نموذج Machine Learning للتنبؤ بالدخل
تفاصيل العمل
ذا المشروع يهدف إلى تحليل بيانات الأفراد وبناء نموذج تعلم آلي للتنبؤ بما إذا كان دخل الشخص أكبر أو أقل من 50K سنويًا اعتمادًا على مجموعة من الخصائص الديموغرافية والاقتصادية.
يتضمن المشروع عدة مراحل أساسية في عملية Data Science و Machine Learning Pipeline:
1️⃣ قراءة البيانات وتحليلها
تحميل البيانات باستخدام Pandas
استكشاف شكل البيانات وأنواع الأعمدة
فحص القيم المفقودة داخل الـ Dataset
2️⃣ تنظيف البيانات (Data Cleaning)
معالجة القيم المفقودة في الأعمدة الفئوية باستخدام أكثر قيمة تكرارًا (Mode).
فحص توزيع القيم داخل الأعمدة الفئوية.
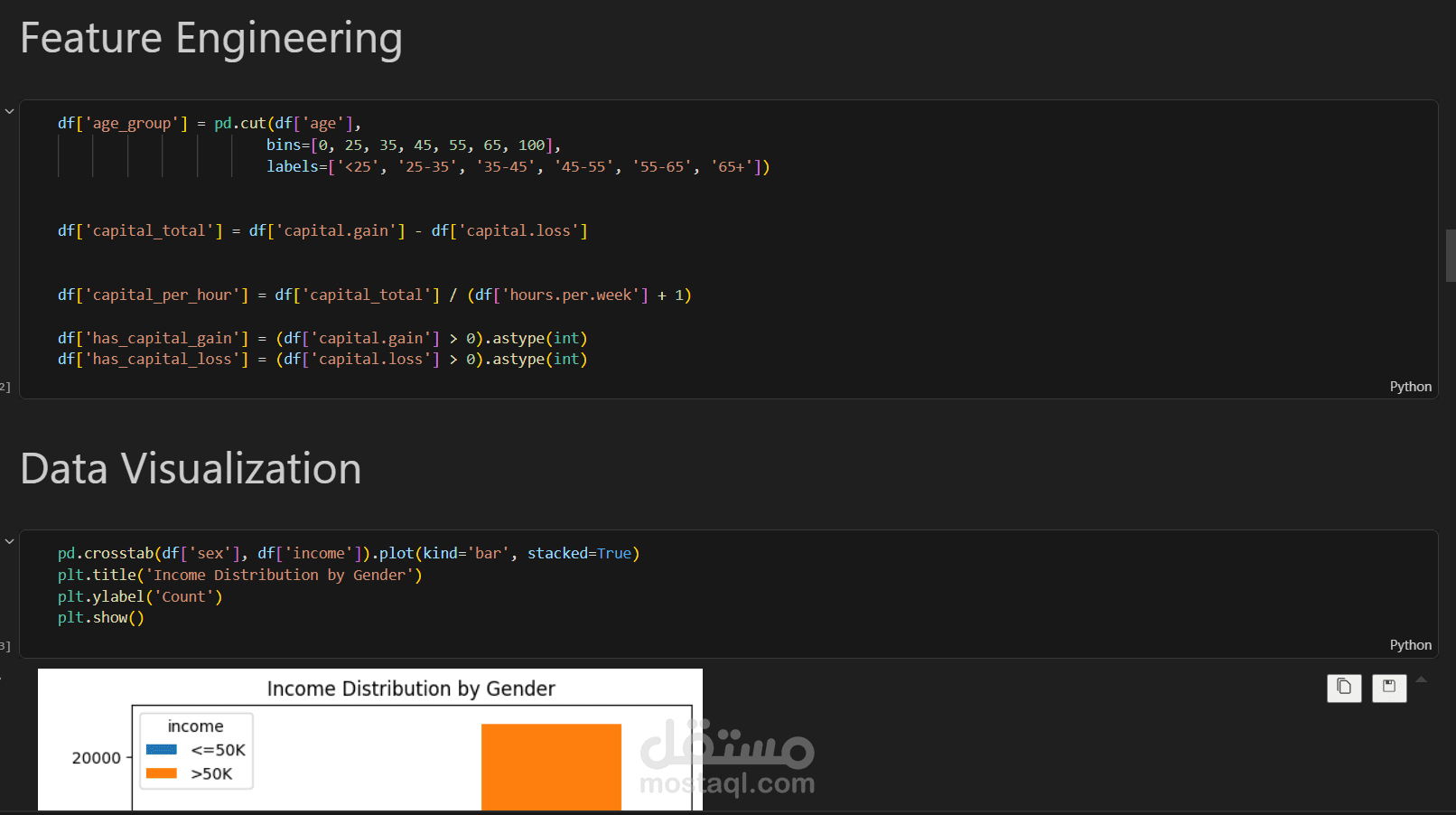
3️⃣ هندسة الخصائص (Feature Engineering)
تم إنشاء خصائص جديدة لتحسين أداء النموذج مثل:
تقسيم الأعمار إلى فئات عمرية (Age Groups)
حساب صافي رأس المال (capital gain - capital loss)
حساب رأس المال بالنسبة لساعات العمل
إنشاء متغيرات ثنائية توضح وجود أرباح أو خسائر مالية
4️⃣ تحليل البيانات بصريًا (Data Visualization)
تم إنشاء عدة رسوم بيانية لفهم العلاقات داخل البيانات مثل:
توزيع الدخل حسب الجنس
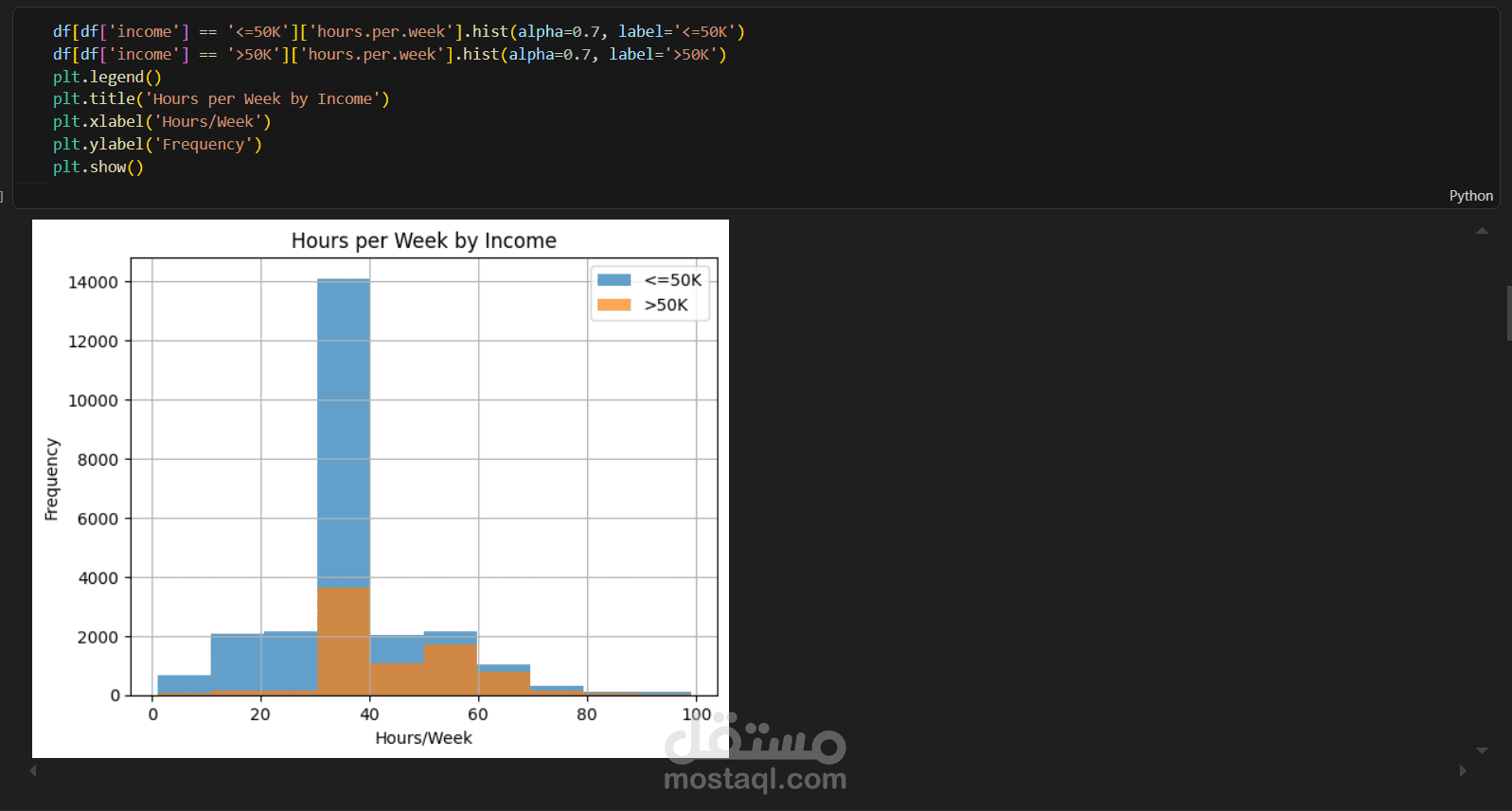
عدد ساعات العمل بالنسبة للدخل
توزيع العمر بالنسبة للدخل
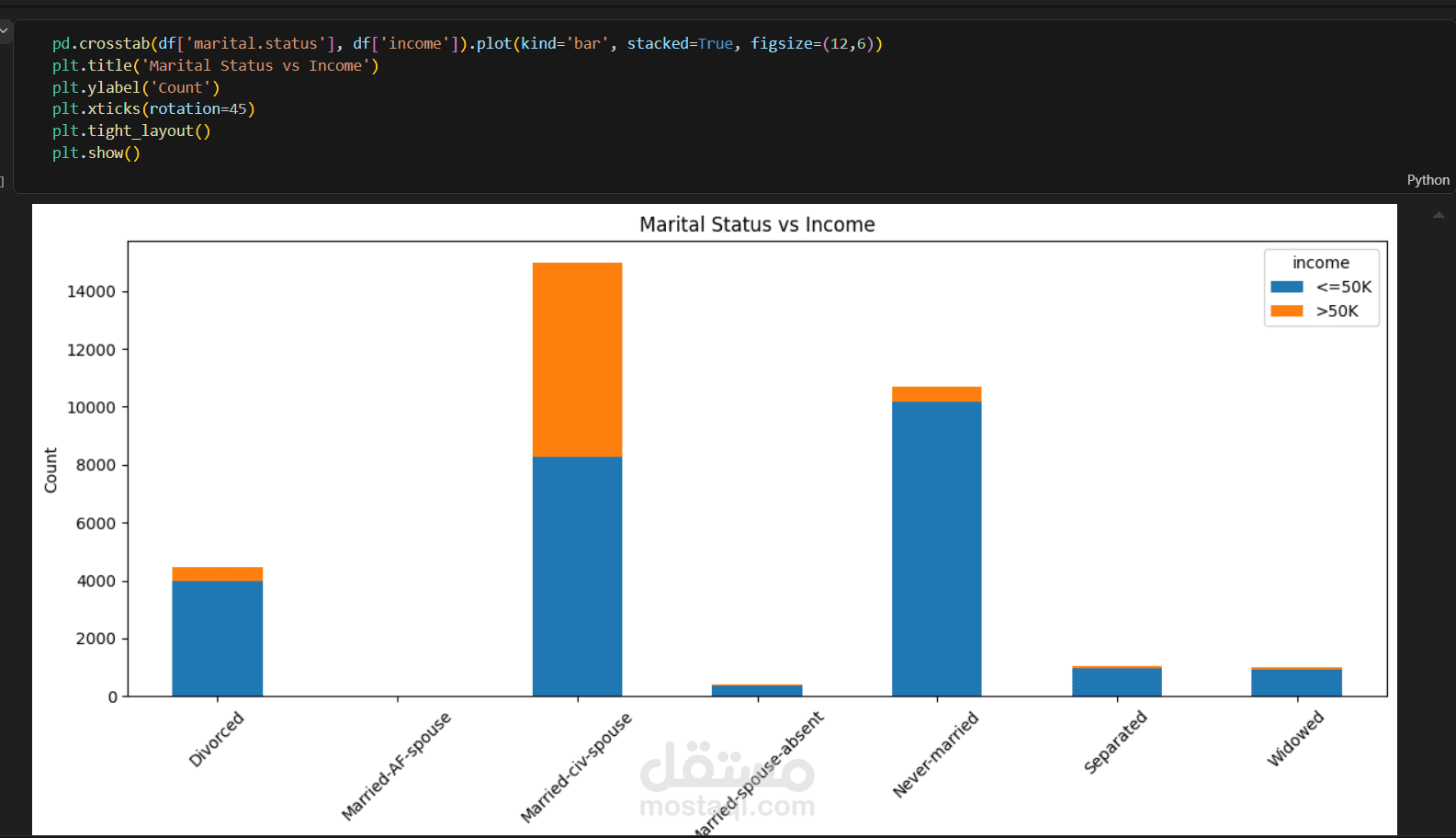
العلاقة بين الحالة الاجتماعية والدخل
تحليل التعليم الأكثر ارتباطًا بالدخل المرتفع
5️⃣ تجهيز البيانات للنموذج
تحويل المتغيرات الفئوية باستخدام One-Hot Encoding
تقسيم البيانات إلى Training و Testing sets
6️⃣ معالجة عدم توازن البيانات
استخدام خوارزمية SMOTE لزيادة العينات من الفئة الأقل تمثيلًا.
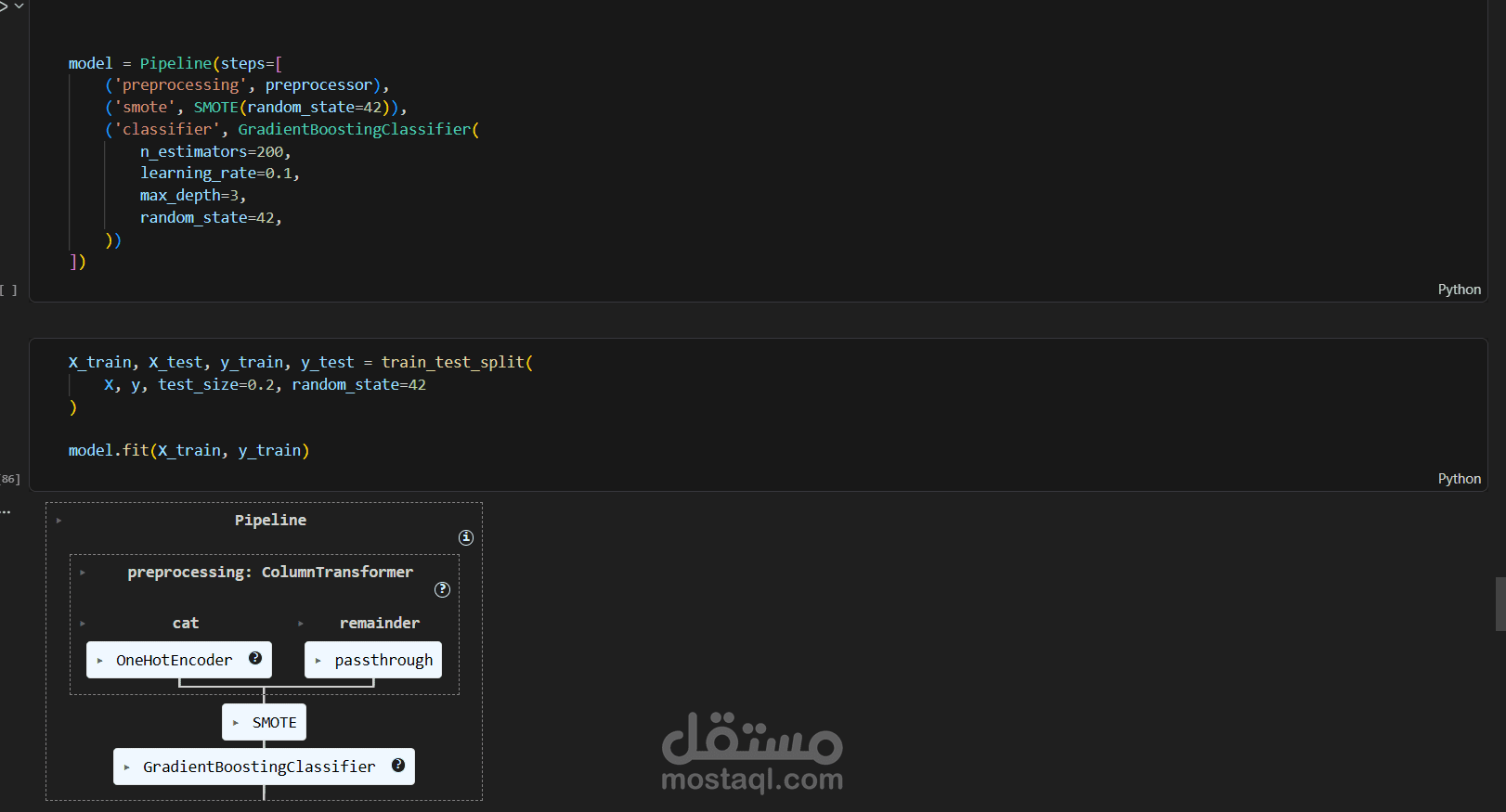
7️⃣ بناء نموذج التعلم الآلي
تم استخدام نموذج Gradient Boosting Classifier داخل Pipeline يحتوي على:
Data preprocessing
SMOTE
Model training
8️⃣ تقييم النموذج
تم تقييم أداء النموذج باستخدام عدة مقاييس:
Accuracy
Classification Report (Precision / Recall / F1-score)
Confusion Matrix
ROC Curve و AUC Score