نظام تنبؤ بالانتماء الحزبي باستخدام خوارزميات تعلم الآلة (دراسة حالة: مجلس النواب الأمريكي)
تفاصيل العمل
قمت في هذا المشروع ببناء نموذج تعلم آلة (Classification Model) لتحليل بيانات التصويت لأعضاء مجلس النواب الأمريكي والتنبؤ بانتمائهم الحزبي (ديمقراطي أو جمهوري) بناءً على سجلات تصويتهم في 16 قضية مختلفة.
أبرز المهام التي قمت بها:
معالجة البيانات (Data Preprocessing): التعامل مع القيم المفقودة (Missing Values) والبيانات المتكررة، وتحويل البيانات الفئوية إلى أرقام لتناسب النماذج الرياضية.
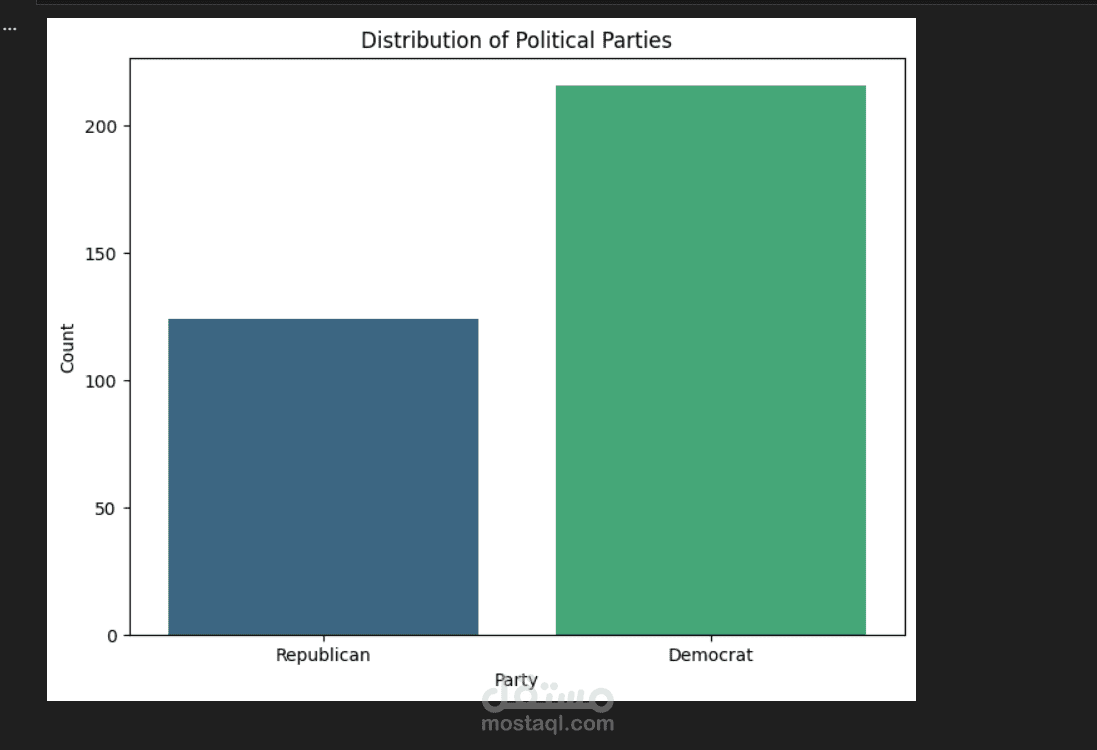
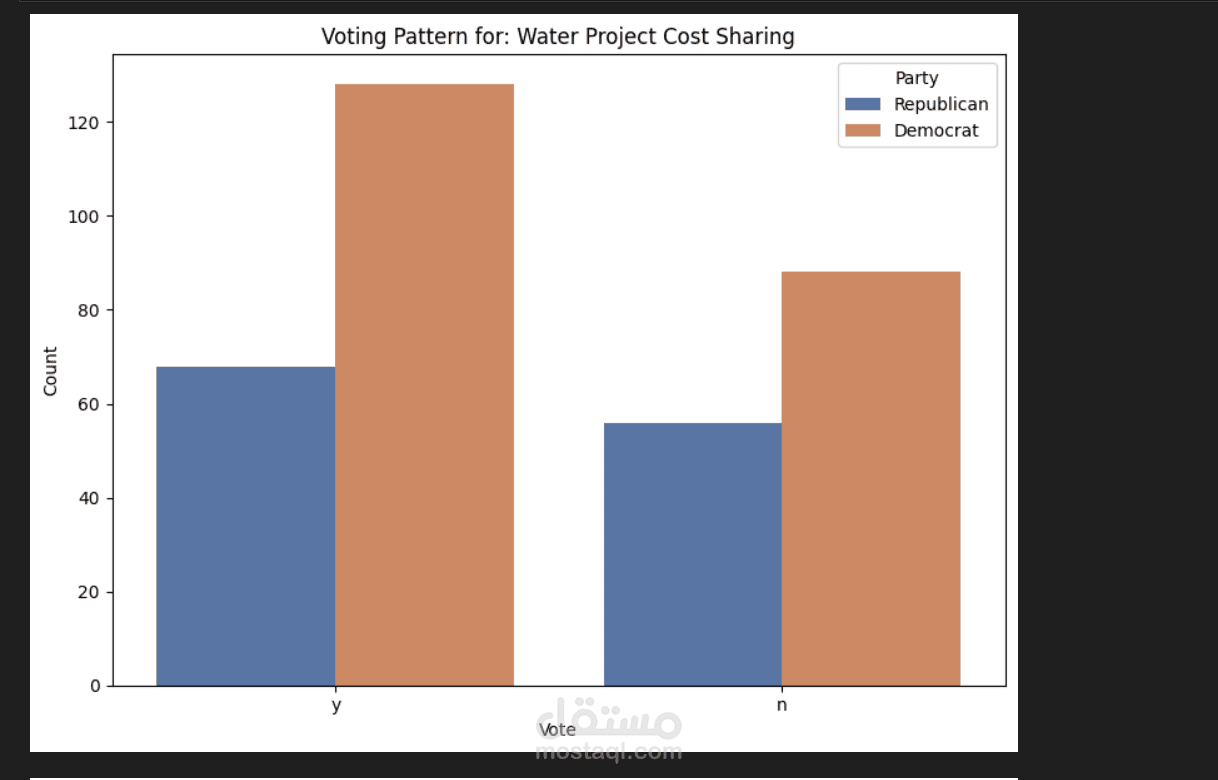
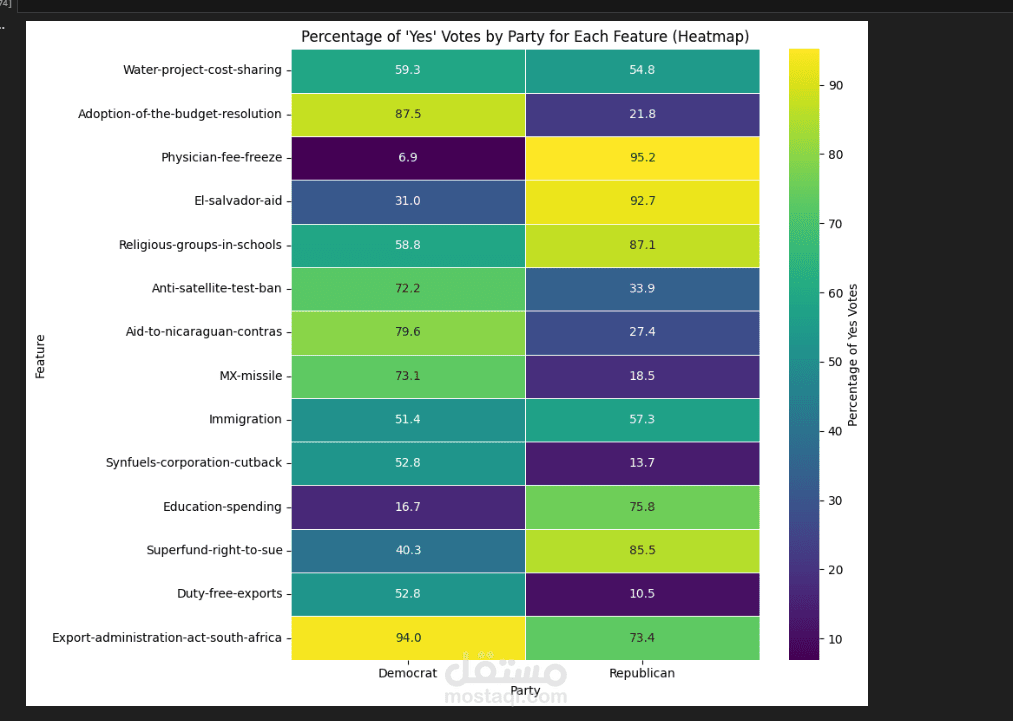
التحليل الاستكشافي (EDA): استخدام مكتبات (Seaborn & Matplotlib) لعمل رسوم بيانية توضح توزيع الأحزاب وأنماط التصويت لكل قضية.
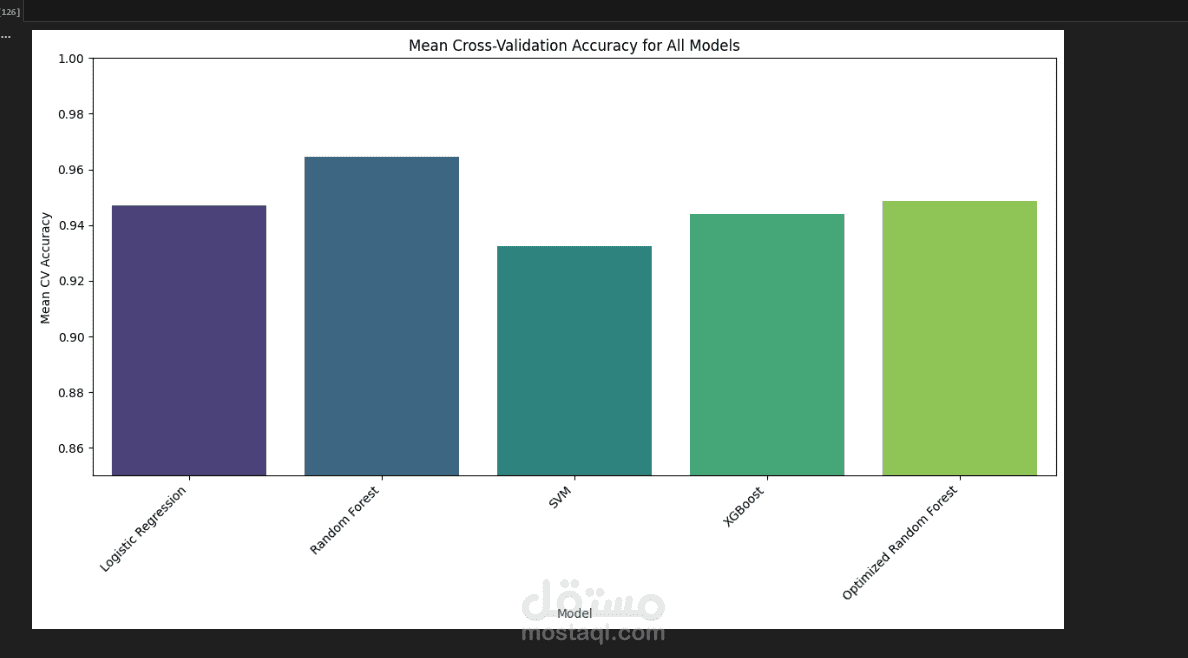
بناء النماذج: مقارنة عدة خوارزميات تصنيف مثل (Logistic Regression, Random Forest, SVM, XGBoost).
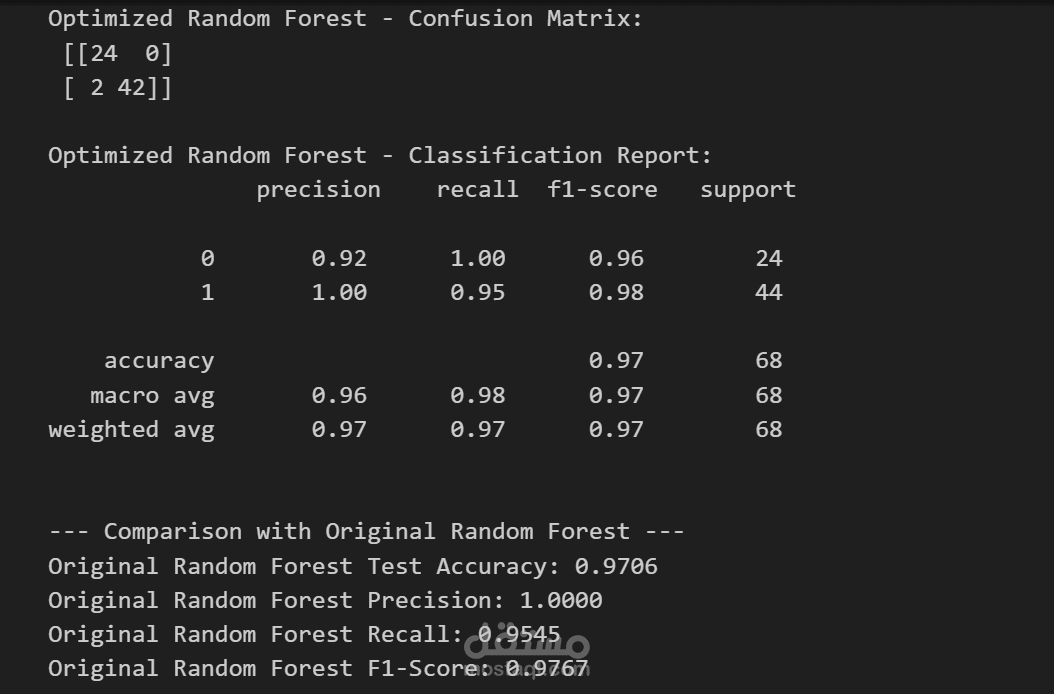
تقييم الأداء: حقق النموذج الأفضل (Random Forest) دقة عالية تصل إلى 97% في بيانات الاختبار، مع استقرار ممتاز في اختبار التحقق المتقاطع (Cross-Validation) بنسبة 96.4%.