Heart Disease Prediction
تفاصيل العمل
قمت بتطوير وبناء خط معالجة بيانات (Data Pipeline) متكامل، مع التركيز على حل المشكلات الإحصائية المعقدة لضمان أعلى دقة للنموذج التنبؤي. تلخصت خطوات العمل فيما يلي:
إدارة القيم المتطرفة (Outliers): من خلال تحليل التوزيع الإحصائي، اتخذت قراراً استراتيجياً بالاحتفاظ بالقيم المتطرفة؛ نظراً لكونها تمثل حالات طبية واقعية وحرجة في سياق أمراض القلب، ولا يمكن اعتبارها أخطاءً عشوائية.
معالجة البيانات المفقودة (Strategic Imputation): لضمان واقعية البيانات، قمت بتقسيم المجموعة بناءً على المتغير المستهدف (Target) قبل عملية التعبئة، مما سمح بملء القيم المفقودة بمتوسطات تتناسب مع الحالة الصحية لكل فئة، ثم أعدت دمج البيانات لضمان الاتساق.
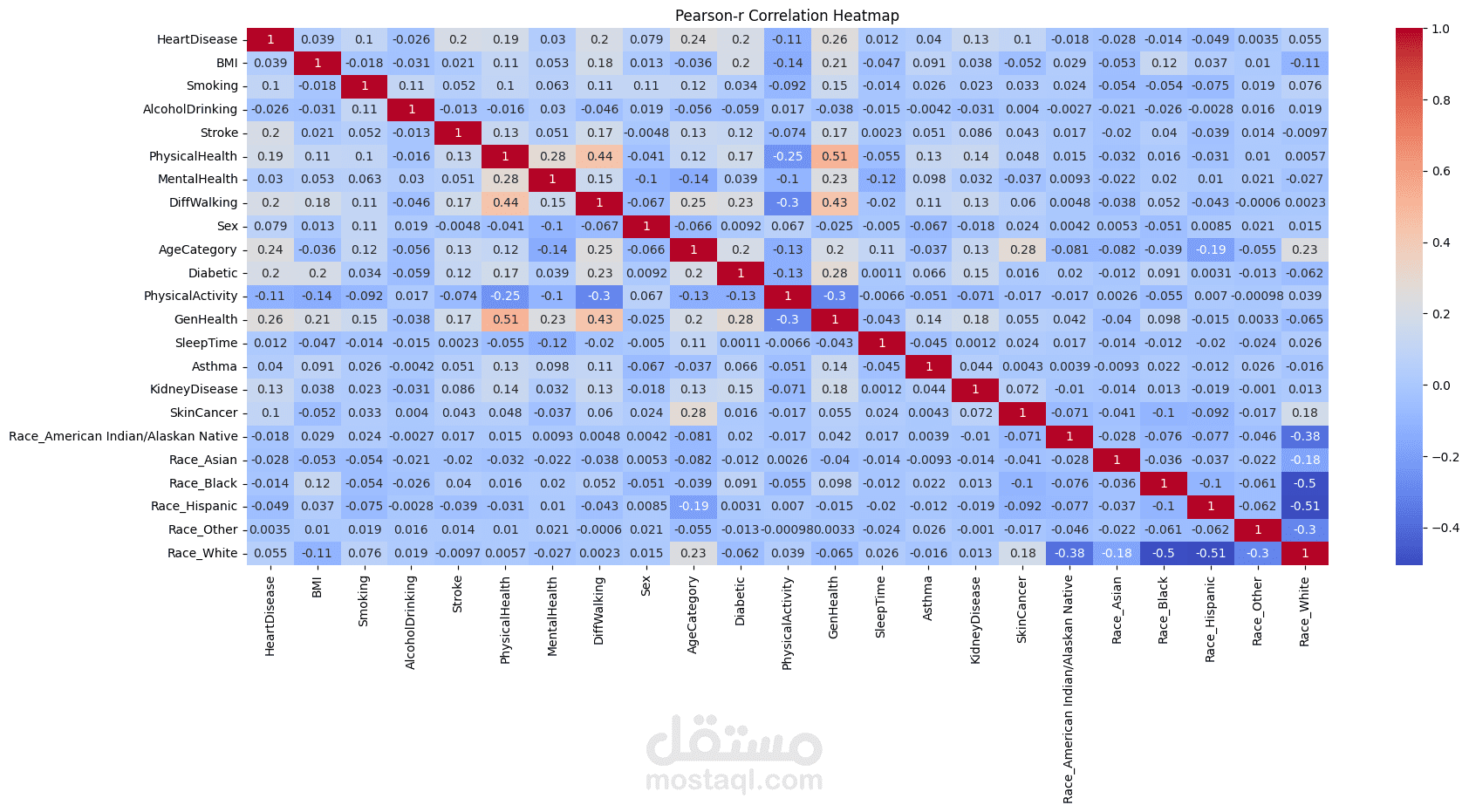
هندسة وترميز الميزات (Feature Engineering & Encoding): تم تنقية البيانات من السجلات المكررة، ثم تطبيق ترميز الفئات (Label Encoding). كما قمت بتحليل مصفوفة الارتباط (Correlation Matrix) لاستخلاص الميزات الأكثر تأثيراً (Top Features) وتحسين كفاءة النموذج.
معالجة البيانات غير المتوازنة (Handling Unbalanced Data): لضمان عدم انحياز النموذج، اعتمدت أسلوب التقسيم الطبقي (Stratified Split) عند تقسيم البيانات إلى مجموعات تدريب واختبار، لضمان تمثيل عادل لكافة الفئات في كلتا المجموعتين.
المعايرة المتينة (Robust Scaling): استخدمت تقنية Robust Scaling لمعايرة الميزات، وهي التقنية الأمثل في حالتنا كونها تعتمد على الوسيط (Median) والمدى الربيعي (IQR)، مما يجعلها مقاومة لتأثير القيم المتطرفة التي قررتُ الإبقاء عليها سابقاً.
بناء وتحسين النموذج التنبؤي (Model Building & Optimization):
البداية: اختيار Logistic Regression كنموذج أولي لبساطته وقوته الإحصائية.
التحدي: اكتشاف مشكلة انحياز البيانات (Class Imbalance) التي أدت لنتائج مضللة (فخ الدقة) وفشل في توقع الفئات الإيجابية
الحل التقني: موازنة أوزان الفئات باستخدام class_weight='balanced' لرفع قدرة الموديل على رصد الحالات القليلة والحرجة.
التقييم الاحترافي: استبدال معيار الدقة (Accuracy) بمقاييس أكثر عمقاً مثل Recall و F1-Score و Confusion Matrix لضمان موثوقية التوقعات.