تحليل استكشافي شامل لبيانات الكتب
تفاصيل العمل
في هذا المشروع، قمت بتحليل مجموعة بيانات واسعة للكتب باستخدام لغة Python، بهدف فهم العوامل التي تجعل الكتاب ناجحاً أو عالي التقييم. ركز المشروع على تنظيف البيانات وتصورها لاستخراج رؤى حول المؤلفين الأكثر تأثيراً، وتوزيع التقييمات، والعلاقة بين عدد الصفحات وشعبية الكتاب.
أبرز المهام التقنية التي قمت بها في الكود:
تنظيف البيانات (Data Wrangling): * معالجة القيم المفقودة في أسماء المؤلفين وتواريخ النشر.
تنظيف عمود التقييمات وتحويله إلى قيم عددية صالحة للتحليل الإحصائي.
تحليل التقييمات (Ratings Distribution): * دراسة توزيع تقييمات المستخدمين (Average Ratings) واكتشاف أن أغلب الكتب تتركز في نطاق تقييم معين.
تحليل المؤلفين والناشرين:
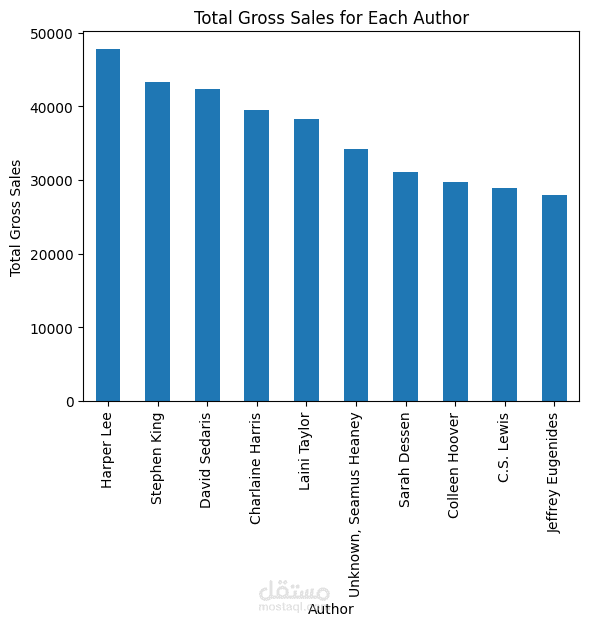
تحديد أكثر 10 مؤلفين إنتاجاً للكتب وأكثرهم حصولاً على أعلى متوسط تقييمات.
رصد دور النشر الأكثر سيطرة على السوق بناءً على عدد الإصدارات.
تحليل العلاقات (Correlation Analysis):
دراسة العلاقة بين "عدد صفحات الكتاب" و"التقييم" (هل الكتب الطويلة تحصل على تقييمات أعلى؟).
تحليل الارتباط بين عدد المراجعات (Review Count) وشعبية الكتاب.
التصور البياني (Data Visualization):
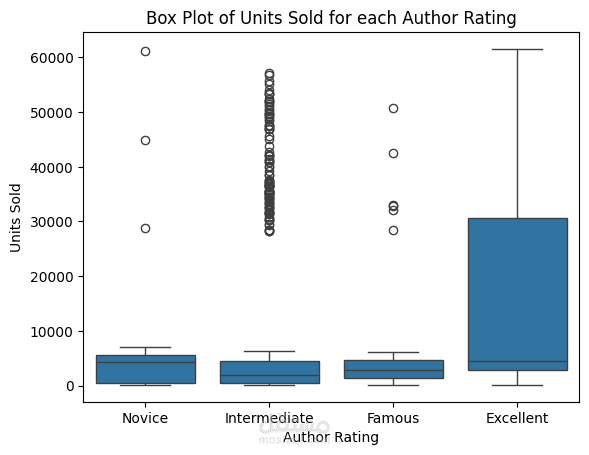
استخدام Seaborn و Matplotlib لإنشاء رسوم بيانية جذابة (Histograms, Bar Charts, Scatter Plots) توضح توزيع البيانات بشكل مبسط.
النتائج الرئيسية للمشروع:
قائمة بأفضل 10 كتب بناءً على خوارزمية تجمع بين "عدد التقييمات" و "متوسط التقييم".
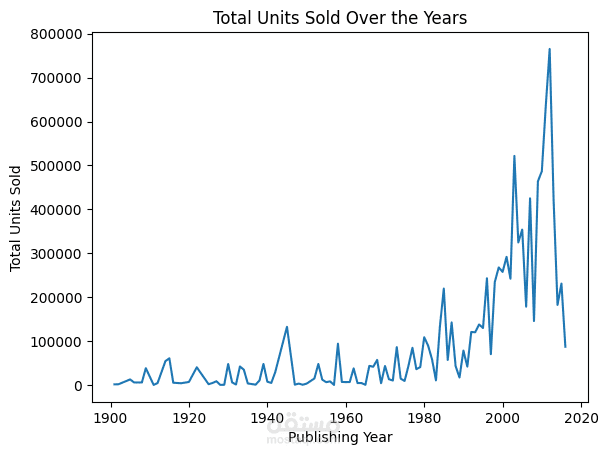
اكتشاف اتجاهات النشر عبر السنوات وتحديد "العصر الذهبي" لإنتاج الكتب في قاعدة البيانات.
تحديد اللغات الأكثر انتشاراً في الكتب المحللة.
الأدوات والمكتبات المستخدمة:
اللغة: Python.
المكتبات: Pandas, NumPy, Seaborn, Matplotlib.
البيئة: Kaggle / Jupyter Notebook.