Credit Risk Prediction
تفاصيل العمل
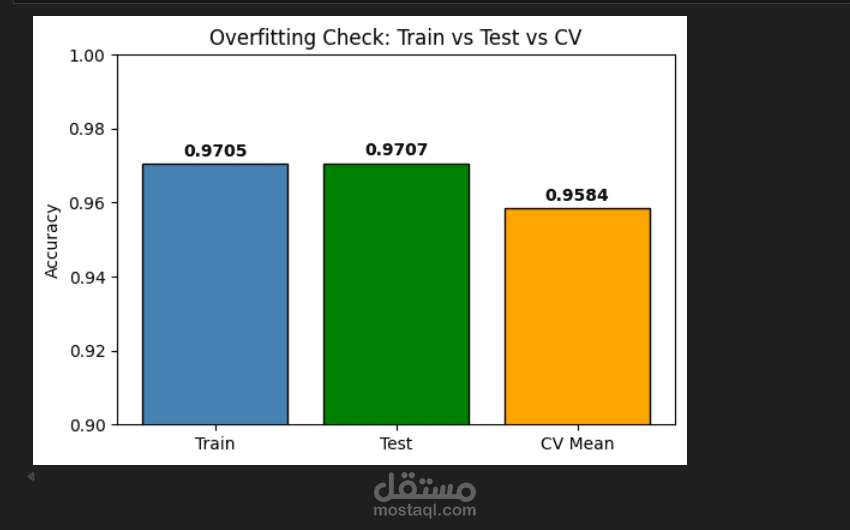
Developed an end-to-end machine learning system to predict customer credit risk using real-world financial and demographic data. The project involved data preprocessing, feature engineering, model training, and evaluation to classify customers as low or high credit risk.
The dataset consisted of over 400,000 real customer records, including personal information, income, employment history, and credit payment behavior. Extensive data cleaning was performed to handle missing values, outliers, and inconsistent records. Additional features such as customer age and credit history metrics were engineered to improve model performance.
A classification model was trained and evaluated using train-test split and cross-validation to ensure generalization and prevent overfitting. The model achieved:
Train Accuracy: 97.05%
Test Accuracy: 97.07%
Cross-Validation Accuracy: 95.84%
The close performance between training and testing results indicates strong generalization and minimal overfitting.
This system can be used in real-world financial applications such as:
Credit approval systems
Loan risk assessment
Banking risk management
Automated credit scoring systems
Technologies Used
Python
pandas for data processing
NumPy for numerical operations
scikit-learn for machine learning
Matplotlib for visualization