تطبيق ذكاء اصطناعي لكشف العناصر وتحديدها باستخدام Gemini API و Python
تفاصيل العمل
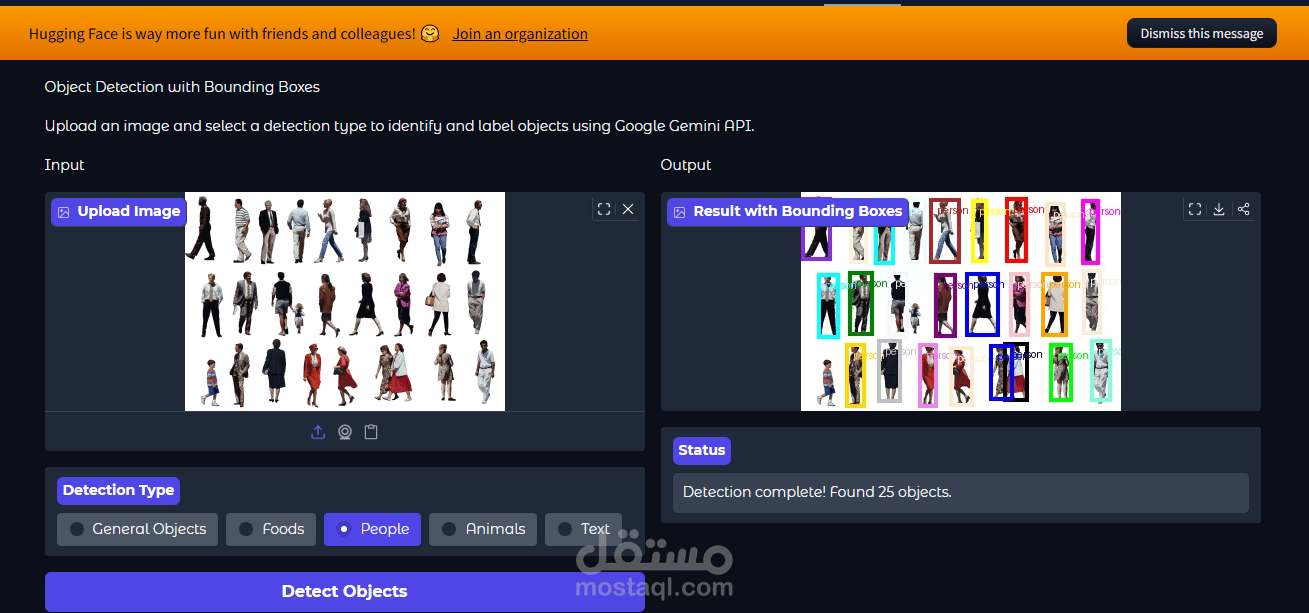
مشروع متقدم يعتمد على الرؤية الحاسوبية (Computer Vision) والذكاء الاصطناعي التوليدي، حيث يقوم التطبيق بتحليل الصور وتحديد العناصر الموجودة بها بدقة عالية، مع رسم صناديق تحديد (Bounding Boxes) وتصنيفها برمجياً.
المميزات التقنية التي قمت بتنفيذها في الكود:
دمج نماذج Gemini AI: استخدام نموذج gemini-1.5-flash لمعالجة الصور واستخراج الإحداثيات (Normalized Coordinates) بدقة متناهية.
تعدد التصنيفات (Multi-Category Detection): يدعم النظام التعرف على فئات متنوعة تشمل (الأشخاص، الأطعمة، الحيوانات، النصوص، والعناصر العامة).
المعالجة البرمجية للصور:
تطوير وحدة لمعالجة الصور باستخدام مكتبة PIL لضمان توافق الأحجام وسرعة الاستجابة.
رسم صناديق التحديد (Bounding Boxes) وتسميتها بألوان مختلفة ديناميكياً لسهولة القراءة.
تحليل البيانات (JSON Parsing): التعامل مع مخرجات النموذج بصيغة JSON وتحويلها إلى بيانات مرئية على الصورة.
واجهة مستخدم تفاعلية: بناء واجهة كاملة باستخدام Gradio تتيح للمستخدم رفع الصور واختيار نوع الكشف والحصول على النتائج فوراً.
التعامل مع البيئة (Environment Management): استخدام نظام dotenv لحماية مفاتيح API وضمان أمان التطبيق.
الأدوات والتقنيات المستخدمة:
اللغة: Python
الذكاء الاصطناعي: Google Generative AI (Gemini SDK)
واجهة المستخدم: Gradio