تصنيف مرتبات الأشخاص
تفاصيل العمل


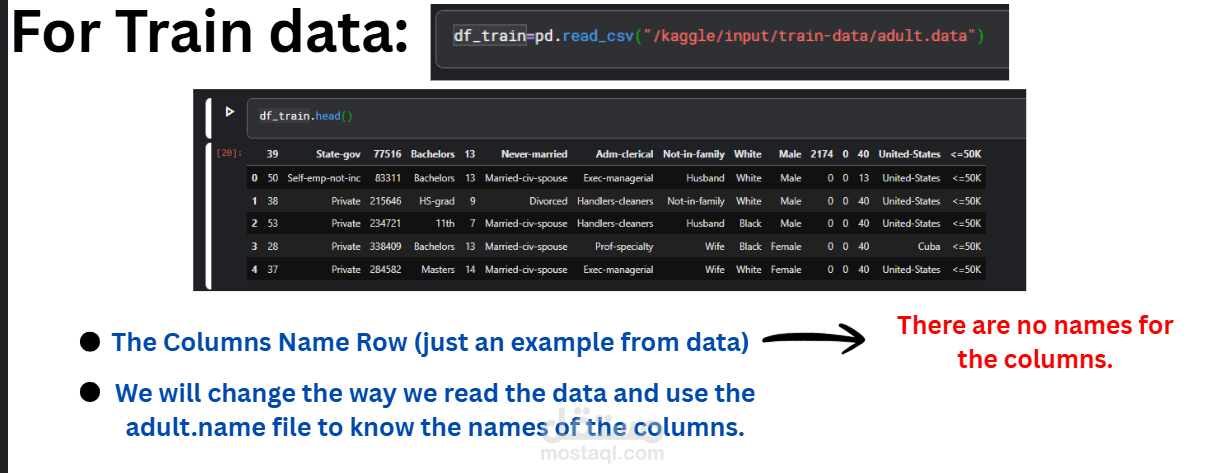
يركز هذا المشروع على بناء نموذج تعلم آلة للتصنيف (Machine Learning Classification) للتنبؤ بما إذا كان دخل الفرد السنوي يتجاوز 50,000 دولار أم لا، اعتمادًا على مجموعة من الخصائص الديموغرافية والمهنية مثل العمر، مستوى التعليم، المهنة، الحالة الاجتماعية، عدد ساعات العمل الأسبوعية، وغيرها من المتغيرات المؤثرة.
تمت صياغة المشكلة على أنها مشكلة تصنيف ثنائي (Binary Classification)، حيث يتعلم النموذج الأنماط الموجودة في البيانات المنظمة لتمييز الأفراد الذين يبلغ دخلهم 50 ألف دولار أو أقل عن أولئك الذين يتجاوز دخلهم 50 ألف دولار سنويًا.
مراحل تنفيذ المشروع
مر المشروع بعدة مراحل أساسية:
1. فهم البيانات (Data Understanding)
تمت دراسة هيكل البيانات والتعرف على أنواع المتغيرات المختلفة (عددية وفئوية) وفهم طبيعة كل خاصية وتأثيرها المحتمل على متغير الدخل.
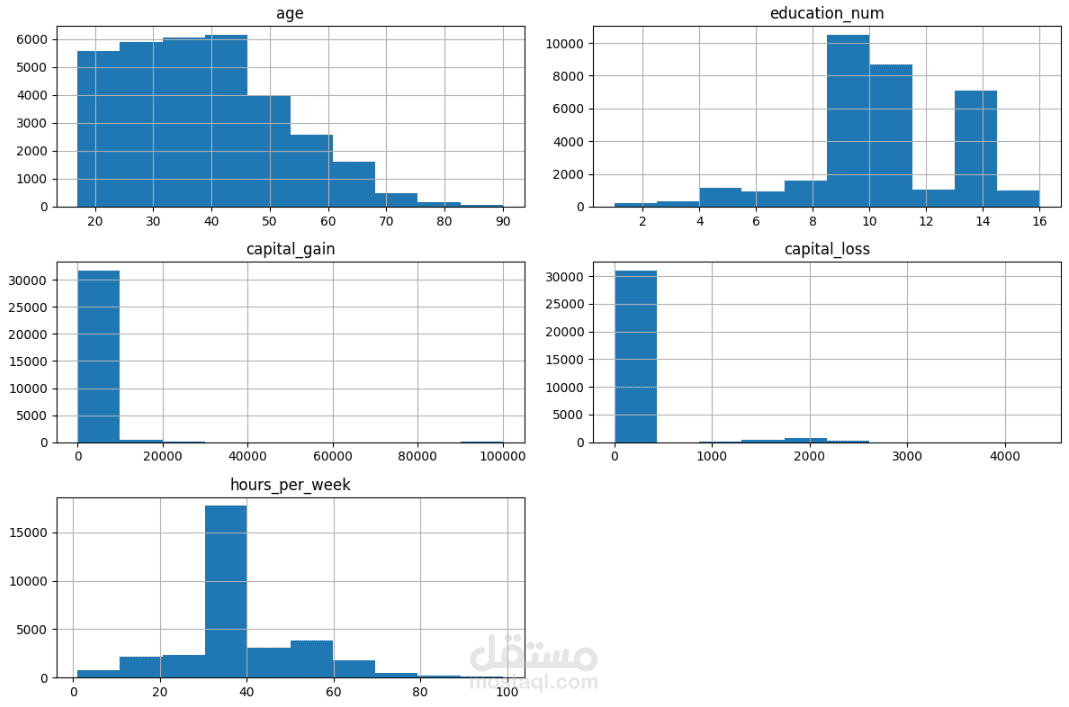
2. تحليل البيانات الاستكشافي (Exploratory Data Analysis - EDA)
تم استخدام الرسوم البيانية والإحصائيات الوصفية لاكتشاف الأنماط والعلاقات بين المتغيرات المختلفة، مثل العلاقة بين مستوى التعليم والدخل أو بين عدد ساعات العمل والدخل.
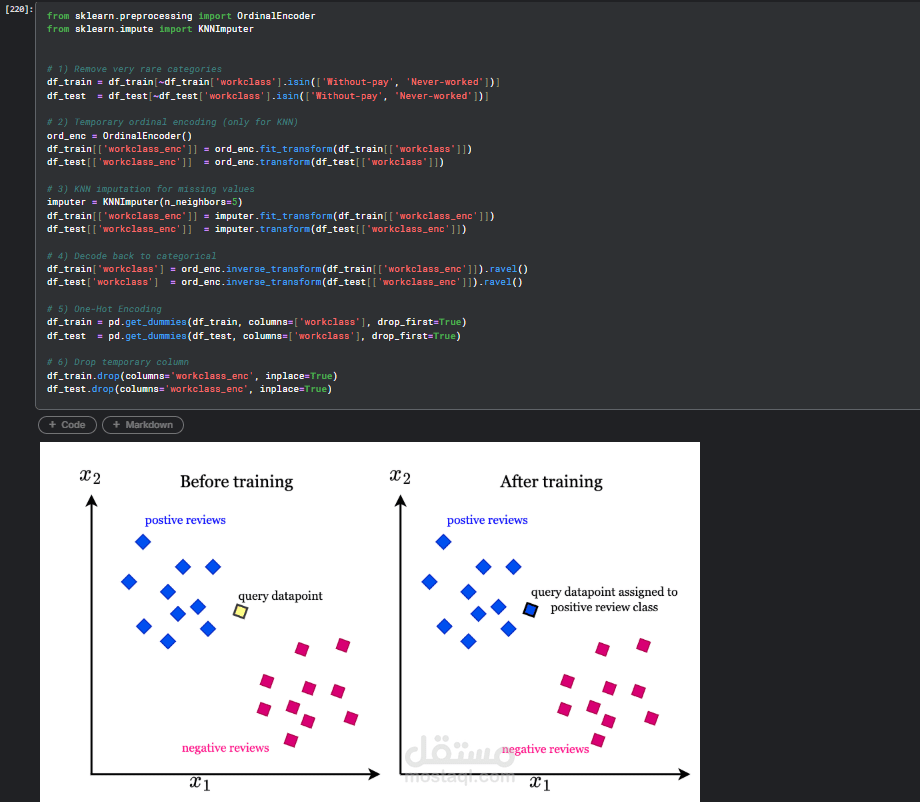
3. معالجة البيانات (Data Preprocessing)
شملت هذه المرحلة عدة خطوات مهمة، مثل:
التعامل مع القيم المفقودة
تحويل المتغيرات الفئوية (Categorical Variables) إلى قيم رقمية باستخدام Encoding
تقييس البيانات (Feature Scaling) للمتغيرات العددية
تقسيم البيانات إلى Training Set و Test Set
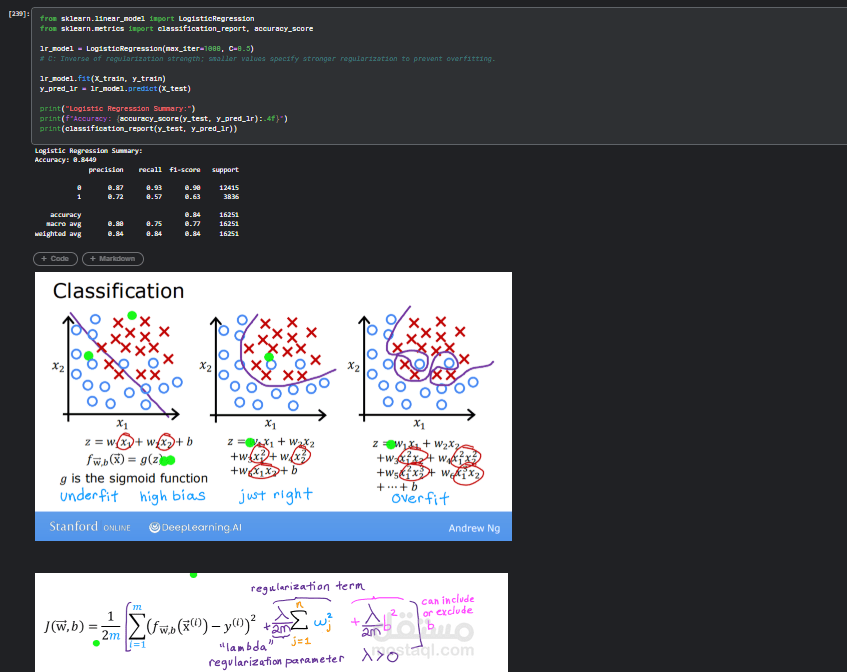
4. بناء النماذج (Model Training)
تم تدريب عدة خوارزميات تصنيف مختلفة لمقارنة أدائها، مثل:
Logistic Regression
Decision Tree
Random Forest
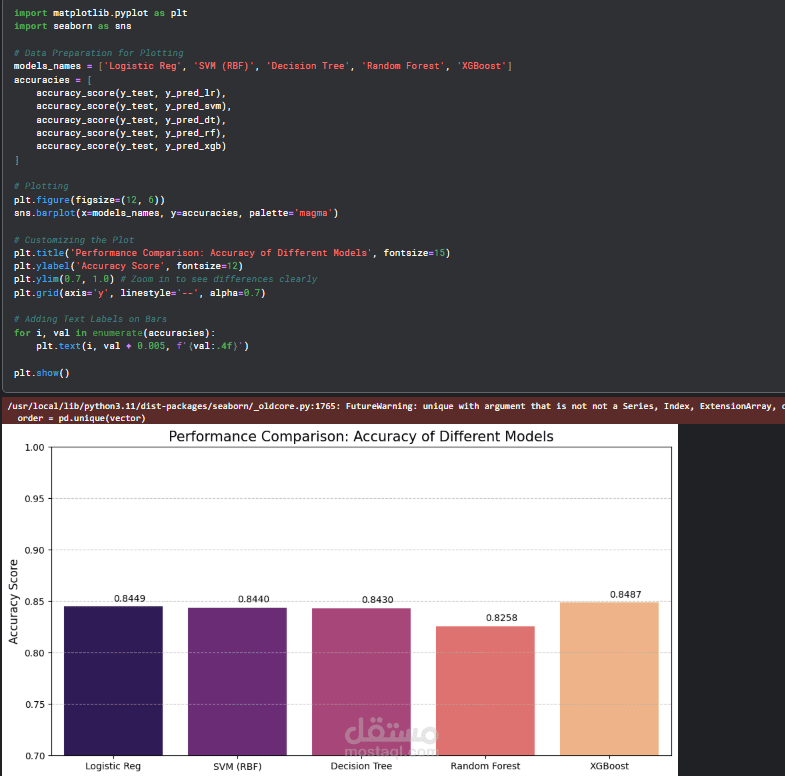
5. تقييم أداء النماذج (Model Evaluation)
تم تقييم النماذج باستخدام مجموعة من مقاييس الأداء الخاصة بمشكلات التصنيف، مثل:
Accuracy
Precision
Recall
F1-score
كما تم استخدام Confusion Matrix لفهم أداء النموذج بشكل أعمق.
6. تحليل النتائج (Model Interpretation)
تم تحليل النتائج لتحديد أكثر العوامل تأثيرًا على مستوى الدخل، حيث تبين أن مستوى التعليم، نوع المهنة، وعدد ساعات العمل الأسبوعية من أهم العوامل المؤثرة.