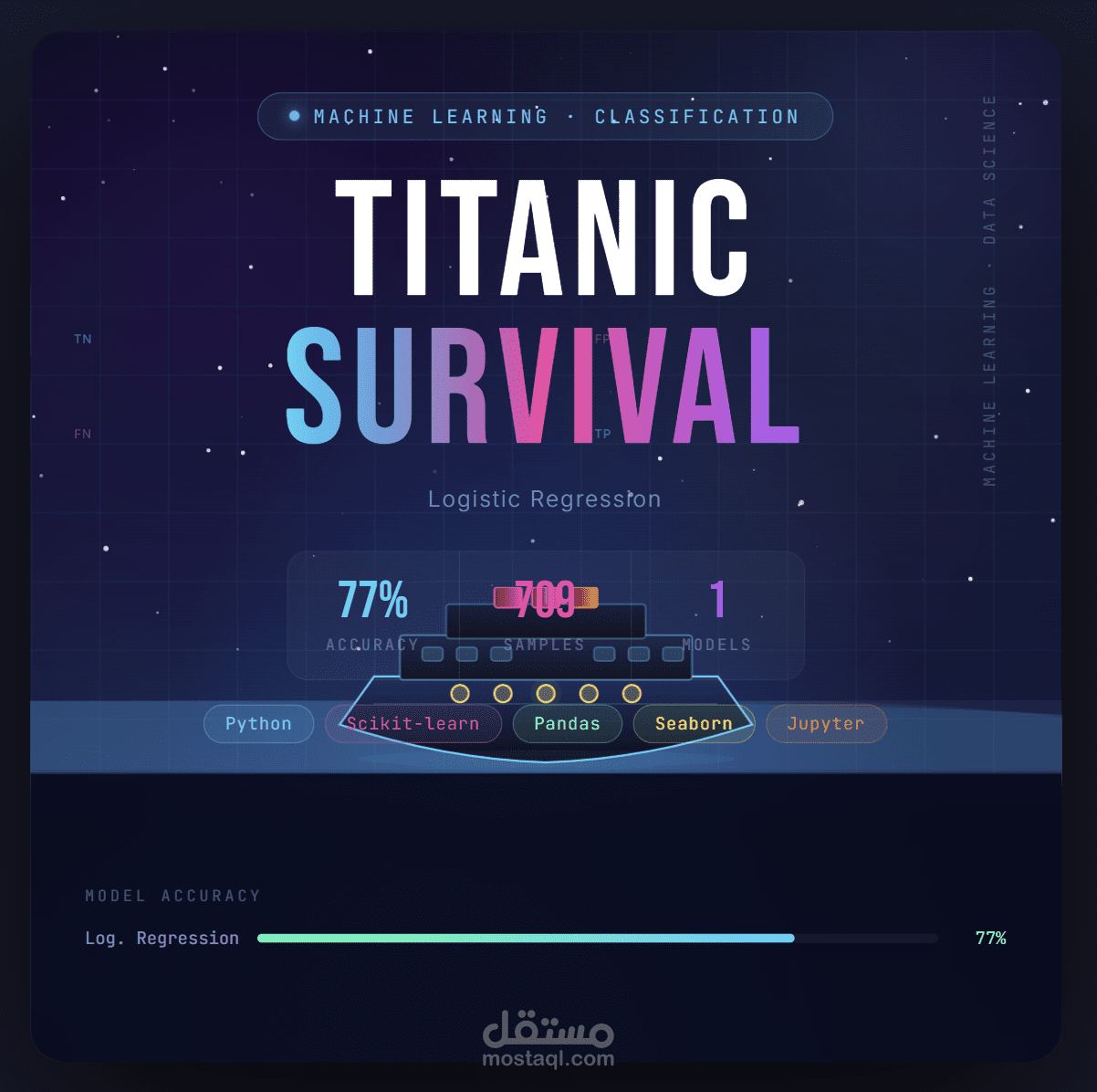
Titanic classification
تفاصيل العمل


اشتغلت على titanic dataset واول حاجه نظفت الداتا من ال missing values , حذفت ال duplicates الاسطر المتكرره (rows) وحذفت ال outliers من الداتا لانها بتاثر على الداتا.
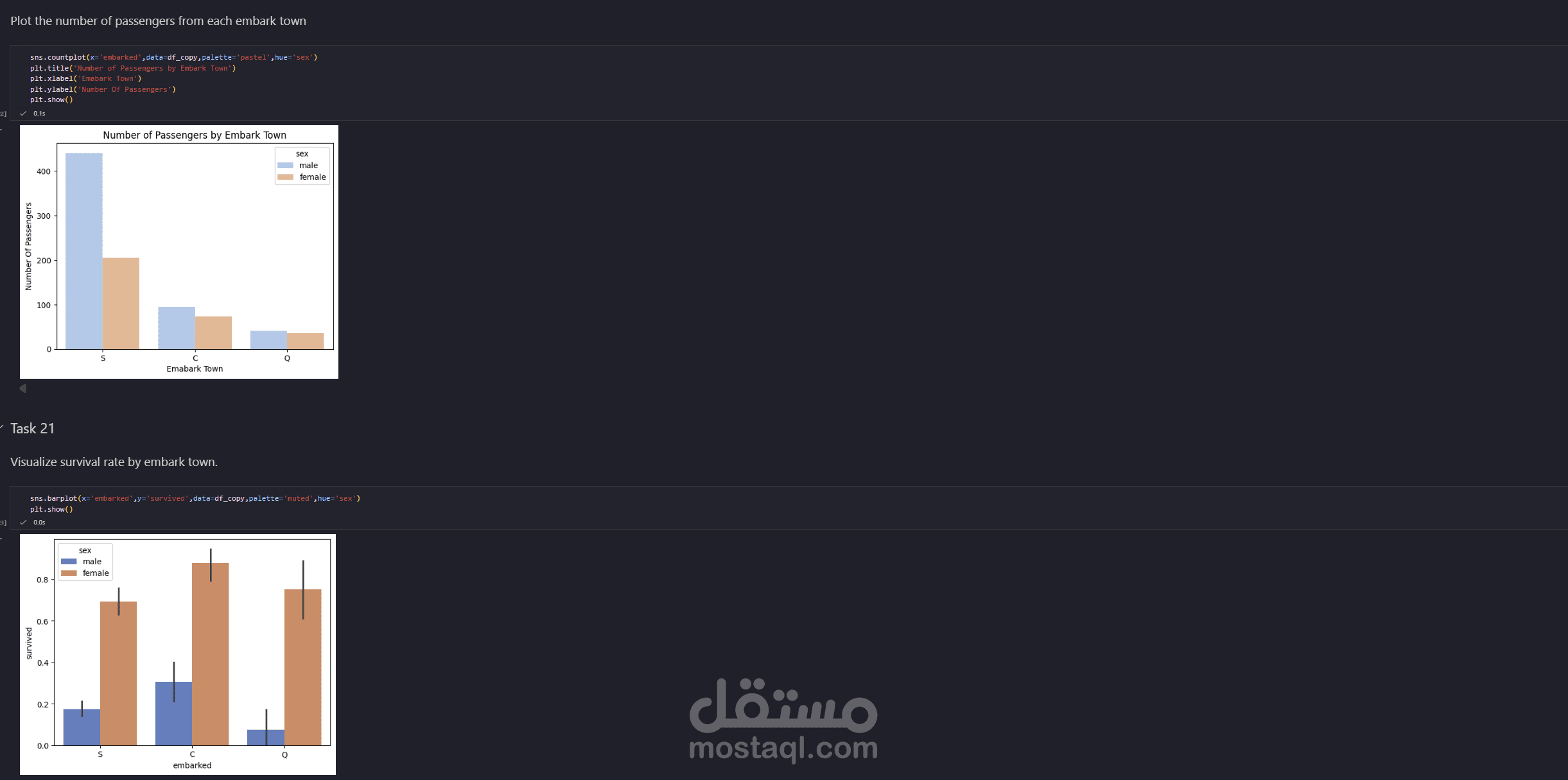
عملت visualization باستخدام ال matplotlib and seaborn
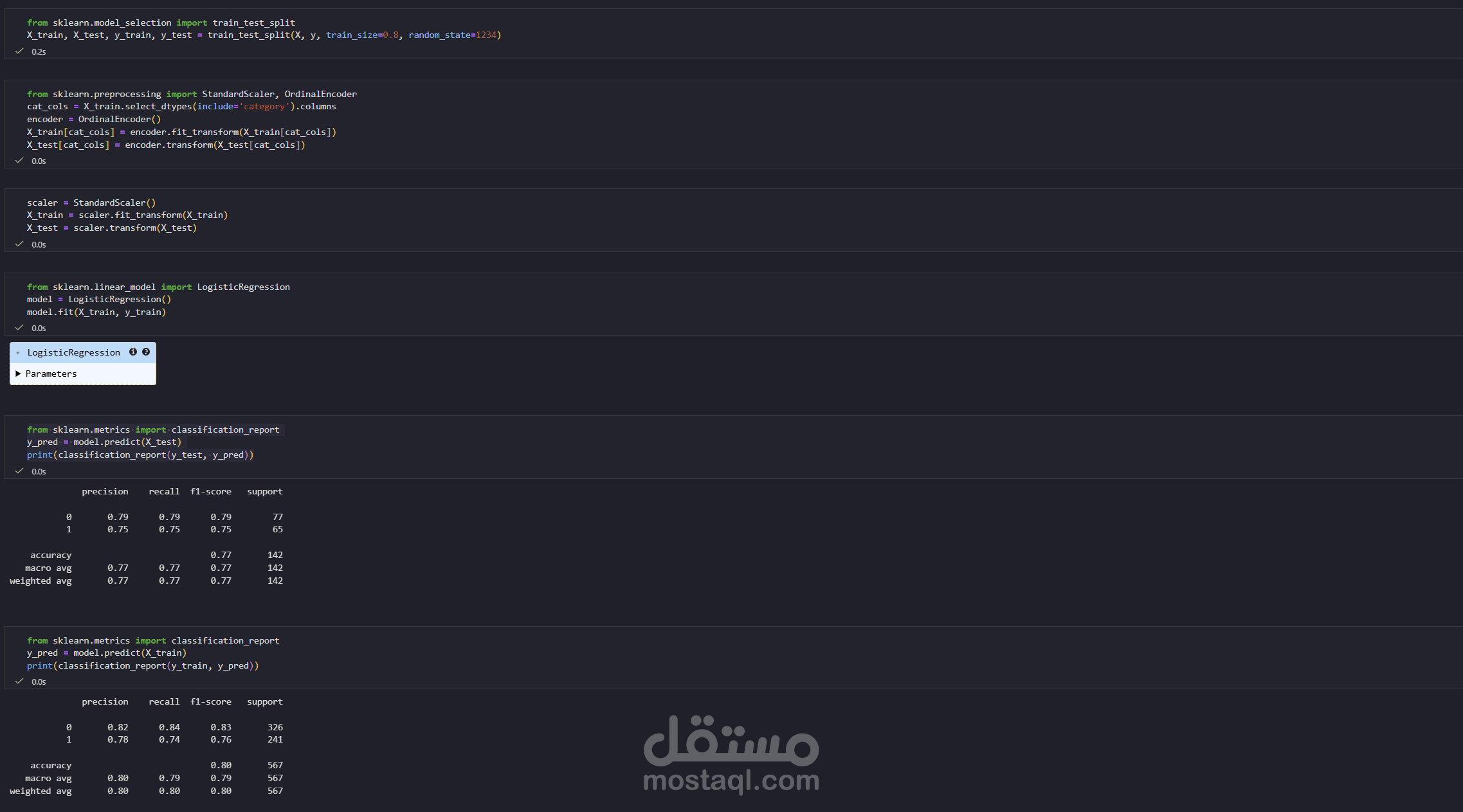
وبعدين دربت ال model على ال data ال classification model باستخدام مكتبه scikit learn
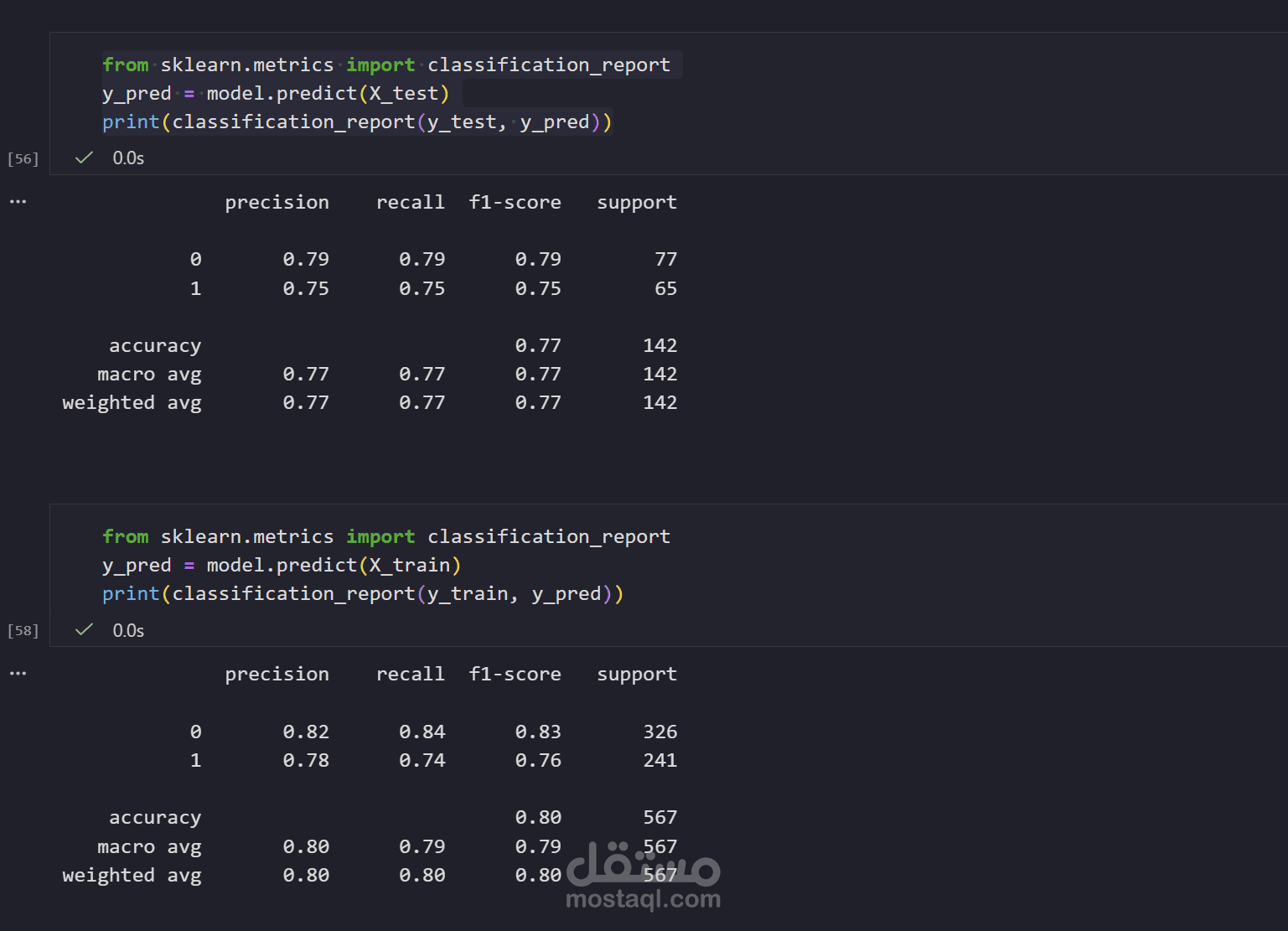
طبعا بقسم ال data ل Train , Test ودرب الموديل على الداتا وبعدين اشوف اقارن ال predict بال actual عشان احسب ال accuracy
ال accuracy طلعت ب %77 على ال test و %80 على ال train