Production-Style Batch ETL Pipeline for User Data
تفاصيل العمل


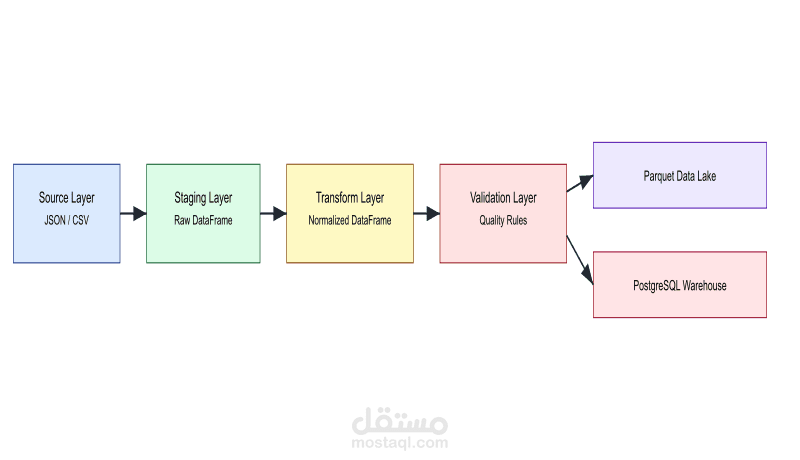
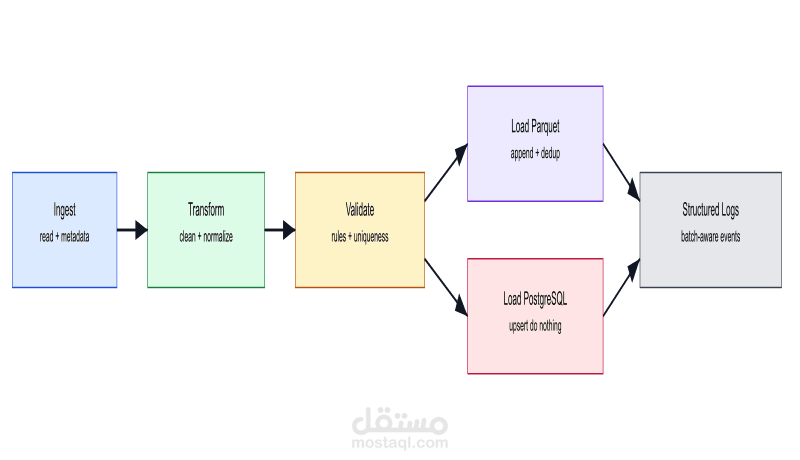

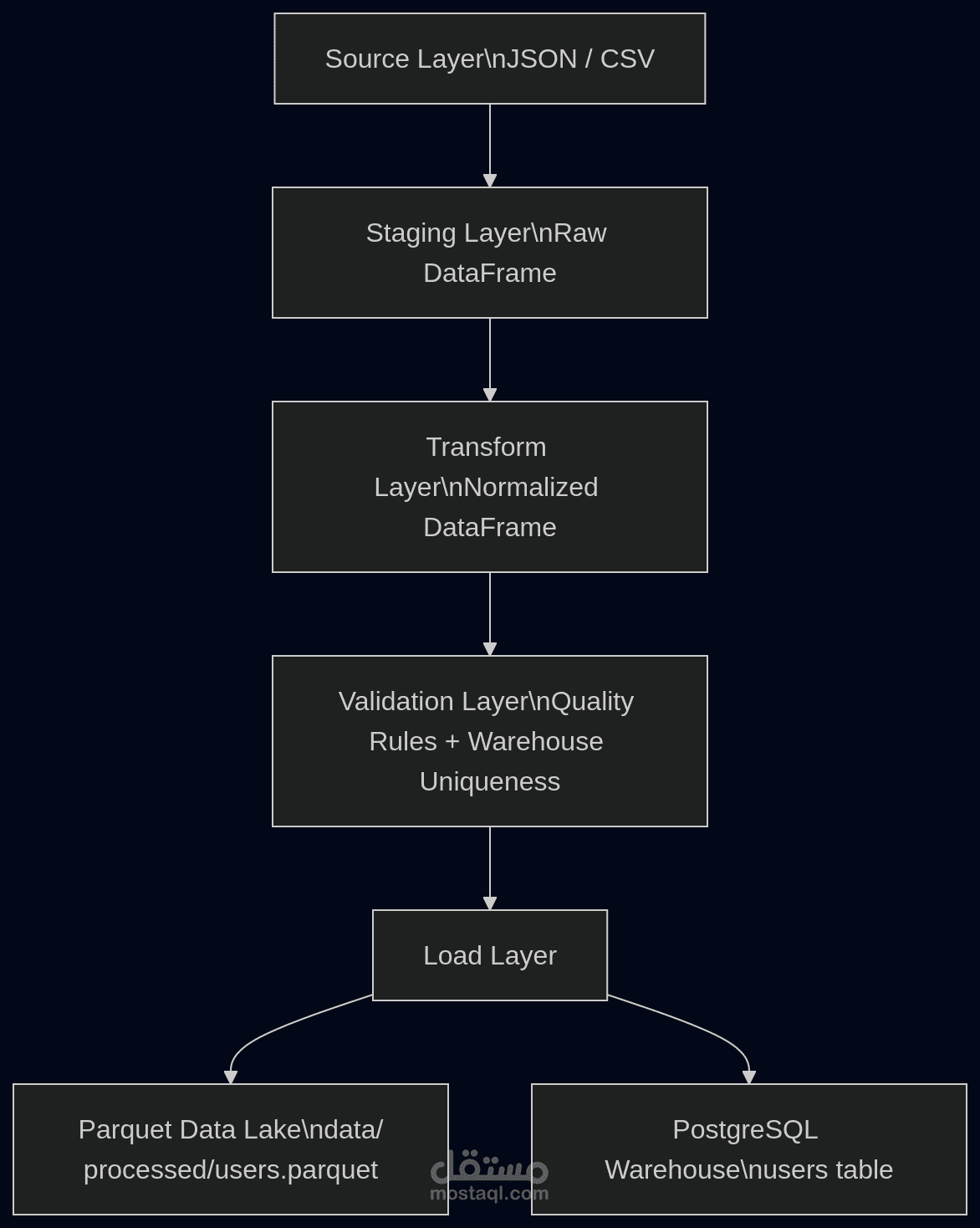

قمت بتطوير خط معالجة بيانات (ETL Pipeline) احترافي بأسلوب إنتاجي لمعالجة بيانات المستخدمين.
ميزات المشروع:
• دعم إدخال البيانات بصيغة JSON و CSV
• بنية متعددة الطبقات: Source → Staging → Transform → Validate → Load
• تطبيق قواعد تحقق صارمة لضمان جودة البيانات
• منع التكرار باستخدام Idempotent Processing
• تحميل البيانات إلى PostgreSQL
• إنشاء ملف Parquet بنمط Data Lake
• دعم Batch ID لكل عملية معالجة
• اختبارات Unit و Integration باستخدام pytest
• دعم Docker لتشغيل PostgreSQL
تم تنفيذ المشروع باستخدام Python و PostgreSQL مع تصميم معماري واضح ورسومات Mermaid توضح تدفق البيانات.