جمع البيانات
تفاصيل العمل
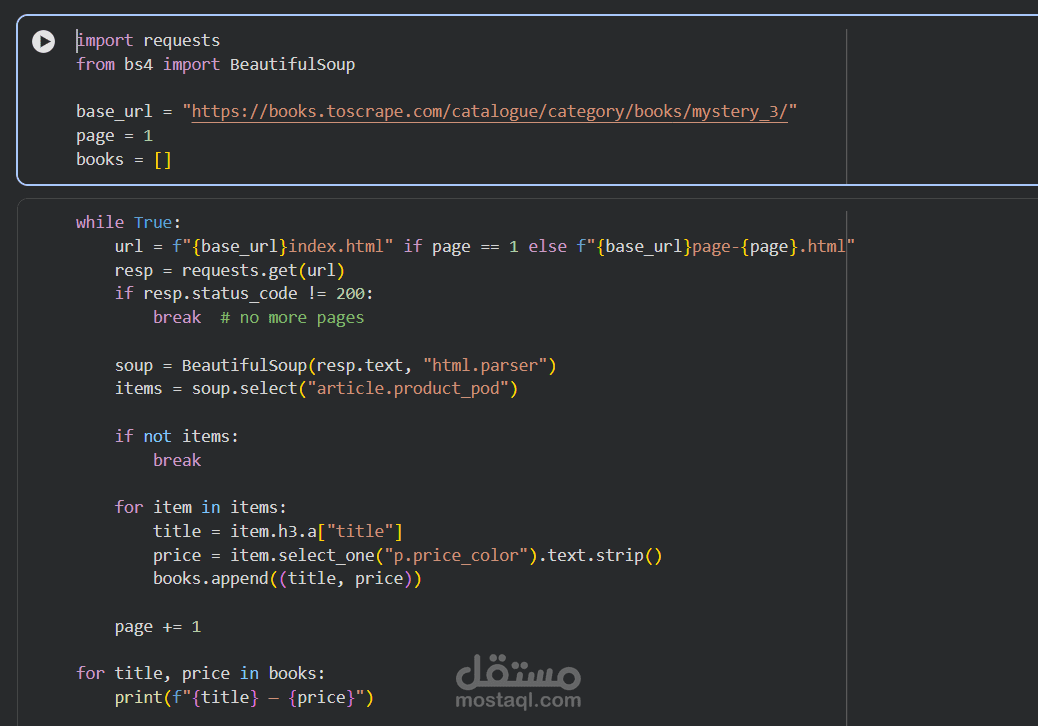
مشروع استخراج البيانات من مواقع الويب - عناوين الكتب وأسعارها
هذا المشروع عبارة عن تطبيق لاستخراج البيانات من مواقع الويب، مبني باستخدام لغة بايثون، ويستخرج عناوين الكتب وأسعارها من فئة محددة على موقع Books to Scrape.
يتنقل البرنامج تلقائيًا بين جميع صفحات الفئة المختارة، ويجمع المعلومات المطلوبة، ويخزنها في قائمة منظمة. يستخدم مكتبة requests لإرسال طلبات HTTP واسترجاع صفحات الويب، ومكتبة BeautifulSoup لتحليل محتوى HTML واستخراج البيانات اللازمة.
الميزات الرئيسية
التنقل التلقائي بين صفحات متعددة من الموقع.
استخراج عناوين الكتب وأسعارها من كل صفحة.
تحليل محتوى HTML بكفاءة باستخدام مُحدِّدات CSS.
تخزين البيانات المُجمَّعة في قائمة لمزيد من المعالجة أو التحليل.
عرض البيانات المستخرجة بتنسيق واضح.
التقنيات المستخدمة
بايثون
مكتبة Requests (لإرسال طلبات HTTP)
مكتبة BeautifulSoup (bs4) (لتحليل HTML
هدف المشروع
يهدف هذا المشروع إلى توضيح كيفية استخدام تقنيات استخراج البيانات من مواقع الويب لجمع البيانات المنظمة تلقائيًا، والتي يمكن استخدامها لاحقًا في تحليل البيانات، وتتبع الأسعار، أو بناء مجموعات البيانات.