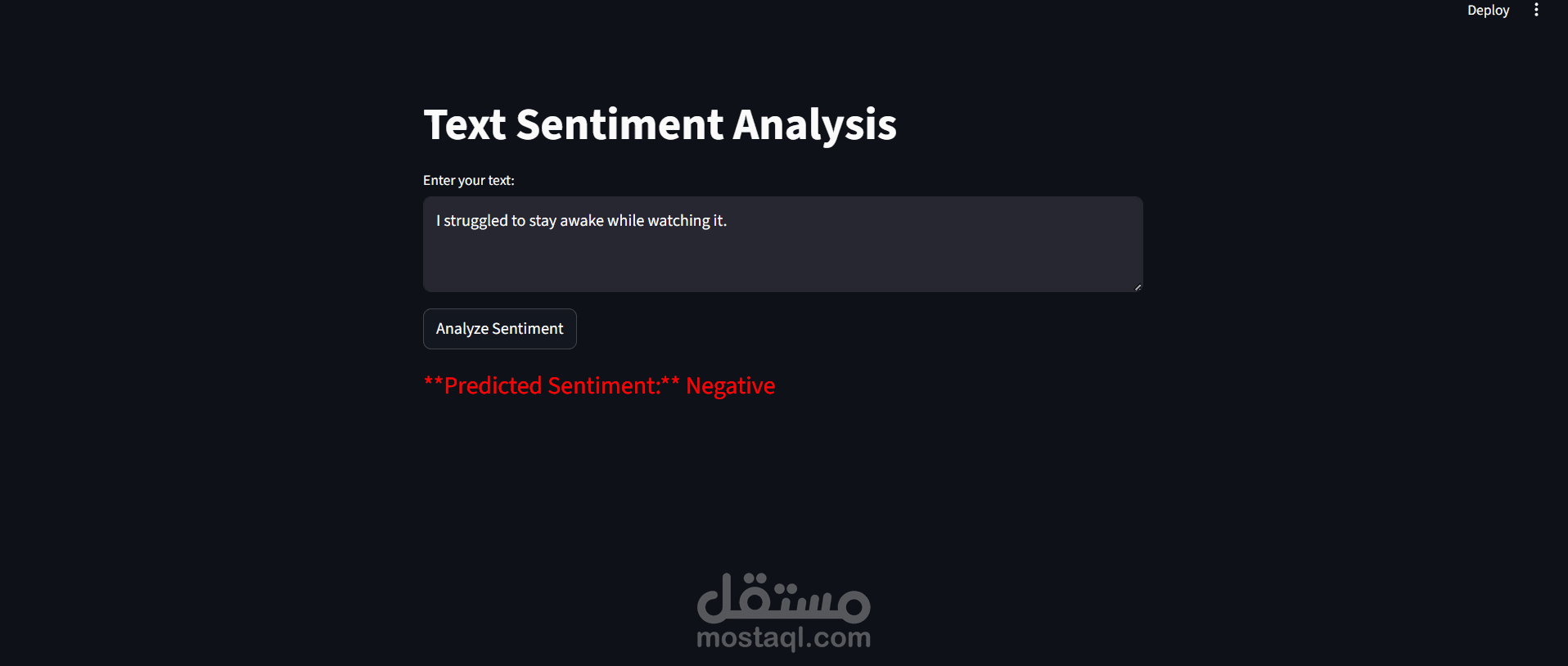
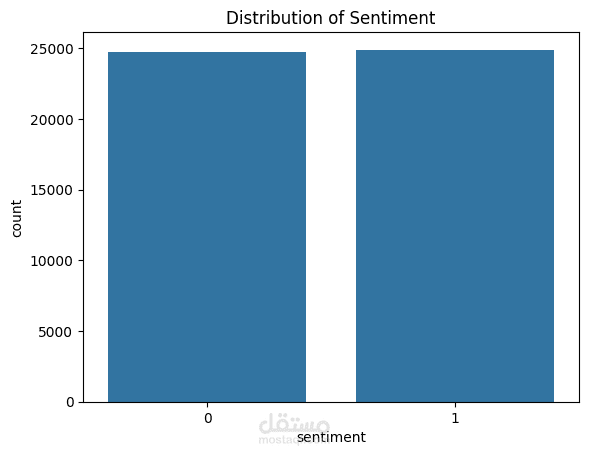
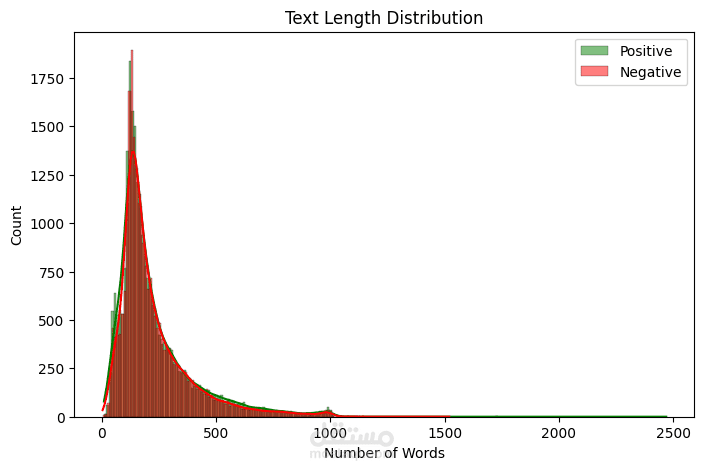
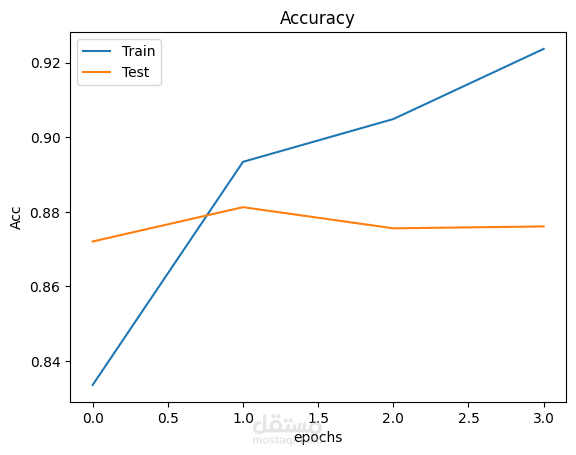
قمت بتطوير نموذج تحليل مشاعر (Sentiment Analysis) باستخدام تقنيات Deep Learning لتصنيف مراجعات الأفلام إلى إيجابية أو سلبية بدقة عالية.
? هدف المشروع
بناء نظام ذكي قادر على فهم النصوص وتحليل المشاعر تلقائيًا، مع إمكانية استخدامه في:
تحليل آراء العملاء
تقييم المنتجات
تحليل تعليقات وسائل التواصل الاجتماعي
دعم اتخاذ القرار القائم على البيانات
? خطوات تنفيذ المشروع
✔ تنظيف البيانات النصية (إزالة الروابط، Stopwords، توحيد الحروف)
✔ تحويل التصنيفات إلى قيم رقمية (Positive → 1 | Negative → 0)
✔ Tokenization وتحويل النصوص إلى Sequences
✔ تطبيق Padding لتوحيد طول المدخلات
✔ بناء نموذج LSTM مع Embedding Layer
✔ استخدام Dropout لتقليل الـ Overfitting
✔ تطبيق Early Stopping لتحسين التعميم
✔ تحليل توزيع البيانات وطول النصوص قبل التدريب
✔ تقييم النموذج على بيانات اختبار غير مرئية
✔ حفظ النموذج و Tokenizer لاستخدامهم في أي تطبيق مستقبلي
⚙️ المعمارية المستخدمة
Embedding Layer → LSTM → Dropout → Dense (Sigmoid)
? التقنيات المستخدمة
Python
Pandas & NumPy
Matplotlib & Seaborn
NLTK
Scikit-learn
TensorFlow / Keras
Pickle
? التحديات التي تم التعامل معها
? معالجة اختلاف أطوال النصوص
? تقليل Overfitting
? تحسين جودة البيانات النصية
? اختيار طول تسلسل مناسب للحفاظ على السياق
? النتائج
✔ دقة قوية على بيانات الاختبار
✔ توازن جيد بين بيانات التدريب والتحقق
✔ نموذج قابل لإعادة الاستخدام والتطوير في مشاريع NLP مستقبلية