Heart Disease Analysis
تفاصيل العمل
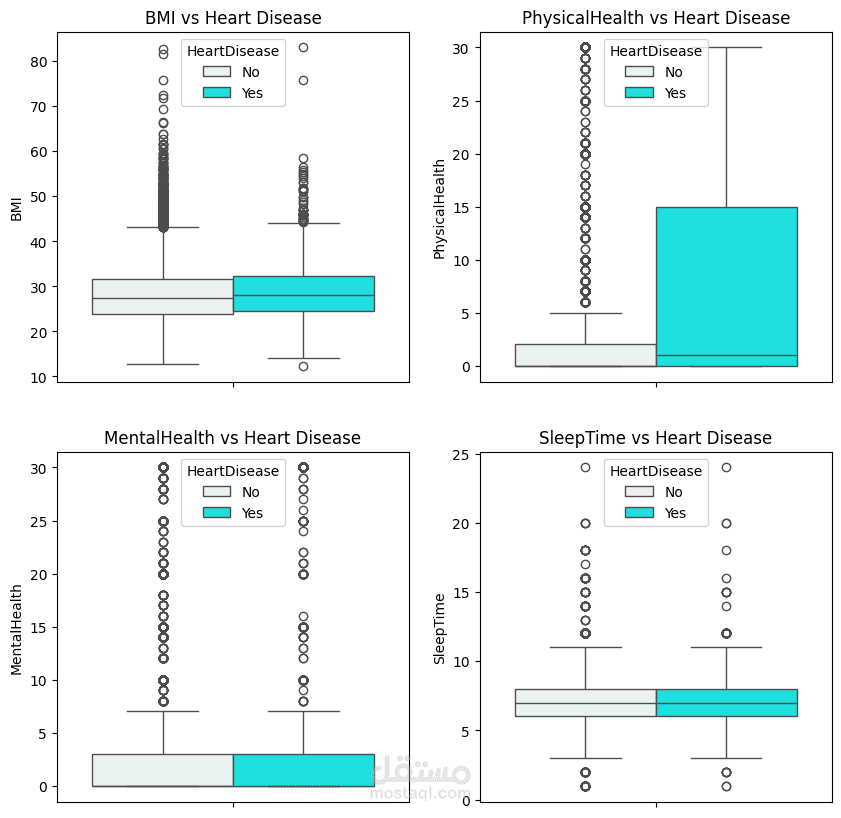
قمت بإعداد وتنفيذ خطة متكاملة لمعالجة البيانات (Data Pipeline) لمجموعة بيانات أمراض القلب، مع التركيز على الحفاظ على القيمة المعلوماتية للبيانات. شملت الخطوات ما يلي:
إدارة القيم المتطرفة (Outliers): بعد التحليل، تقرر الإبقاء على القيم المتطرفة لكونها تمثل حالات طبية واقعية وحرجة، وليست مجرد أخطاء إحصائية.
معالجة البيانات المفقودة (Target-based Imputation): اعتمدت استراتيجية مبتكرة بملء القيم المفقودة بعد تقسيم البيانات بناءً على المتغير المستهدف (Target)، لضمان واقعية البيانات المستبدلة واتساقها مع الحالة التشخيصية.
تنقية البيانات: تم استبعاد السجلات المكررة (Duplicates) لضمان دقة النتائج وعدم انحياز النموذج.
هندسة وترميز الميزات (Encoding & Selection): قمت بتطبيق (Manual Encoding) للمتغيرات الفئوية، مع تحليل مصفوفة الارتباط لتحديد الميزات الأكثر تأثيراً على النتائج (Feature Importance).
تقسيم البيانات (Stratified Splitting): نظراً لعدم توازن الفئات (Unbalanced Data)، استخدمت التقسيم الطبقي (Stratify) لضمان تمثيل عادل لكافة الحالات في مجموعتي التدريب والاختبار.
المعايرة المتينة (Robust Scaling): في الخطوة النهائية، استخدمت الـ RobustScaler لعمل Scaling للميزات، كونه الخيار الأمثل في ظل وجود القيم المتطرفة التي تم الإبقاء عليها."