classification
تفاصيل العمل
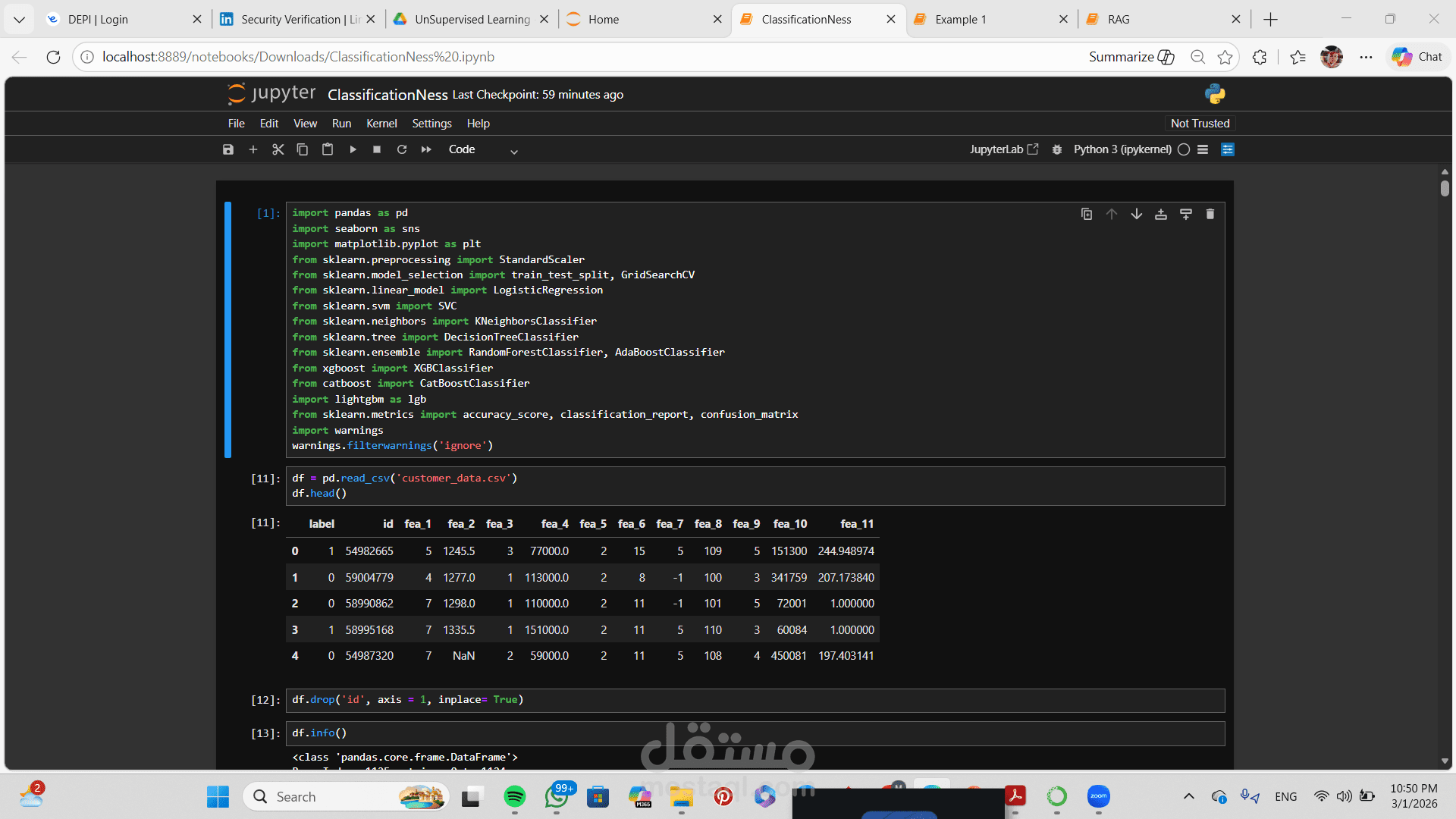

مشروع Machine Learning Classification يهدف إلى تصنيف البيانات إلى فئات محددة بناءً على مجموعة من الخصائص (Features).
المشروع يعتمد على خوارزميات تعلم آلي مختلفة لبناء نموذج قادر على التنبؤ بالفئة الصحيحة بدقة عالية.
مميزات المشروع (Key Features)
تنظيف البيانات (Data Cleaning)
تحليل استكشافي للبيانات (EDA)
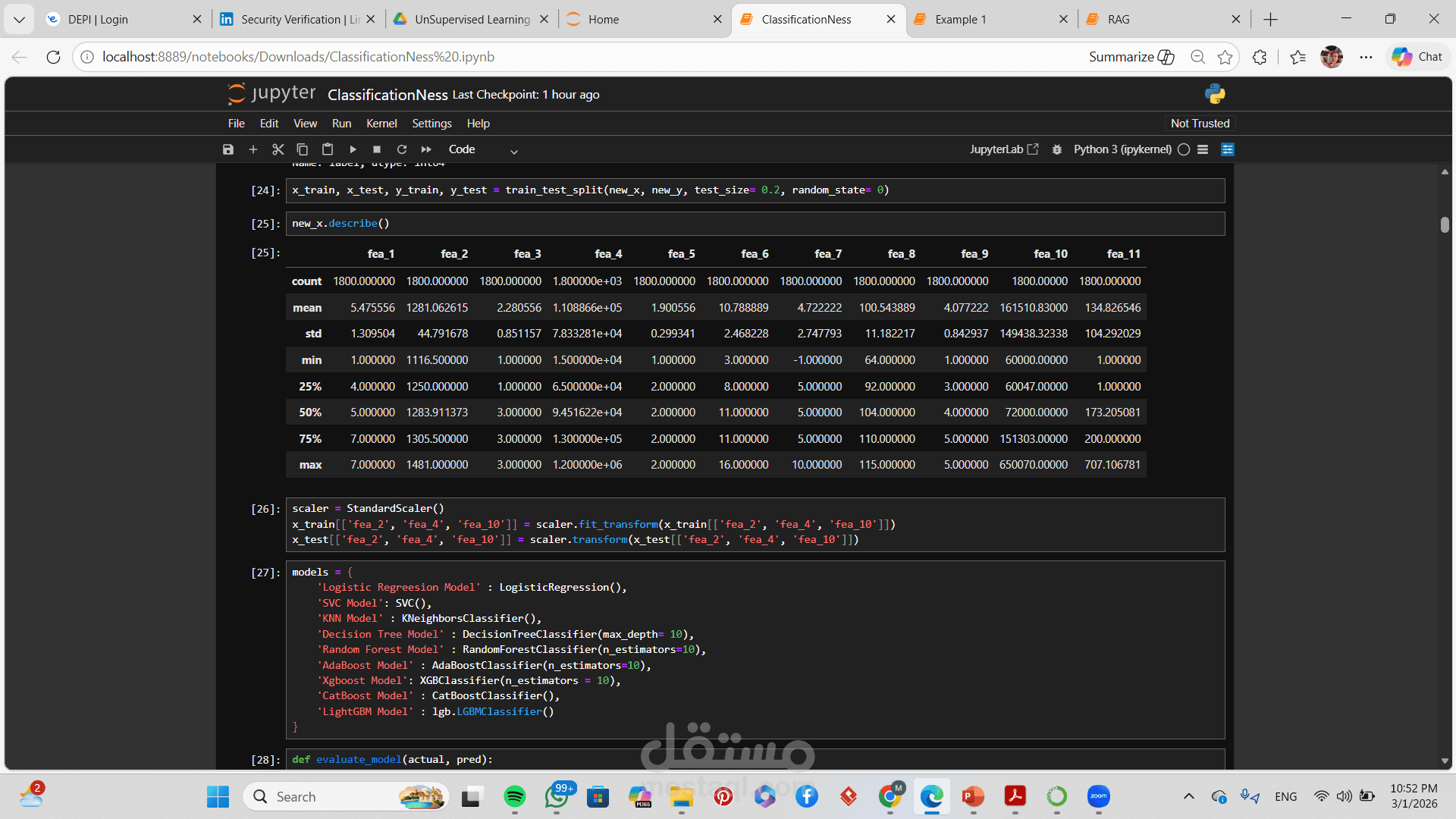
معالجة القيم المفقودة والـ Outliers
Feature Engineering & Feature Selection
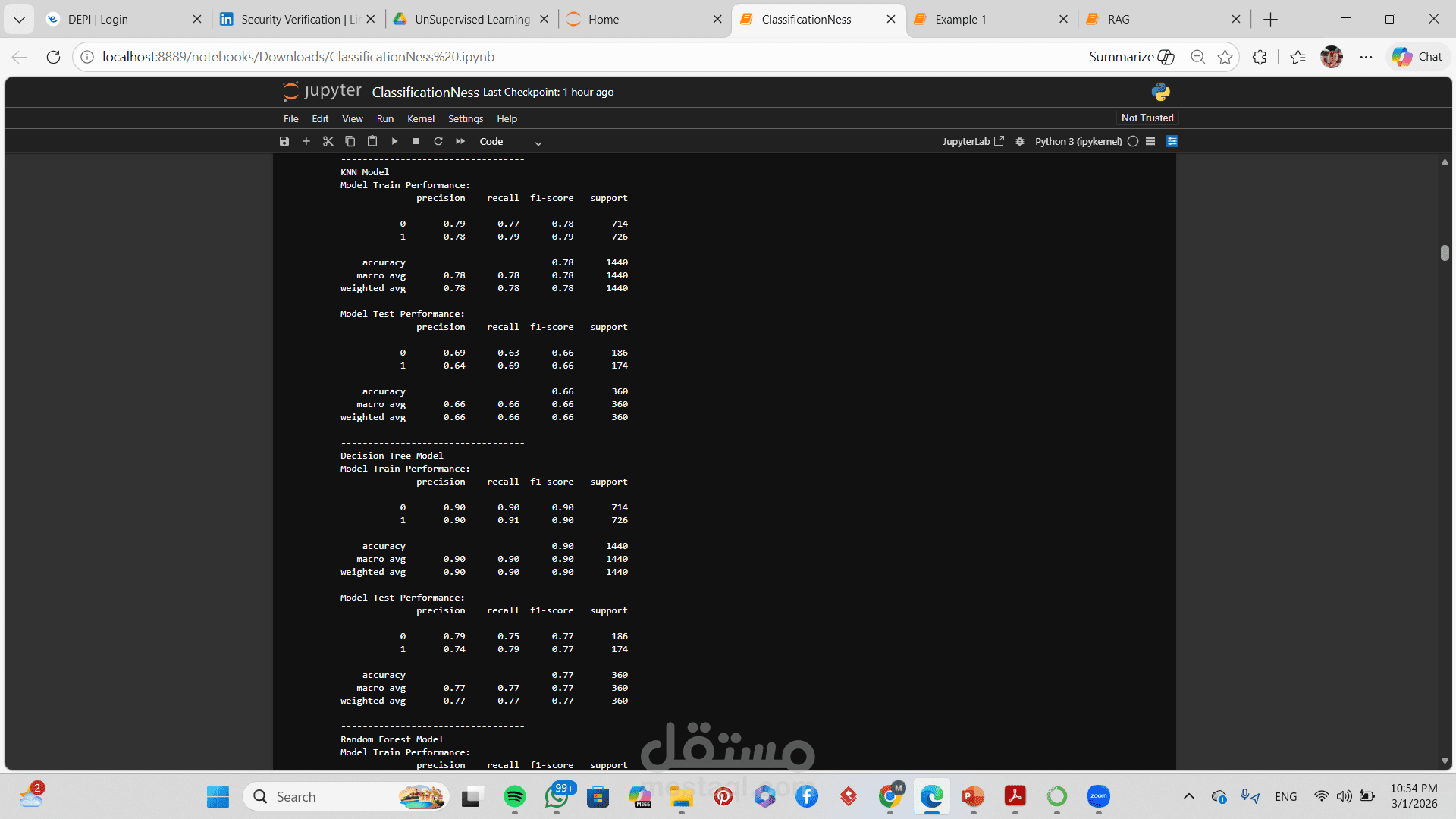
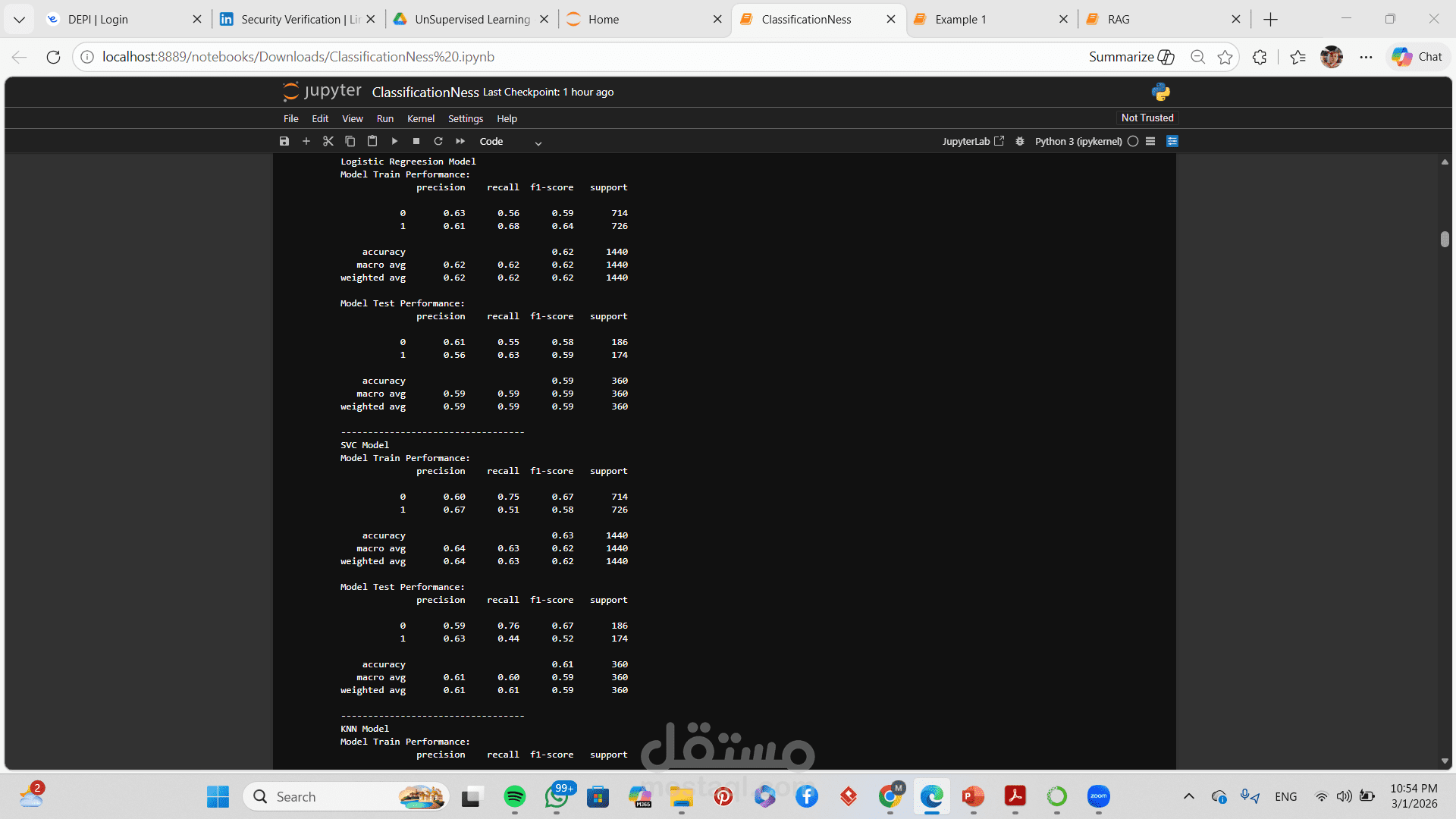
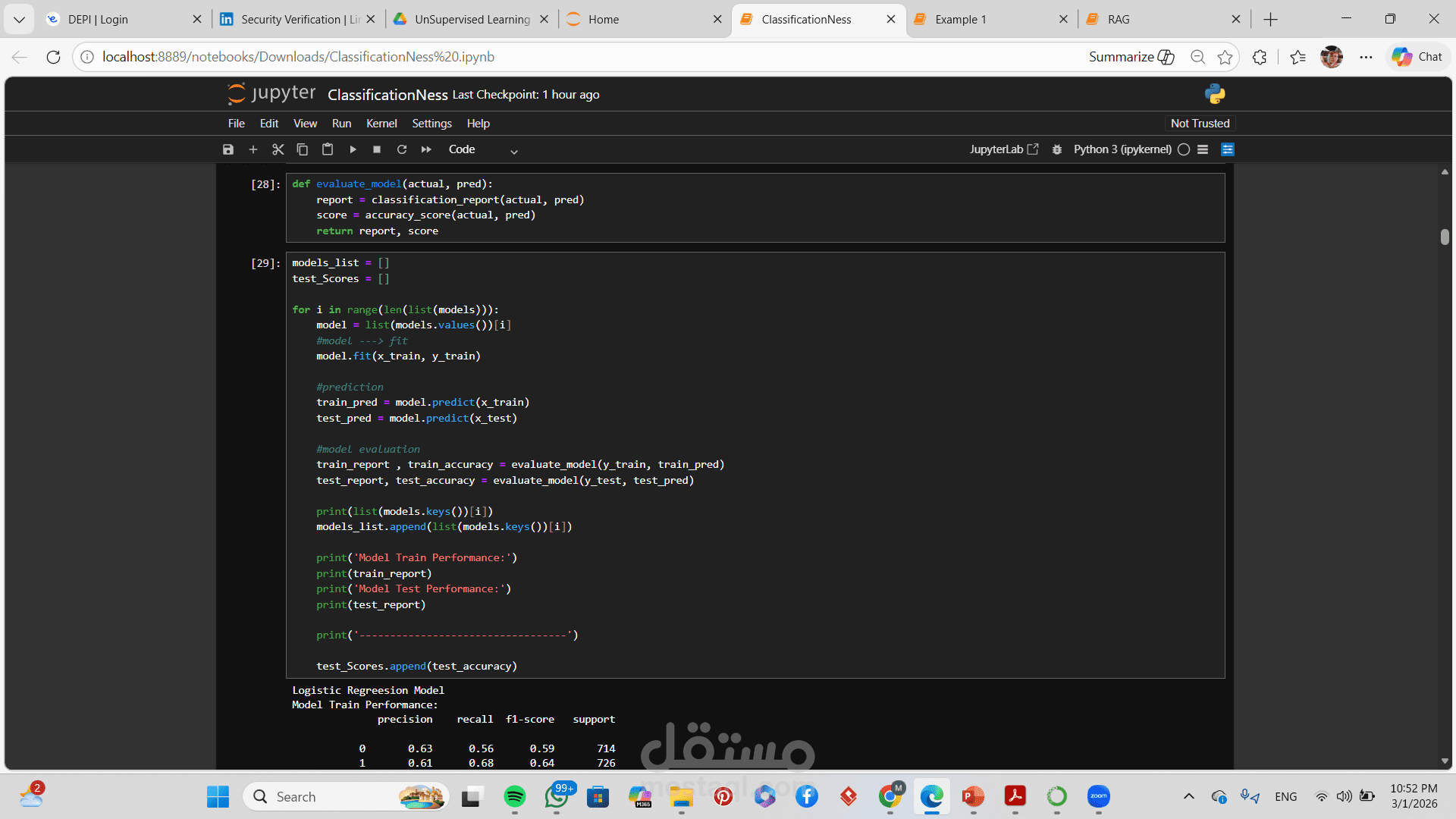
تطبيق أكثر من خوارزمية تصنيف (مثل Logistic Regression, Decision Tree, Random Forest, SVM)
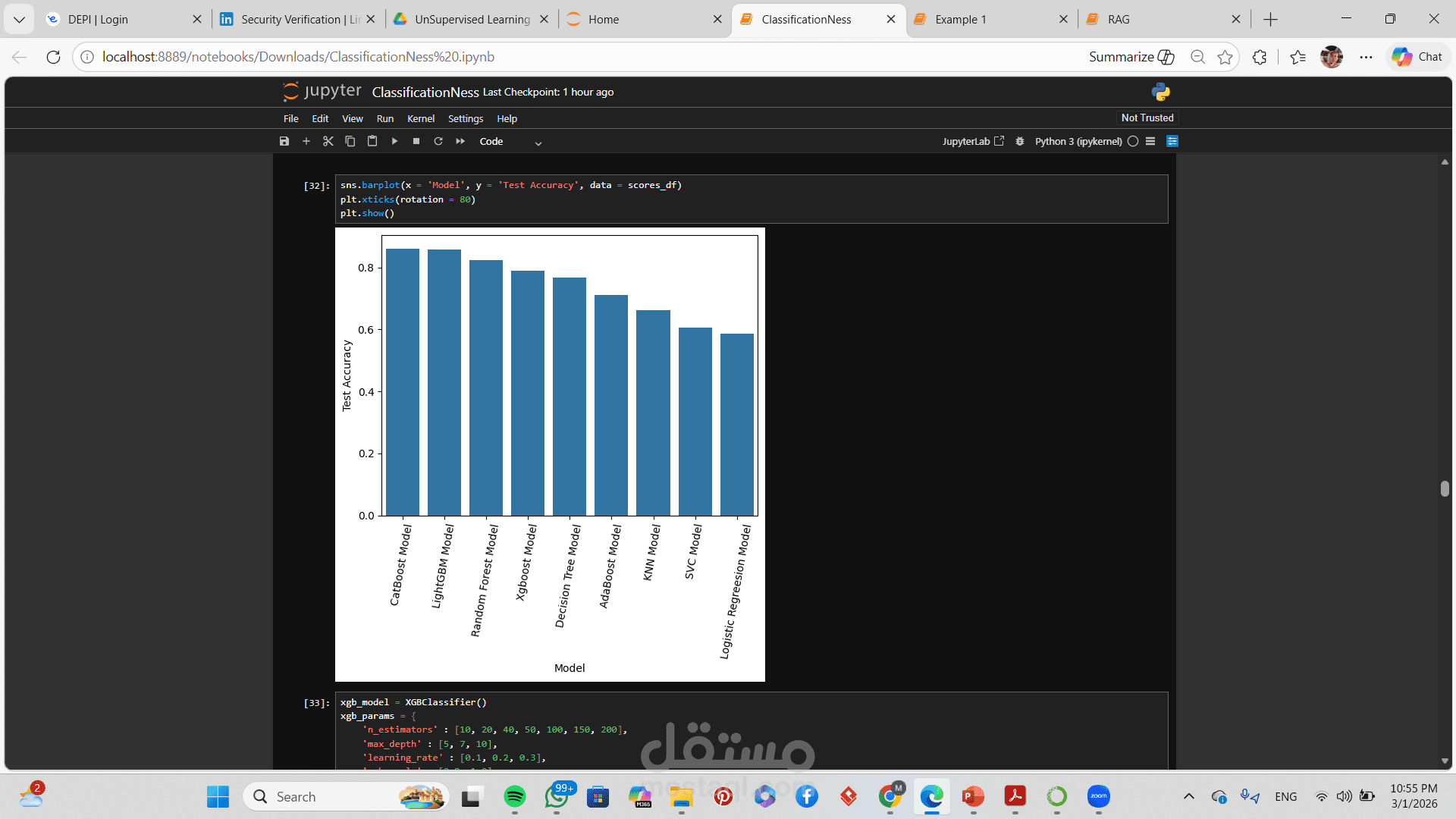
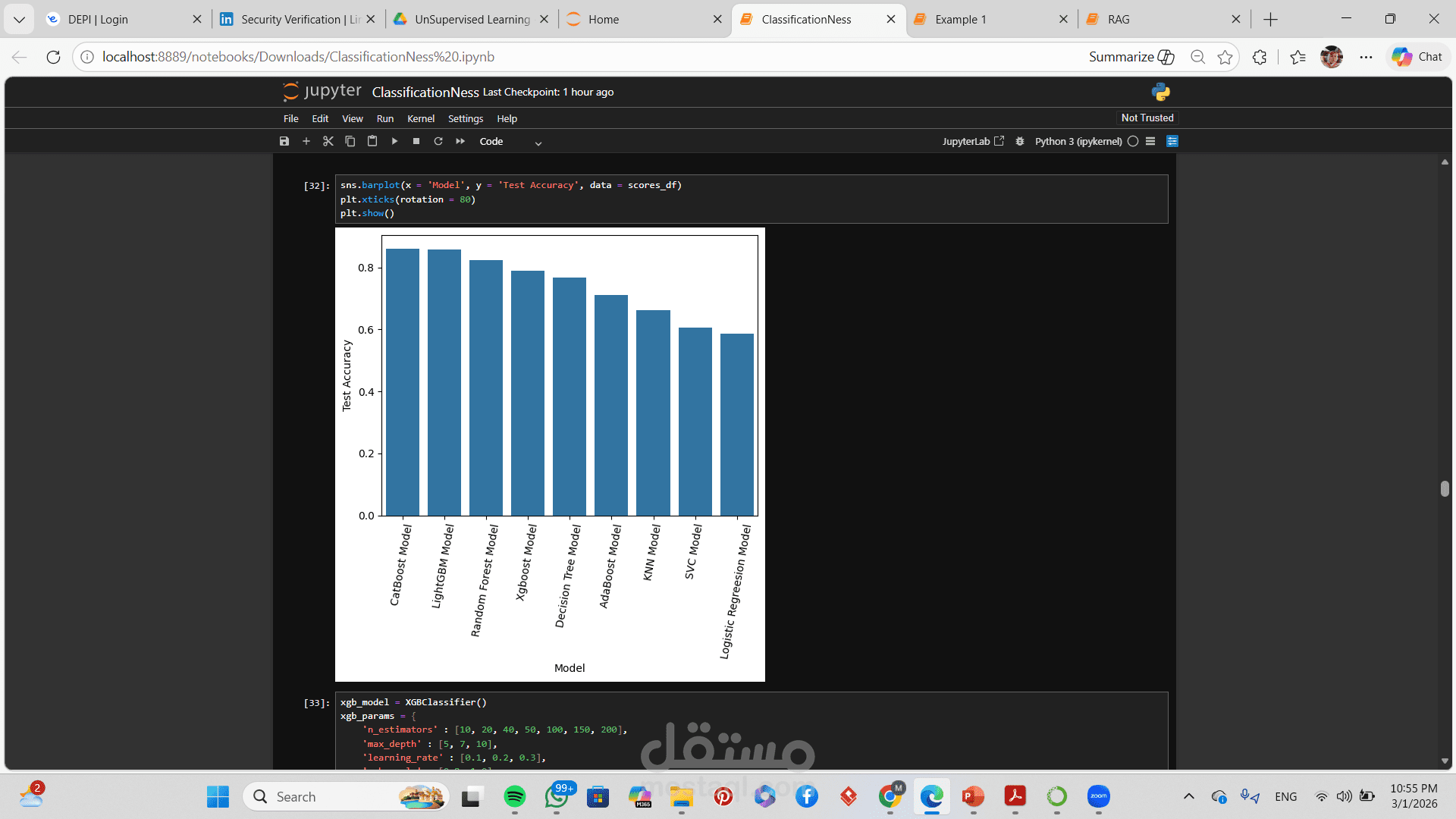
مقارنة بين أداء النماذج المختلفة
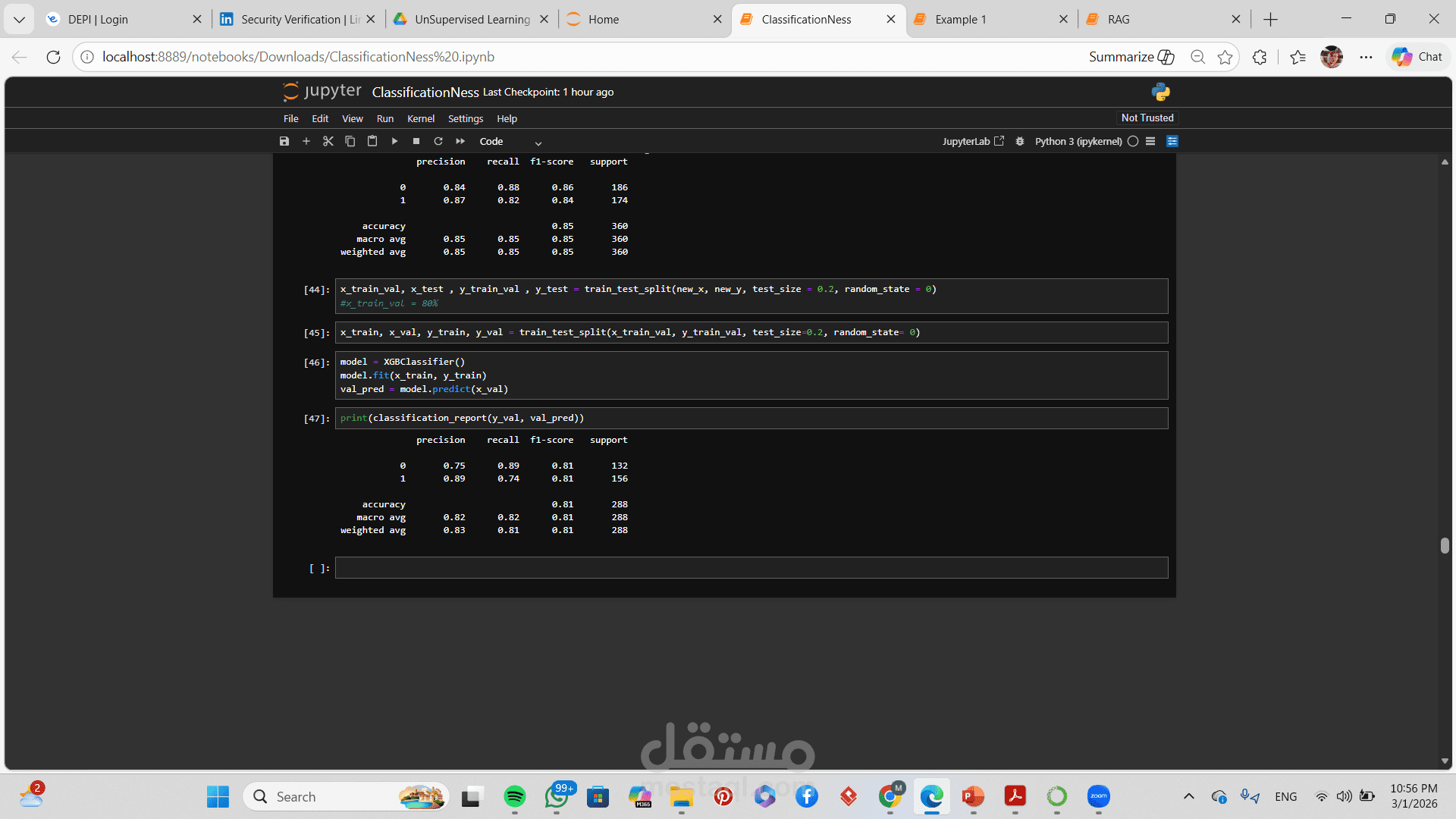
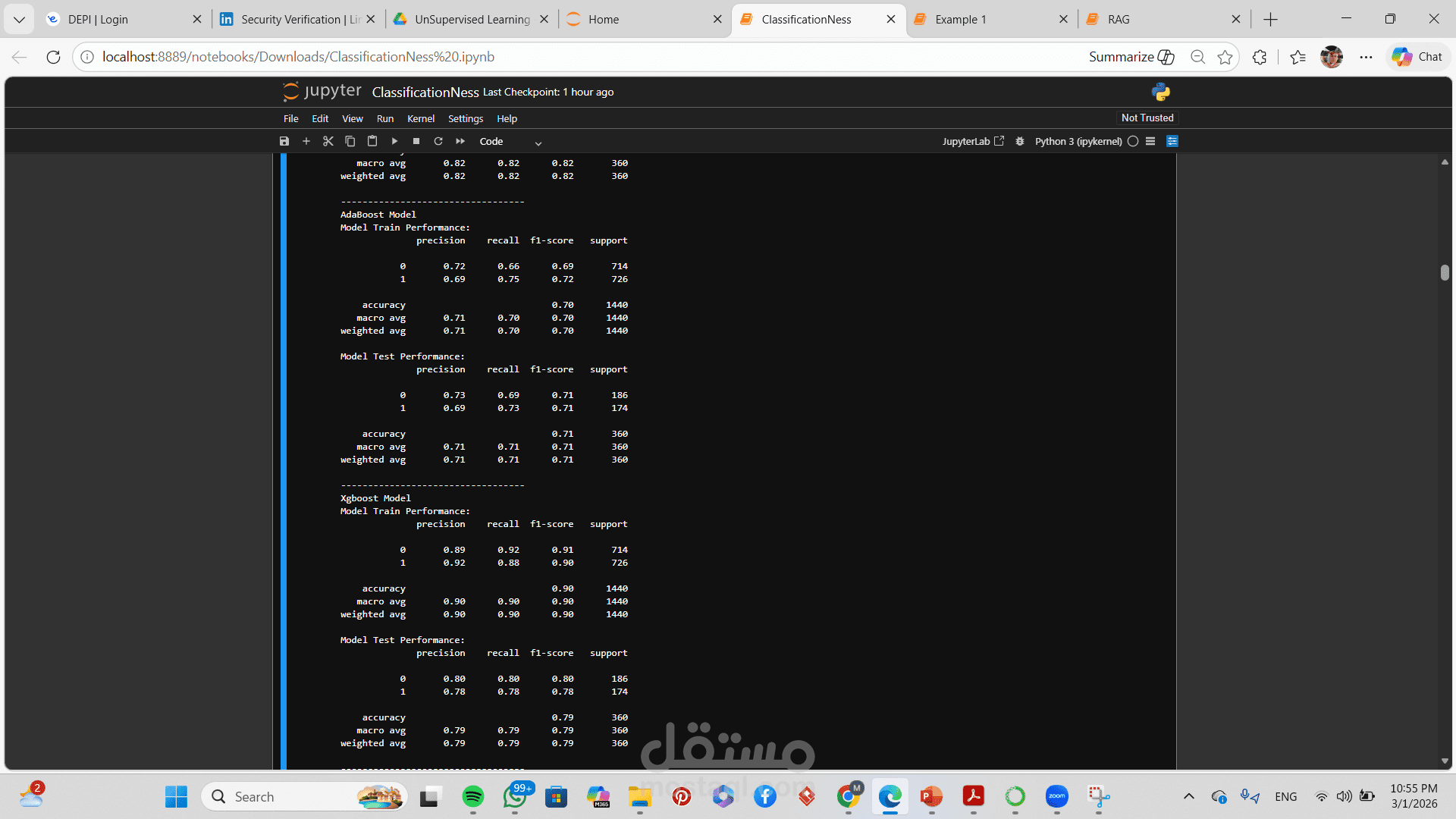
تقييم الأداء باستخدام:
Accuracy
Precision
Recall
F1-Score
Confusion Matrix
طريقة التنفيذ (Implementation Process)
1️⃣ تحميل البيانات وفهمها
2️⃣ تنظيف البيانات ومعالجتها
3️⃣ إجراء تحليل استكشافي (EDA) باستخدام الرسوم البيانية
4️⃣ تقسيم البيانات إلى Training و Testing
5️⃣ تدريب عدة نماذج تصنيف
6️⃣ تقييم الأداء باستخدام Metrics مختلفة
7️⃣ اختيار أفضل نموذج بناءً على النتائج