تحليل و توقع أداء الطلاب و تقسيم العملاء
تفاصيل العمل
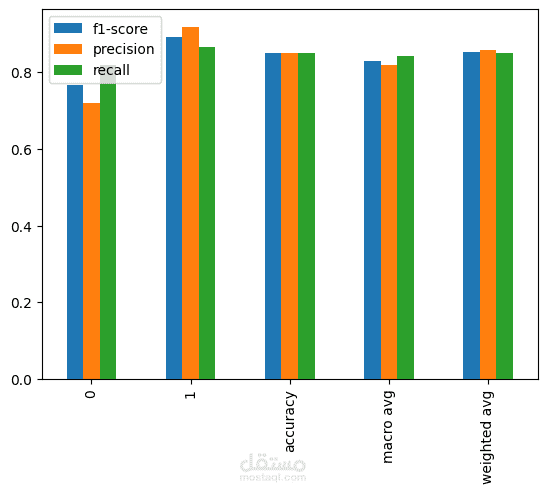
تم تنفيذ تحليل بيانات شامل لقياس وفهم العوامل المؤثرة على أداء الطلاب، بدايةً باستكشاف مبدئي للبيانات لفهم طبيعتها وجودتها، وتحليل التوزيعات واكتشاف القيم الشاذة، واستخدام التصور البياني لاستخلاص أنماط وعلاقات واضحة داخل البيانات.
بعد مرحلة التحليل الاستكشافي، تم بناء نماذج تنبؤية لتوقّع مستوى أداء الطلاب، مع مراعاة عدم توازن المتغير المستهدف، لذلك لم يتم الاعتماد على الدقة العامة فقط، بل تم تقييم النماذج باستخدام مقاييس أكثر تعبيرًا مثل الاستدعاء، الدقة التنبؤية، والمتوسط التوافقي بينهما لضمان تقييم عادل وواقعي للأداء.
تمت مقارنة أكثر من نموذج، وتحليل نتائج كل نموذج لفهم نقاط القوة والضعف، واختيار النموذج الأكثر توازنًا وقدرة على التعميم، مع تفسير النتائج بشكل واضح يخدم الهدف التعليمي للمشروع.
العمل قدّم رؤى عملية تساعد على:
تحديد الطلاب المعرّضين لانخفاض الأداء مبكرًا
فهم العوامل الأكثر تأثيرًا على النتائج الدراسية
دعم القرارات التعليمية بأسلوب مبني على البيانات
وصف مشروع (تقسيم العملاء):
قمت بتنفيذ مشروع تحليل بيانات متكامل يهدف إلى تقسيم العملاء (Customer Segmentation) باستخدام تقنيات التعلم غير المُراقب.
بدأت بمرحلة استكشاف البيانات (EDA) لفهم الأنماط والعلاقات داخل البيانات من خلال التحليل البصري والإحصائي.
تم بعد ذلك تنفيذ عمليات تنظيف البيانات باحترافية شملت:
معالجة القيم المفقودة
استخدام Regular Expressions لتنظيف النصوص
إزالة القيم الشاذة (Outliers)
تنفيذ Feature Engineering لاستخراج خصائص أكثر تعبيرًا
تطبيق Encoding مناسب لكل عمود حسب طبيعته
عمل Scaling لتوحيد نطاق القيم
ثم قمت باستخدام PCA لتقليل الأبعاد مع الحفاظ على أكبر قدر من المعلومات، مما ساعد على تحسين كفاءة النماذج.
في مرحلة النمذجة، تم تطبيق خوارزميات:
K-Means
Agglomerative Clustering
وتم تقييم الأداء باستخدام Silhouette Score، حيث حقق النموذج أفضل نتيجة وصلت إلى 0.97 مما يدل على جودة الفصل بين المجموعات.