توليد وصف تلقائي للصور
تفاصيل العمل


(Image Captioning Using Deep Learning)
يهدف هذا المشروع إلى بناء نظام ذكي قادر على توليد وصف نصي تلقائي للصور باستخدام تقنيات التعلم العميق (Deep Learning) من خلال دمج مجالين مهمين من مجالات الذكاء الاصطناعي، وهما:
الرؤية الحاسوبية (Computer Vision) لتحليل محتوى الصورة
معالجة اللغة الطبيعية (Natural Language Processing - NLP) لتوليد وصف نصي مفهوم
يعمل النظام على تحليل الصورة واستخراج الخصائص البصرية منها، ثم يستخدم هذه الخصائص لتوليد جملة تصف محتوى الصورة بشكل مشابه للوصف الذي قد يكتبه الإنسان.
تم تدريب النموذج باستخدام مجموعة بيانات Flickr30k، وهي من أشهر مجموعات البيانات المستخدمة في أبحاث Image Captioning، حيث تحتوي على آلاف الصور المرتبطة بأوصاف نصية كتبها البشر.
مجموعة البيانات (Dataset)
يعتمد المشروع على مجموعة بيانات Flickr30k والتي تحتوي على:
حوالي 31,000 صورة
لكل صورة 5 أوصاف نصية مختلفة
الصور تمثل مشاهد من الحياة اليومية مثل:
أشخاص
أنشطة
أماكن
أشياء مختلفة
وجود أكثر من وصف لكل صورة يساعد النموذج على تعلم طرق متعددة لوصف نفس المشهد.
مثال:
صورة لشخص يقود دراجة.
الأوصاف الممكنة:
رجل يقود دراجة في الشارع.
شخص يركب دراجة في الطريق.
رجل يقود دراجة في مدينة.
شخص يقود دراجة في طريق مزدحم.
رجل يقود دراجة في الهواء الطلق.
مراحل تنفيذ المشروع (Project Pipeline)
تم تنفيذ المشروع عبر مجموعة من المراحل المتتالية التي تبدأ من تحميل البيانات وتنتهي بتوليد وصف للصور.
المراحل الرئيسية هي:
تحميل البيانات
استكشاف البيانات وعرض الصور
معالجة النصوص (Preprocessing)
بناء القاموس (Vocabulary)
معالجة الصور
استخراج خصائص الصور باستخدام CNN
تحويل النصوص إلى تسلسلات رقمية
إعداد بيانات التدريب
تقسيم البيانات
بناء نموذج التعلم العميق
تدريب النموذج
تقييم النموذج
توليد وصف للصور
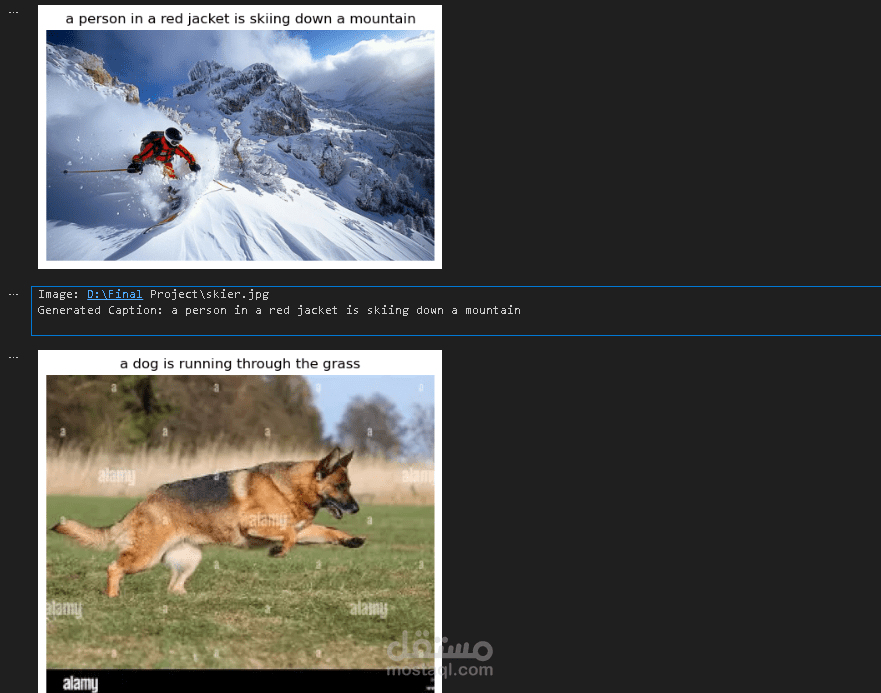
استكشاف البيانات (Data Visualization)
في بداية المشروع يتم تحميل الصور وعرض بعض الأمثلة منها مع الأوصاف المرتبطة بها باستخدام مكتبة Matplotlib.
هذه الخطوة تساعد على:
التأكد من أن البيانات تم تحميلها بشكل صحيح
فهم طبيعة الصور
الاطلاع على الأوصاف النصية المرتبطة بكل صورة
يتم عرض كل صورة مع خمسة أوصاف مختلفة مرتبطة بها.
معالجة النصوص (Caption Preprocessing)
قبل استخدام الأوصاف النصية في التدريب يجب معالجتها وتنظيفها.
تشمل عملية المعالجة:
تحويل جميع الحروف إلى حروف صغيرة
إزالة علامات الترقيم
إزالة المسافات الزائدة
تقسيم الجملة إلى كلمات (Tokenization)
إضافة رموز خاصة لبداية ونهاية الجملة
الرموز الخاصة المستخدمة:
<sos> → بداية الجملة
<eos> → نهاية الجملة
<pad> → رمز الحشو لتوحيد طول الجمل
<unk> → كلمة غير معروفة
مثال:
الجملة الأصلية:
A man riding a bicycle on the street.
بعد المعالجة:
<sos> man riding bicycle on the street <eos>
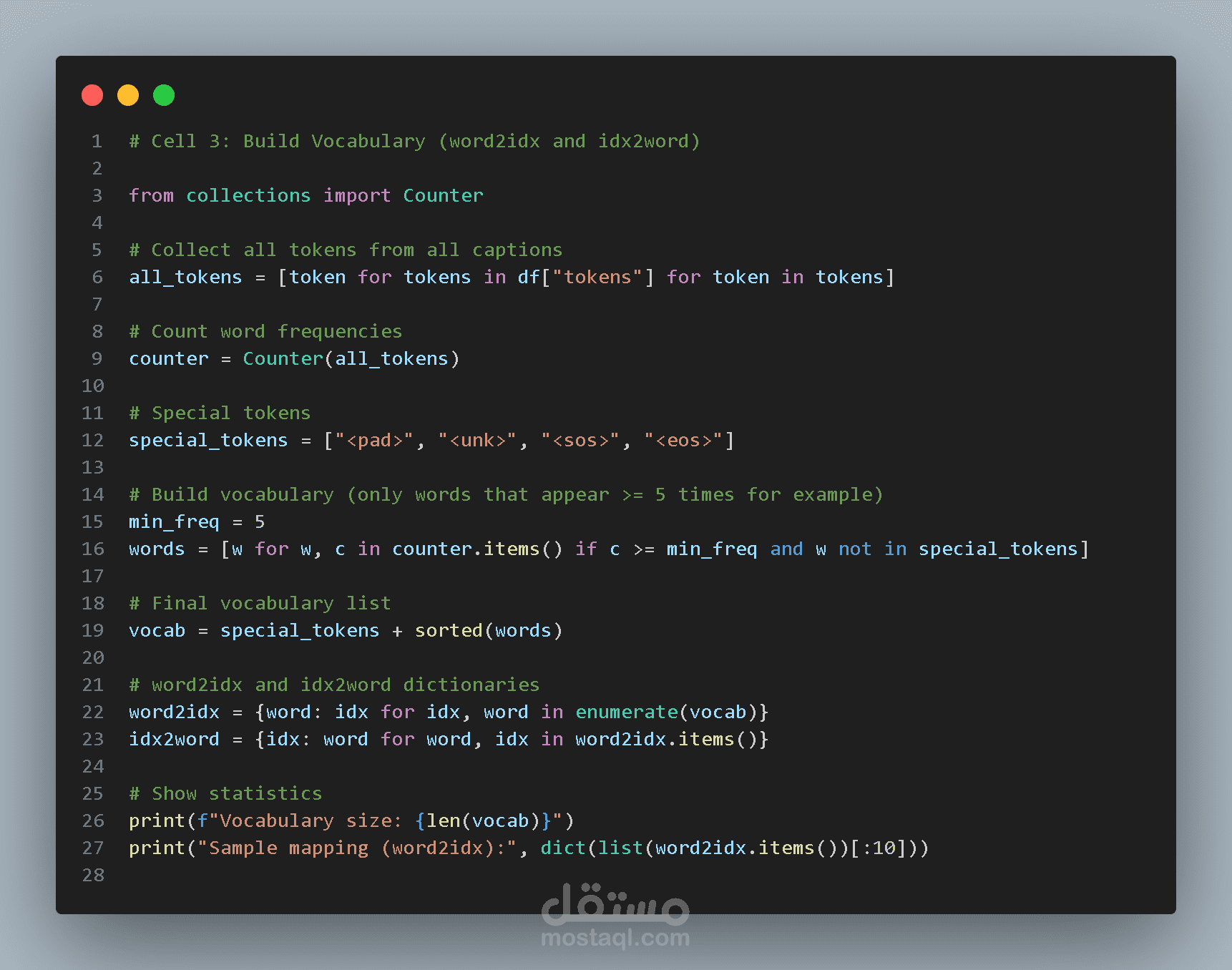
بناء القاموس (Vocabulary)
بعد معالجة النصوص يتم بناء قاموس للكلمات المستخدمة في الأوصاف.
الخطوات تشمل:
جمع جميع الكلمات من الأوصاف
حساب تكرار كل كلمة
حذف الكلمات النادرة جدًا
إنشاء قاموس يربط الكلمات بالأرقام
يتم إنشاء قاموسين:
word2idx
يقوم بتحويل الكلمات إلى أرقام.
مثال:
man → 45
bicycle → 132
street → 87
idx2word
يقوم بتحويل الأرقام مرة أخرى إلى كلمات.
هذا يسمح للنموذج بفهم النصوص على شكل أرقام وإنتاج كلمات أثناء التنبؤ.
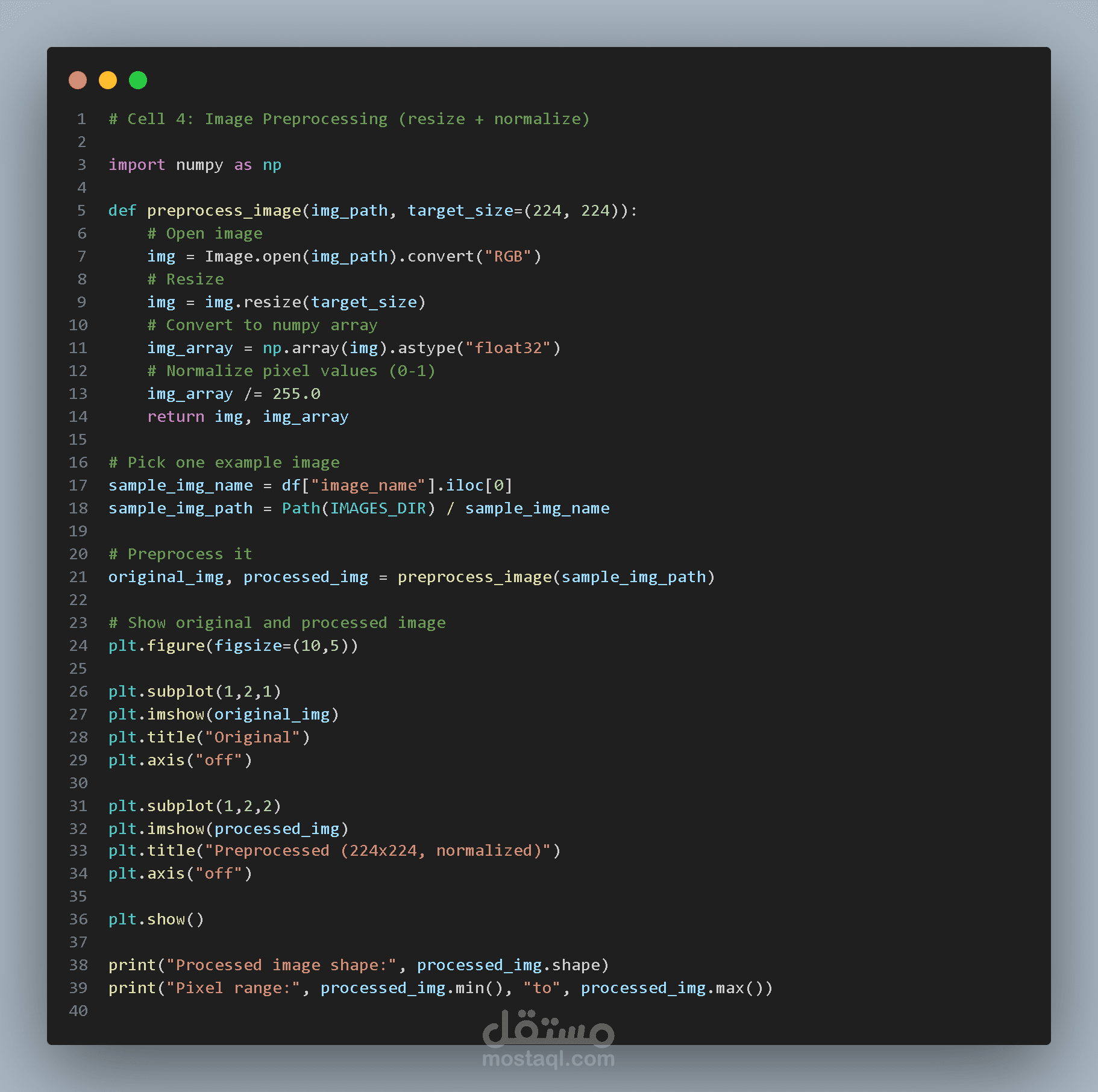
معالجة الصور (Image Preprocessing)
يتم إجراء بعض العمليات على الصور قبل استخدامها في النموذج.
تشمل هذه العمليات:
تحميل الصورة
تحويلها إلى صيغة RGB
تغيير حجم الصورة إلى
224 × 224
تحويل الصورة إلى مصفوفة أرقام
تطبيع قيم البكسل لتكون بين 0 و 1
الهدف من ذلك هو جعل جميع الصور بنفس الحجم والقيم لتسهيل تدريب النموذج.
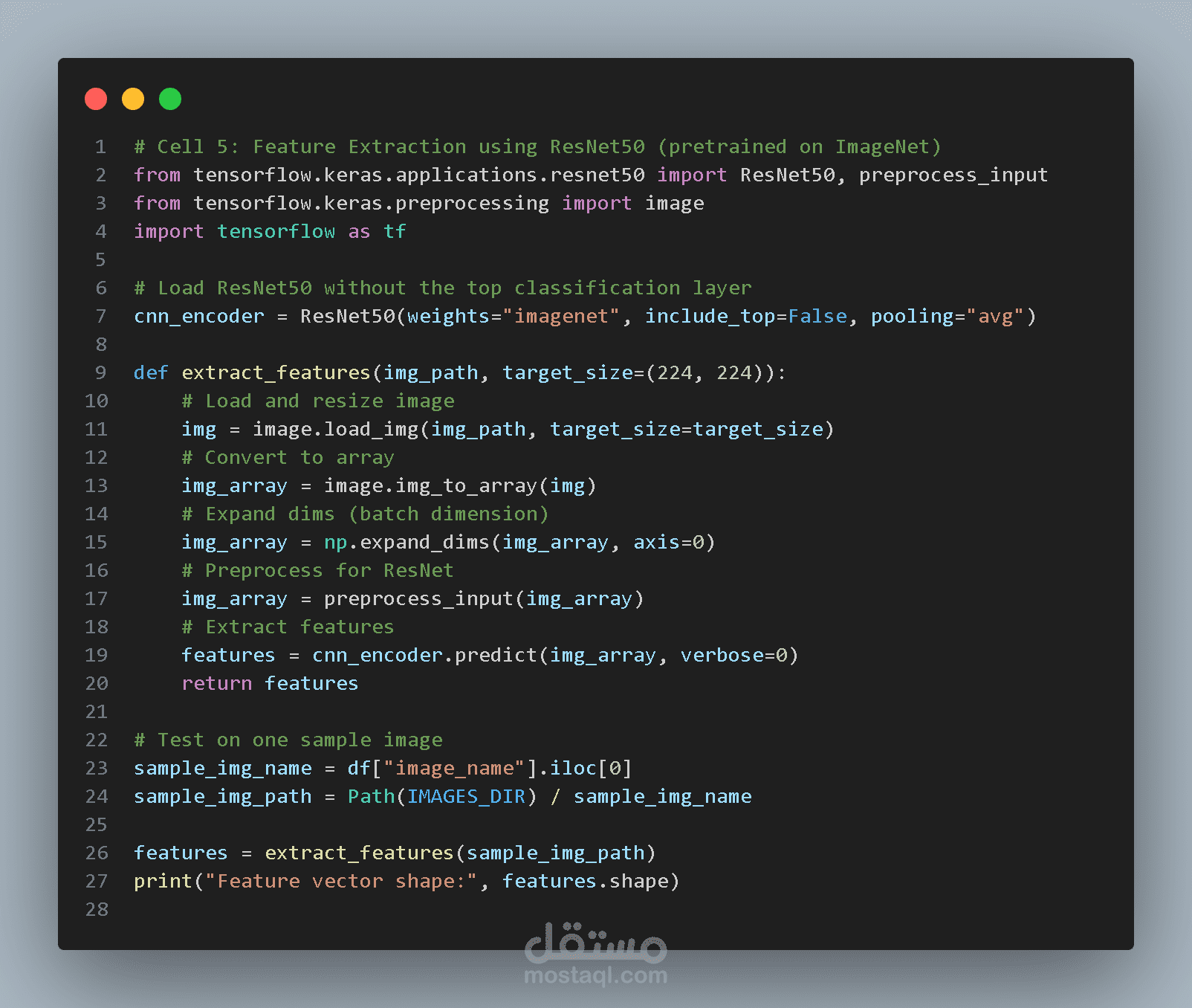
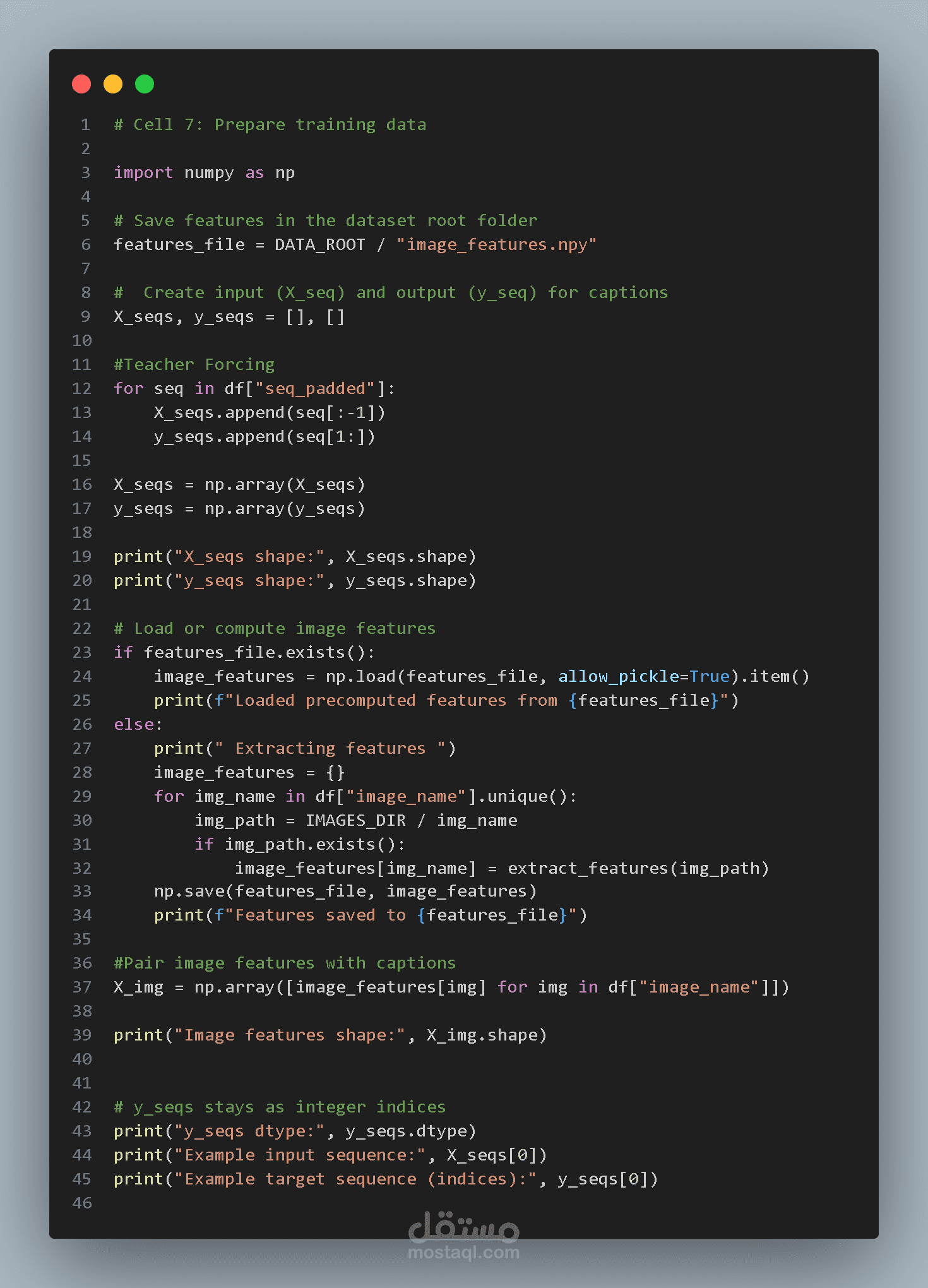
استخراج خصائص الصور (Feature Extraction)
بدلاً من تدريب شبكة CNN من البداية، يتم استخدام التعلم بالنقل (Transfer Learning) باستخدام نموذج ResNet50 المدرب مسبقًا على مجموعة بيانات ImageNet.
يتم حذف الطبقة الأخيرة الخاصة بالتصنيف واستخدام الشبكة كـ مستخرج خصائص (Feature Extractor).
لكل صورة يتم استخراج متجه خصائص بطول 2048 يمثل المعلومات البصرية المهمة مثل:
الأجسام الموجودة في الصورة
الأنماط
الأشكال
العلاقات بين العناصر
هذه الخصائص تستخدم لاحقًا لتوليد الوصف النصي.
ولتحسين الأداء يتم حفظ هذه الخصائص في ملف حتى لا يتم حسابها مرة أخرى في كل مرة.
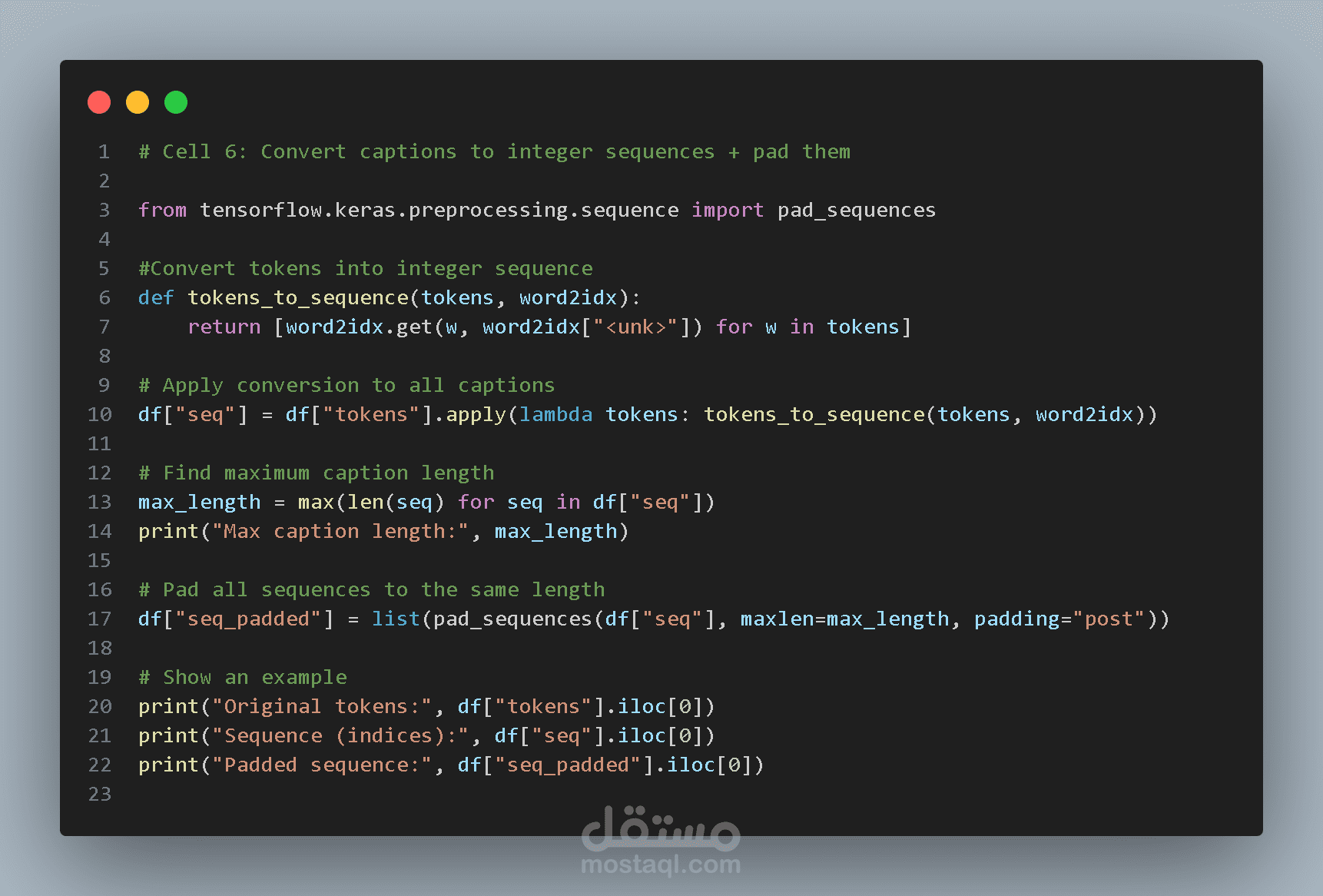
تحويل الأوصاف إلى تسلسلات رقمية
بعد بناء القاموس يتم تحويل كل وصف إلى تسلسل من الأرقام.
مثال:
الوصف:
<sos> man riding bicycle <eos>
التسلسل الرقمي:
[2, 45, 78, 132, 3]
ثم يتم توحيد طول جميع التسلسلات باستخدام رمز <pad>.
تقنية Teacher Forcing
أثناء التدريب يتم استخدام تقنية تسمى Teacher Forcing.
في هذه التقنية يتعلم النموذج التنبؤ بالكلمة التالية في الجملة.
مثال:
المدخل:
<sos> man riding bicycle
الهدف:
man riding bicycle <eos>
بهذه الطريقة يتعلم النموذج كيفية بناء الجمل كلمة بعد كلمة.
تقسيم البيانات
تم تقسيم البيانات إلى ثلاث مجموعات:
مجموعة التدريب (Training Set) → 80%
مجموعة التحقق (Validation Set) → 10%
مجموعة الاختبار (Test Set) → 10%
هذا يسمح بتقييم أداء النموذج بشكل عادل.
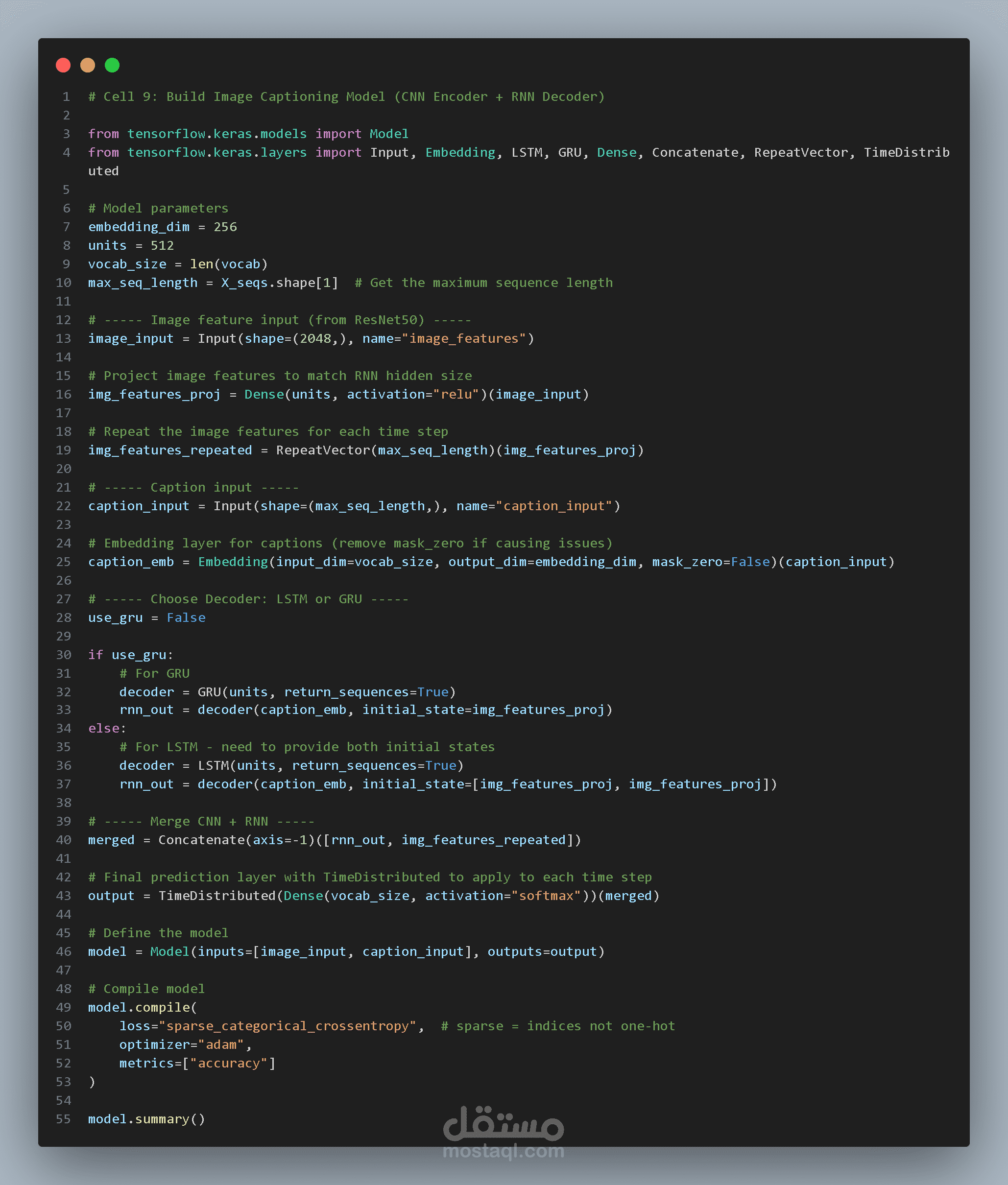
بنية النموذج (Model Architecture)
يعتمد النموذج على هيكل يجمع بين:
CNN Encoder + RNN Decoder
مشفر الصور (Image Encoder)
يتم استخدام متجه الخصائص الناتج من ResNet50 والذي يحتوي على 2048 قيمة.
ثم يتم تمريره عبر طبقة Dense لتحويله إلى تمثيل مناسب لشبكة RNN.
مفكك النصوص (Caption Decoder)
يتم استخدام شبكة RNN لتوليد الكلمات.
تقوم هذه الشبكة بتوليد الكلمات واحدة تلو الأخرى بناءً على:
الخصائص البصرية للصورة
الكلمات السابقة في الجملة
طبقة Embedding
تقوم هذه الطبقة بتحويل كل كلمة إلى متجه رقمي كثيف يسمح للنموذج بفهم العلاقات بين الكلمات.
طبقة التنبؤ
في النهاية يتم استخدام طبقة Softmax للتنبؤ بالكلمة التالية من بين جميع كلمات القاموس.
تدريب النموذج
تم تدريب النموذج باستخدام:
Loss Function: Sparse Categorical Crossentropy
Optimizer: Adam
Metrics: Accuracy
كما تم استخدام تقنيات مثل:
ModelCheckpoint لحفظ أفضل نموذج
EarlyStopping لمنع الإفراط في التدريب
حفظ سجل التدريب لتحليل الأداء لاحقًا
تقييم النموذج
تم تقييم أداء النموذج باستخدام عدة مقاييس مهمة في مجال توليد النصوص.
BLEU Score : يقيس مدى تشابه النص الناتج مع النص الحقيقي.
METEOR : يقيس التشابه الدلالي بين الجمل ويأخذ في الاعتبار:
المرادفات
ترتيب الكلمات
الجذور اللغوية
ROUGE: يقيس نسبة التداخل بين النص الناتج والنص الحقيقي.
توليد وصف للصور
بعد تدريب النموذج يمكن استخدامه لتوليد وصف لأي صورة.
تتم العملية كالتالي:
استخراج خصائص الصورة باستخدام ResNet50
بدء الجملة بالرمز <sos>
التنبؤ بالكلمة التالية
إضافة الكلمة إلى الجملة
تكرار العملية حتى ظهور <eos>
مثال على النتائج
التقنيات المستخدمة
Python
TensorFlow / Keras
NumPy
Pandas
Matplotlib
NLTK
ROUGE Score
Pillow (PIL)
تطبيقات هذا النظام
يمكن استخدام أنظمة Image Captioning في العديد من المجالات مثل:
مساعدة المكفوفين على فهم الصور
أنظمة البحث في الصور
وصف الصور في مواقع التواصل الاجتماعي
أنظمة الروبوتات
أرشفة الصور تلقائيًا