create a diebtes model using machine learning model
تفاصيل العمل
هذا التطبيق يهدف إلى توقع خطر الإصابة بمرض السكري بناءً على بيانات المريض. يقوم المستخدم بإدخال مجموعة من القياسات الصحية، ثم يقوم النموذج بالتنبؤ بما إذا كان الشخص معرضاً للإصابة بالسكري أم لا.
المتغيرات المستخدمة في النموذج (المدخلات)
التطبيق يعتمد على 8 متغيرات رئيسية:
Pregnancies: عدد حالات الحمل السابقة
Glucose Level: مستوى الجلوكوز في الدم
BloodPressure: ضغط الدم
Skin Thickness: سمك الجلد
Insulin Level: مستوى الأنسولين
BMI: مؤشر كتلة الجسم
DiabetesPedigreeFunction: دالة تاريخ العائلة للإصابة بالسكري (عامل وراثي)
Age: العمر
النماذج المستخدمة في المشروع
لقد قمت ببناء نظام تنبؤ باستخدام ثلاثة نماذج مختلفة:
1. نموذج الانحدار اللوجستي (Logistic Regression)
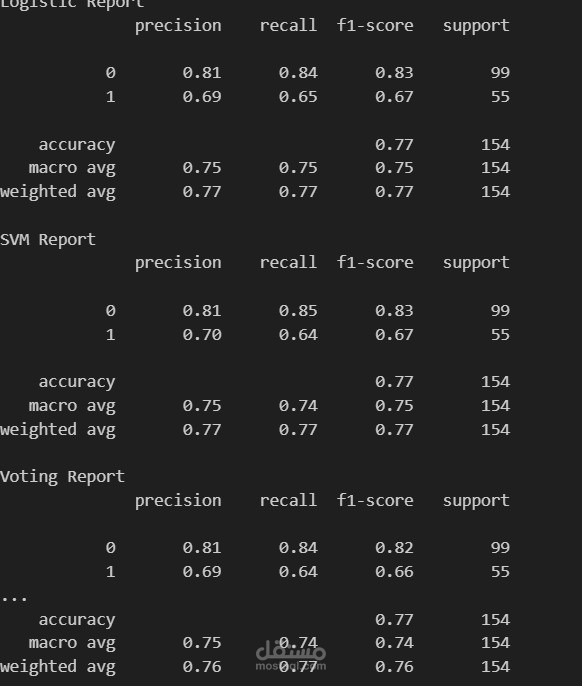
الدقة: 77%
هذا النموذج هو أحد أبسط وأشهر خوارزميات التصنيف في التعلم الآلي
يعمل عن طريق تقدير احتمالية انتماء البيانات إلى فئة معينة (مصاب / غير مصاب) باستخدام دالة لوجستية (Sigmoid Function)
مميزاته: سريع، لا يحتاج إلى موارد حاسوبية كبيرة، وسهل التفسير
عيوبه: قد لا يلتقط العلاقات المعقدة في البيانات بشكل جيد
2. نموذج آلة المتجهات الداعمة (SVM - Support Vector Machine)
الدقة: 77.2%
يعمل هذا النموذج عن طريق إيجاد الخط أو المستوى الأمثل (Hyperplane) الذي يفصل بين الفئتين (مصاب وغير مصاب) بأكبر هامش ممكن
يمكنه استخدام دوال رياضية (Kernels) لتحويل البيانات إلى أبعاد أعلى لتسهيل عملية الفصل
مميزاته: فعال في المساحات عالية الأبعاد، وقوي في التعامل مع الحالات التي يكون فيها الفصل بين الفئات غير واضح
عيوبه: قد يكون بطيئاً مع مجموعات البيانات الكبيرة جداً
3. نموذج التصويت المجمع (Voting Classifier)
الدقة: 76%
هذا النموذج ليس خوارزمية جديدة بحد ذاتها، بل هو تقنية تجمع بين عدة نماذج مختلفة للوصول إلى قرار نهائي
يعمل بطريقة "التصويت" حيث يأخذ رأي كل من نموذج الانحدار اللوجستي ونموذج SVM
في نسخة "التصويت الصلب" (Hard Voting)، يقوم النموذج باختيار الفئة التي حصلت على أكبر عدد من الأصوات من النماذج المختلفة
الهدف من هذه الطريقة هو تقليل التباين (Variance) وتحسين دقة التنبؤ بشكل عام
تحليل النتائج
نموذج SVM هو الأفضل بين النماذج الفردية بدقة 77.2%
نموذج الانحدار اللوجستي قريب جداً منه بدقة 77%
نموذج التصويت المجمع أعطى دقة 76%، وهي أقل قليلاً من النماذج الفردية
هذا يشير إلى أن النماذج الفردية تعمل بشكل جيد، وقد يكون هناك تداخل كبير في طريقة تنبؤ النموذجين، مما يقلل من فائدة التجميع. في بعض الأحيان، إذا كانت النماذج متشابهة جداً في أدائها، فإن التصويت المجمع لا يحسن الدقة بالضرورة.