Speech to text
تفاصيل العمل

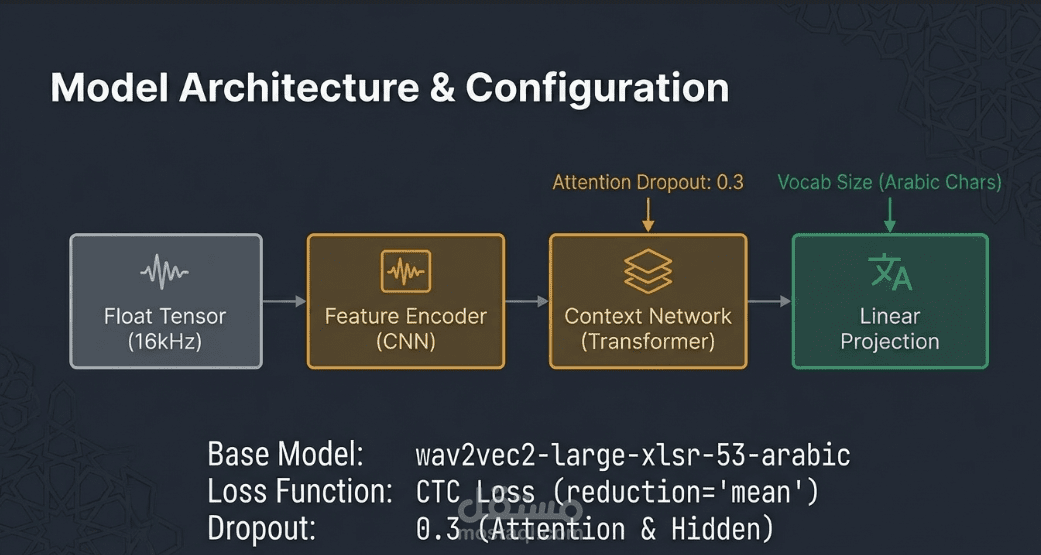
نوع العمل: يتمثل هذا المشروع في ضبط دقيق لنموذج Wav2Vec2 (تحديداً النسخة "wav2vec2-large-xlsr-53-arabic") المتخصص في التعرف الآلي على الكلام (ASR) للقرآن الكريم باللغة العربية. يهدف العمل إلى بناء نظام ذكاء اصطناعي قادر على تحويل التلاوات الصوتية إلى نصوص مكتوبة بدقة عالية عبر تدريب النموذج على بيانات قرآنية موثقة.
ميزات العمل:
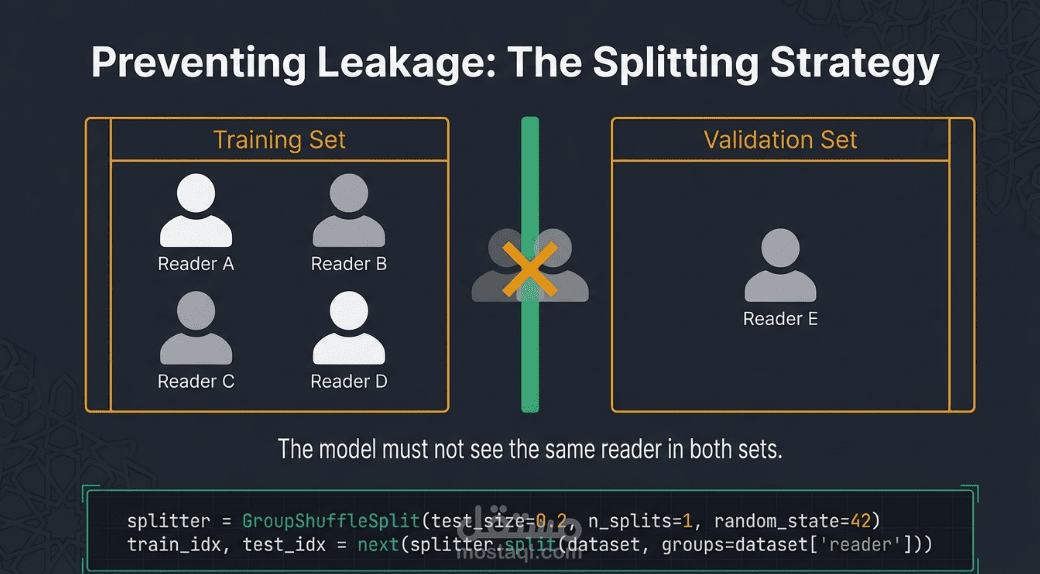
• التعميم عبر القراء: يتم تقسيم البيانات باستخدام تقنية GroupShuffleSplit بناءً على هوية القارئ، وهذا يضمن اختبار النموذج على أصوات قراء لم يسمعهم أبداً أثناء التدريب، مما يعزز من قدرته على العمل مع مختلف الأصوات
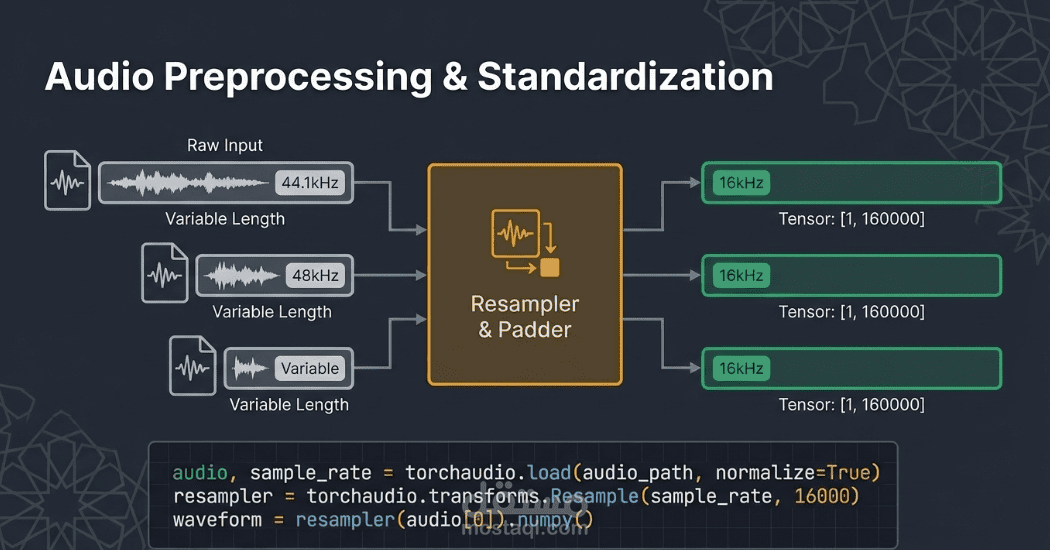
• المعالجة الصوتية القياسية: تحويل كافة الملفات الصوتية إلى تردد 16 كيلو هرتز (Resampling) لضمان توافقها التام مع متطلبات النموذج العالمي.
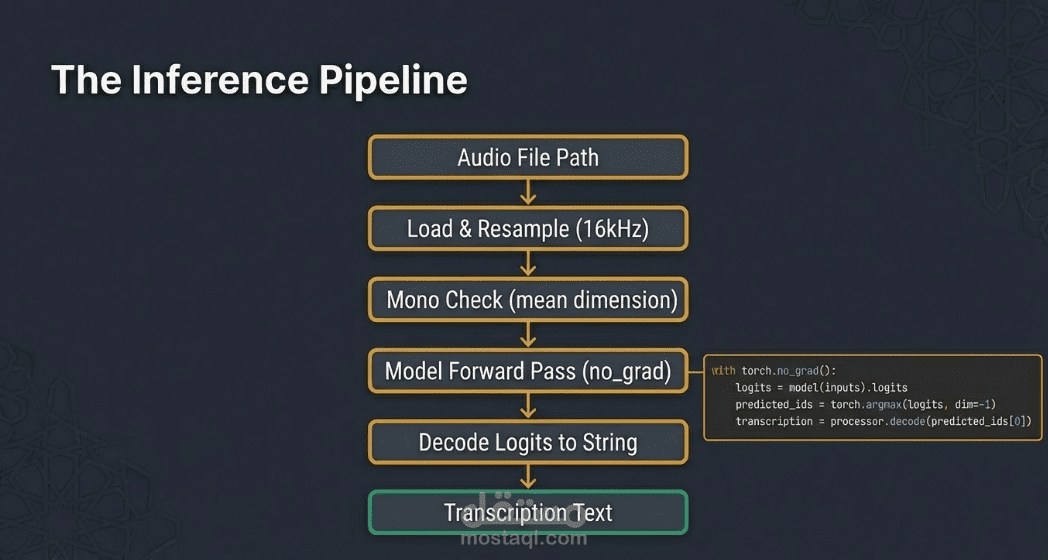
• المعالجة المسبقة (Preprocessing): استخدام Wav2Vec2Processor لتحويل الموجات الصوتية إلى قيم رقمية وتشفير النصوص المقابلة لها مع معالجة الحشو (Padding) لتوحيد أطوال المدخلات.
عملية التدريب: استخدام نظام Trainer من مكتبة Hugging Face لتنفيذ التدريب على مدار 20 دورة (epochs)، مع مراقبة معدل خطأ الكلمات (WER) كمعيار أساسي للجودة .
.