تحليل وتوقع مخاطر أمراض القلب باستخدام تعلم الآلة
تفاصيل العمل

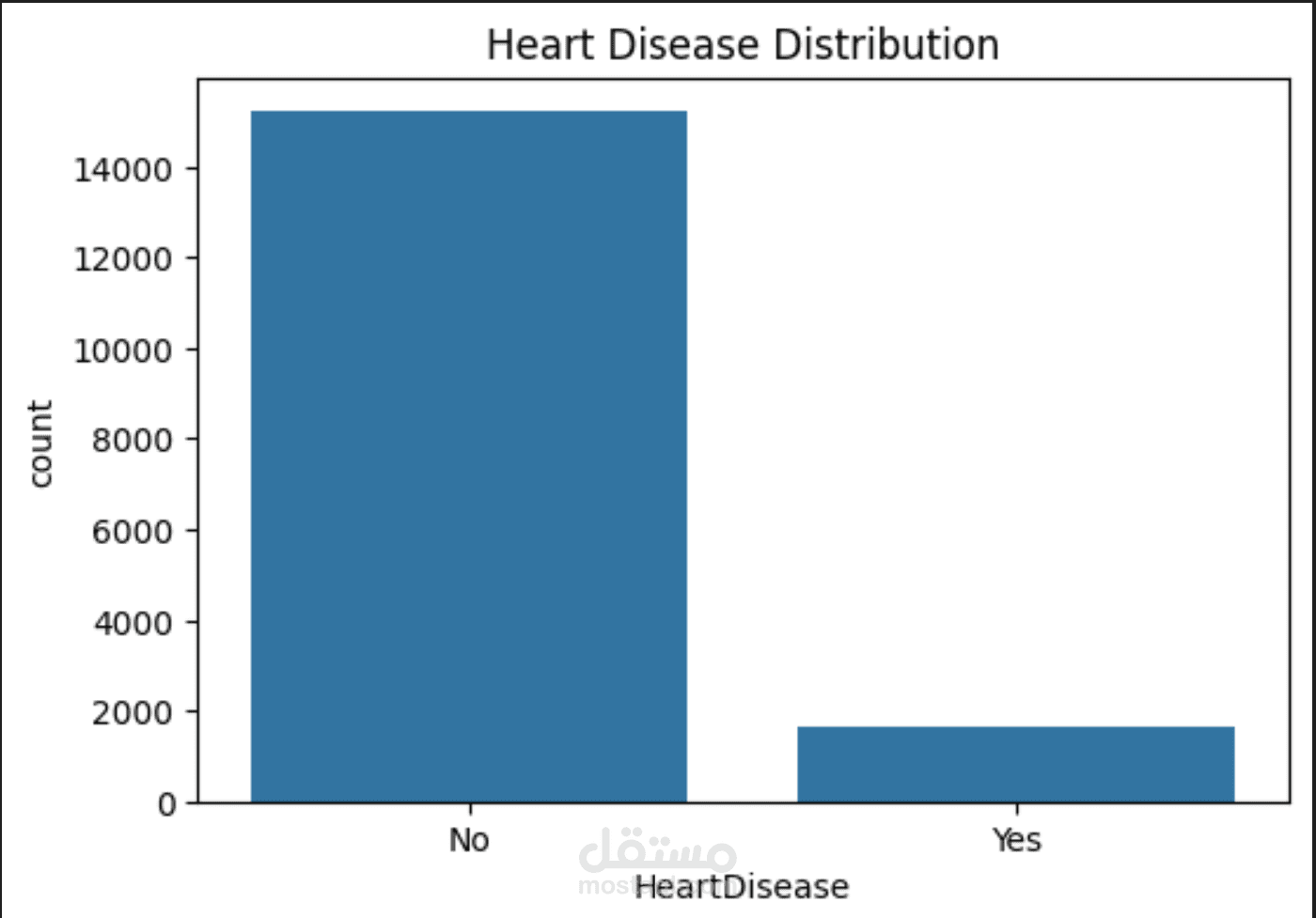
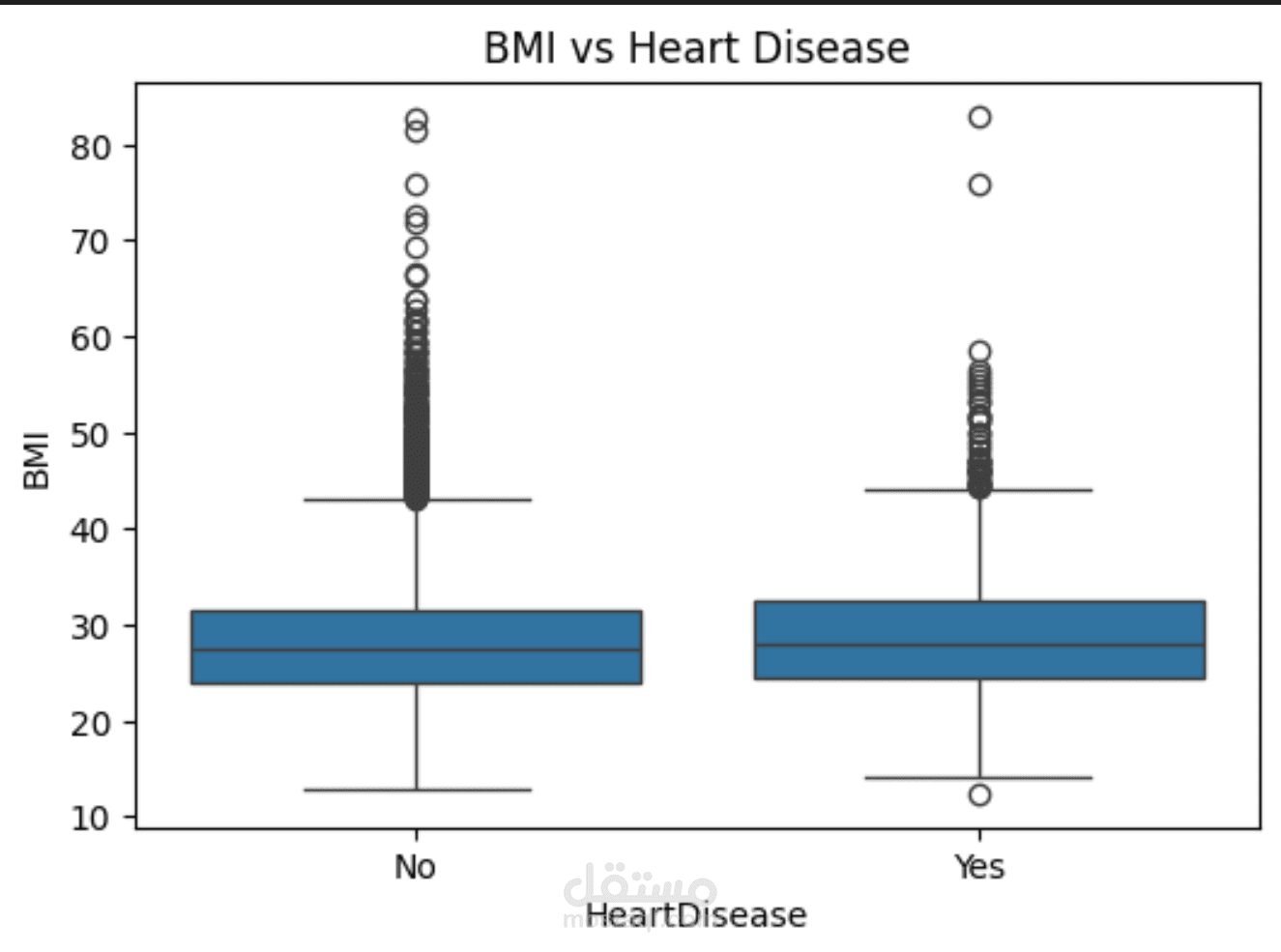
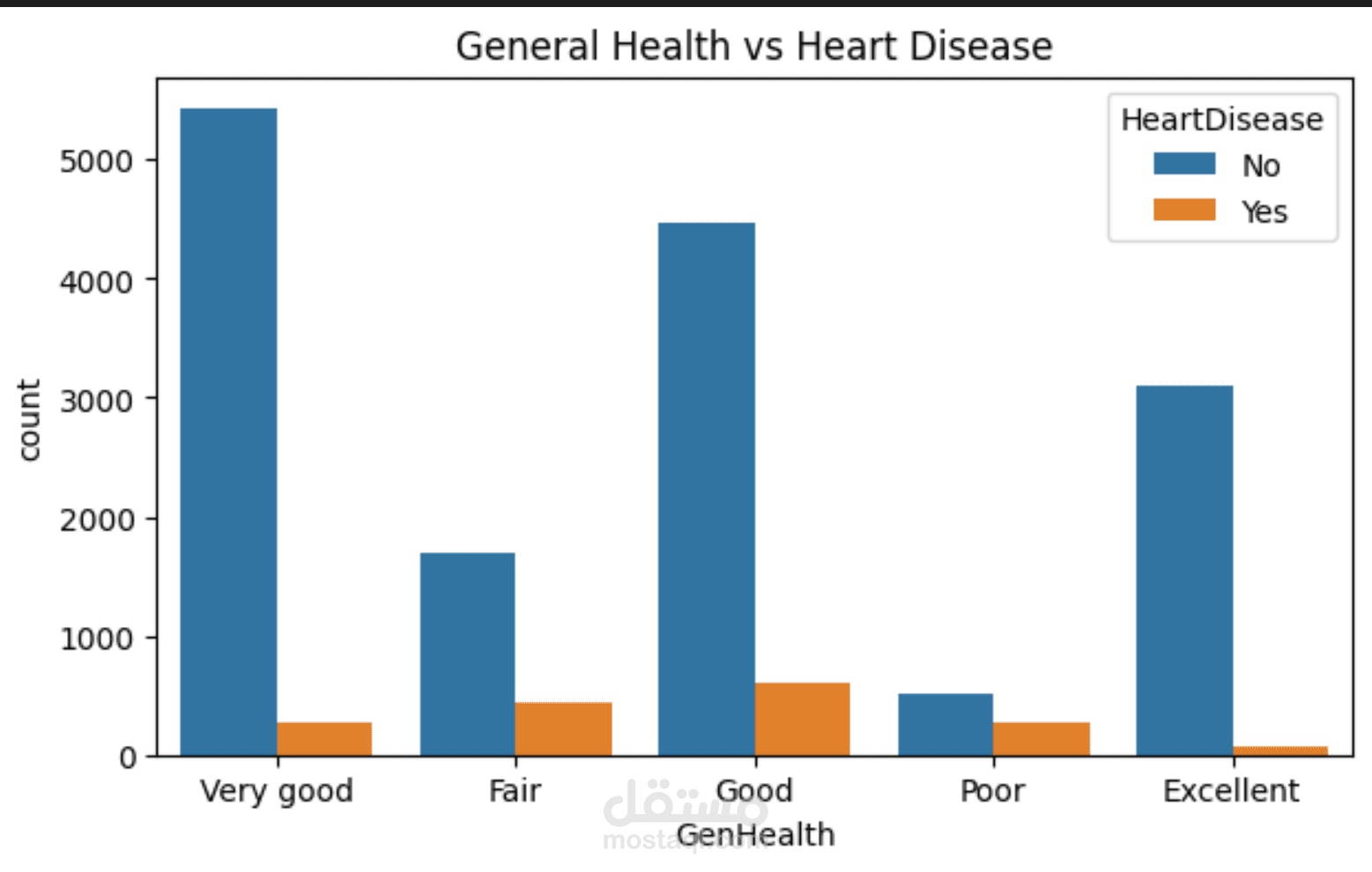
مشروع متكامل لعلوم البيانات (Data Science) يهدف إلى تحليل العوامل المؤثرة على أمراض القلب وبناء نموذج تنبؤي دقيق. تم العمل على مجموعة بيانات طبية تحتوي على أكثر من 16,000 سجل و18 ميزة (Feature).
أبرز ما قمت به في المشروع:
استكشاف البيانات (EDA): تحليل توزيع الميزات (BMI, SleepTime, PhysicalHealth) واكتشاف العلاقات بينها وبين الإصابة بأمراض القلب باستخدام مكتبات Matplotlib و Seaborn.
معالجة البيانات (Data Preprocessing):
التعامل مع القيم المفقودة (Imputation) باستخدام الوسيط (Median).
تحويل البيانات الفئوية (Categorical Encoding) باستخدام تقنيات (Label, Ordinal, and One-Hot Encoding) مع مراعاة الترتيب المنطقي لبعض الميزات مثل الفئات العمرية والحالة الصحية.
هندسة الميزات (Feature Engineering): تطبيق الـ RobustScaler للتعامل مع القيم الشاذة (Outliers) في البيانات الحيوية.
بناء خطوط المعالجة (Pipelines): تصميم "Pipeline" احترافي لضمان تطبيق العمليات بترتيب صحيح ومنع تسرب البيانات (Data Leakage) أثناء التدريب.
التعامل مع البيانات غير المتوازنة: استخدام Stratified Splitting لضمان تمثيل عادل لحالات الإصابة في مجموعات التدريب والاختبار.
الأدوات المستخدمة:
Python (Pandas, NumPy)
Scikit-Learn (Preprocessing, Pipelines, Modeling)
Visualization (Seaborn, Matplotlib)