تطوير بعض موديلا تعلم الاله
تفاصيل العمل
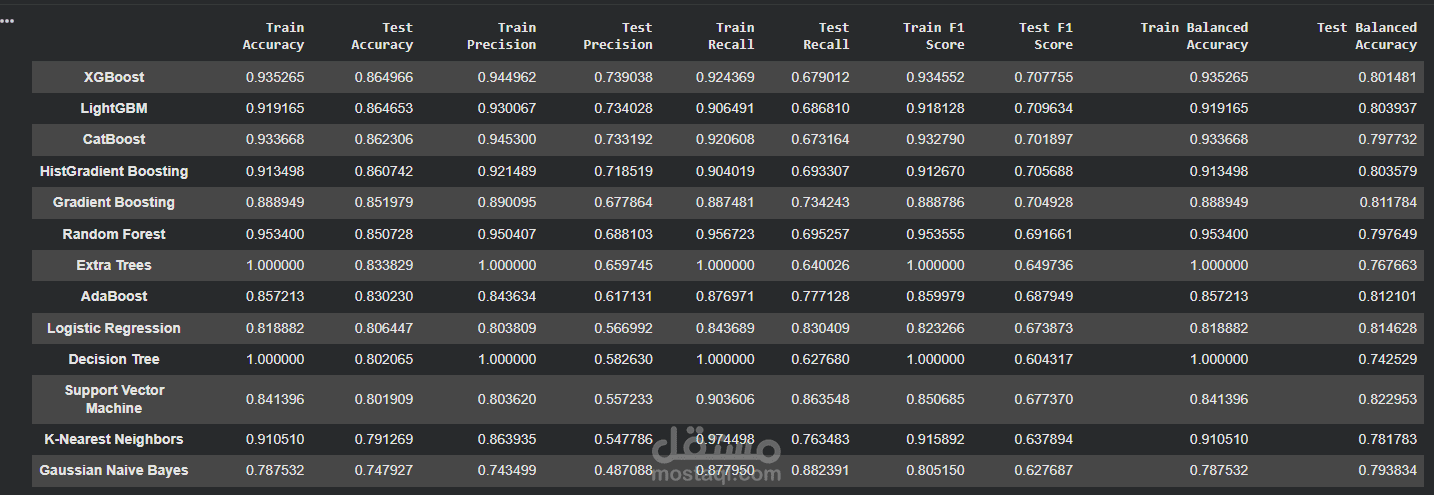
يتناول هذا المشروع تنفيذ وتحليل مقارن شامل لمجموعة متنوعة من خوارزميات تعلم الآلة بهدف تحديد النموذج الأكثر كفاءة وقدرة على التعميم على بيانات جديدة. تم تدريب وتقييم عدة نماذج مثل XGBoost، LightGBM، CatBoost، Random Forest، Gradient Boosting، Extra Trees، Decision Tree، Logistic Regression، Support Vector Machine، K-Nearest Neighbors، وGaussian Naive Bayes باستخدام مجموعة من مقاييس الأداء الأساسية، وهي Accuracy وPrecision وRecall وF1-Score بالإضافة إلى Balanced Accuracy لضمان تقييم عادل خاصة في حالة عدم توازن البيانات.
أظهرت النتائج أن بعض النماذج مثل Decision Tree وExtra Trees حققت دقة عالية جدًا على بيانات التدريب وصلت إلى 100%، إلا أن أداءها انخفض على بيانات الاختبار، مما يشير إلى احتمالية حدوث Overfitting. في المقابل، قدمت نماذج الـ Boosting مثل XGBoost وLightGBM وCatBoost أداءً أكثر استقرارًا وتوازنًا بين بيانات التدريب والاختبار، مما يعكس قدرة أفضل على التعميم. تم اختيار النموذج النهائي بناءً على أفضل توازن بين دقة الاختبار، استقرار Precision وRecall، أعلى F1-Score، وأقل فجوة بين نتائج التدريب والاختبار، مما يعكس نهجًا احترافيًا في تحليل الأداء واختيار النموذج الأمثل بناءً على البيانات وليس فقط على أعلى دقة ظاهرية.